OpenAI’s technology explained

OpenAI was created as a nonprofit in 2015 to ensure that artificial general intelligence—in short, AI that’s at least as smart as a person—benefits all of humanity. We research, develop, and release cutting edge AI technology as well as tools and best practices for the safety, alignment, and governance of AI. OpenAI is still governed by our non-profit today: We put our mission ahead of profits, we limit financial returns to employees and investors, and we will return future profits above the limit to our non-profit. This unique corporate structure gives us different incentives than other technology companies. Our goal is not to sell the most of anything, but to work towards a world where everyone benefits from the social, economic, and technological opportunities of AI.
As part of OpenAI’s mission, we develop leading foundation models and make their capabilities available in safe and beneficial ways to people around the world(opens in a new window). There are two main ways that people can access our models:
- ChatGPT is an app that enables people to interact with our models in a conversational manner. Users can ask our language models to analyze or write text or code, or ask our image models to draw images based on a text description. ChatGPT is available for free to all users at chatgpt.com(opens in a new window). Users can sign up for a premium monthly subscription that makes additional features and capabilities available, and we offer an enterprise version for businesses to purchase.
- Our API (Application Programming Interface) allows developers to integrate the capabilities and benefits of our models into their own applications. Thousands of organizations including Duolingo, Spotify, and Morgan Stanley are building new features, applications, and businesses using our API. A Danish company called Be My Eyes uses our API to help blind and low vision users upload and ask questions about images, helping them better navigate physical environments and gain more independence. Our API is available at platform.openai.com(opens in a new window) and developers pay for API access based on how much they use it.
We make ChatGPT and our API available in connection with extensive safety measures, as further detailed below. We also make certain models, such as our speech-to-text model Whisper and our image understanding model called CLIP, available on an open source basis after evaluating the potential risks of such releases.
We intend to continue to make ChatGPT available for free and will earn revenue from users and businesses that choose to pay for premium services. Given the high costs of developing and offering large scale foundation models, our organization is not profitable and does not expect to be profitable for the near future—our goal continues to be to make AI benefits broadly and safely available to the world.
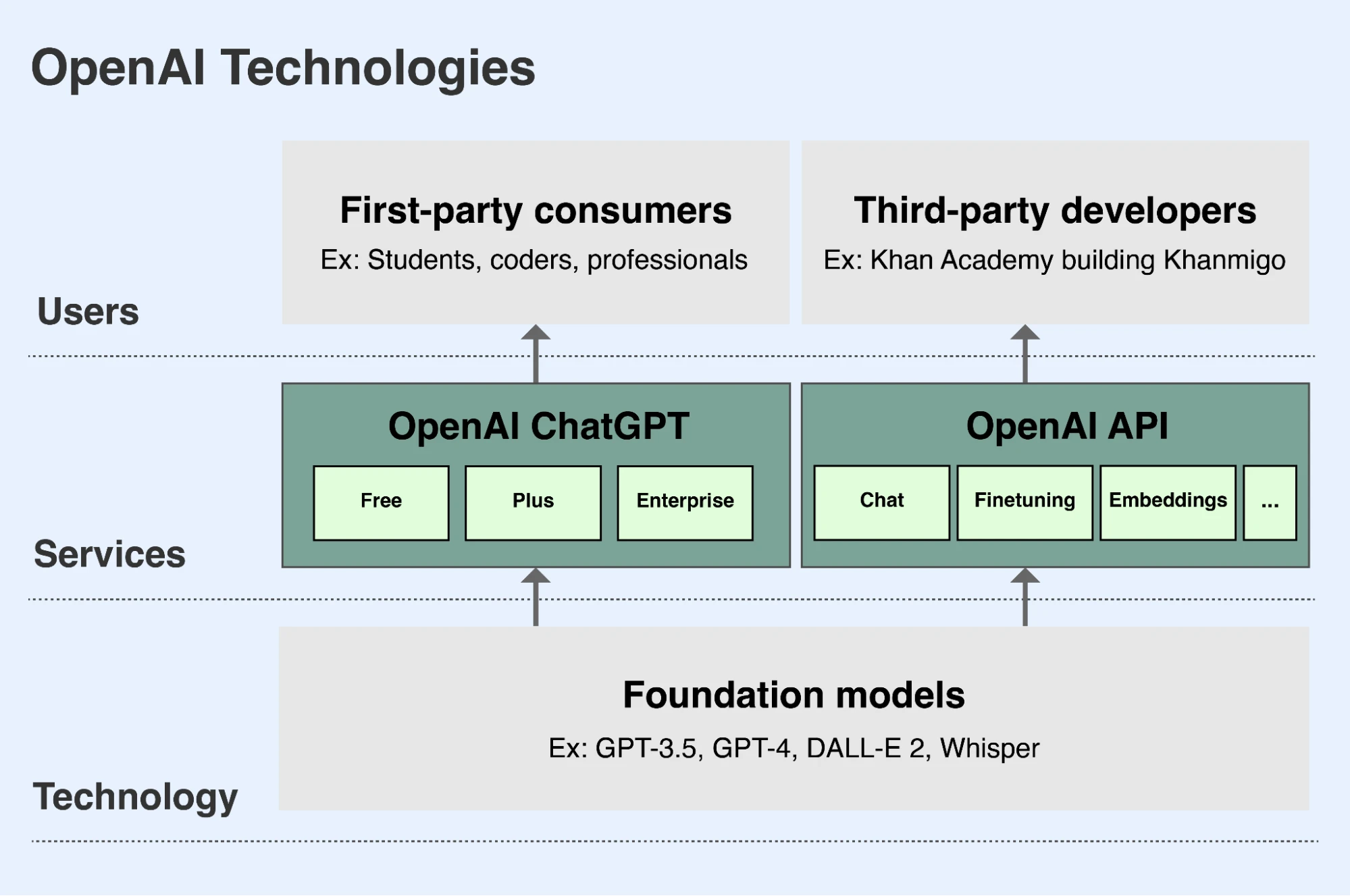
OpenAI makes access to our leading foundation models available primarily through ChatGPT and our API.
Developing an advanced language model like GPT‑4 requires (1) teaching it intelligence, such as the ability to predict, reason, and solve problems, as well as (2) aligning it to human values and preferences. The former is done in a process called “pre-training”, which involves showing the model a vast amount of human knowledge over months. To then incorporate human choice into the model, we use a second step, called “post-training”, where we make the model safer and more usable.
Pre-training teaches language to a model, by showing the model a wide range of text, and having it try to predict the word that comes next in each of a huge range of sequences. This requires an enormous amount of computation, as models review, analyze, and learn from trillions of words. We build supercomputers to train our base models, and training a single new base model can occupy a supercomputer for months. Through this extensive process, the model not only learns how words fit together grammatically, but also how words work together to form higher-level ideas, and ultimately how sequences of words form structured thoughts or pose coherent problems. For example, when we think of the word “cloud”, we might also think of related words like “sky” and “rain”; when given a sentence like “The secret to happiness is”, we might think of various philosophical ideas. In gaining fluency with predicting the next word, the model thereby learns concepts and the building blocks of intelligence.
The output of this process—a base model—has the remarkable ability to solve novel problems unseen in its training data, even in a wide range of languages. However, the base model alone is not ready for use. Base models are powerful and flexible. They are intelligent and surprising, but are not necessarily useful or safe.
A base model is not easy to talk to: For example, if you ask the GPT‑4 base model to “write a story about a princess…”, it usually won’t write a story. Instead, it will extend your statement, predicting how it continues. It might output, for instance: “…about a princess who loves horses.” A base model also does not have safeguards to prevent it from outputting unwanted content, such as hateful or violent material. While we filter our pre-training dataset for unwanted content, this mitigation is too imprecise to make targeted changes to the model, and can even backfire if it prevents the model from understanding what not to say or do. In order to instill human values into the models, including what is useful and what is appropriate to say, we research and develop alignment and safety techniques for a process we call post-training.
Post-training is how we incorporate human choice into our models, and transform them into useful, effective, and safer tools. We teach the model to respond in ways that people find more useful, and to decline to respond in ways that we believe would be harmful. Post-training requires significant investment in research, personnel, design choices, and data creation. This is an active area of research and investment for OpenAI. We also believe that many people beyond our company will be part of the work of creating data and making design decisions to reflect human values.
Post-training results in targeted changes to the model, using relatively small and carefully engineered datasets that represent ideal behavior. We do this by having people write sample answers and rate answers provided by the model, and provide those samples and ratings back to the model in follow-up training processes. We pioneered these techniques, including reinforcement learning from human feedback (RLHF), which has now become industry standard. We use RLHF to teach the model to follow instructions, to decrease the likelihood of it returning inaccurate content, and to add safety features.
Prior to publicly releasing GPT‑4, we spent 6 months iterating on post-training. During this time, we developed techniques to teach our models to refuse to respond to requests that we believe may lead to potential harm. For example, if asked for instructions on how to build a bomb, the model will refuse to respond. We made GPT‑4 82% less likely to respond to requests for disallowed content based on our internal evaluations, compared to the prior generation model GPT‑3.5. We also used this time to increase the likelihood it produces factual responses by 40%, teach it to respond in a conversational way, and improve its performance on low-resourced languages, for instance in partnership with Iceland.
We continue to develop post-training techniques(opens in a new window) to better reflect human choice in our models. For example, some of our approaches empower people to describe the rules that a system should follow, rather than having to grade examples of better or worse behavior.
In addition to the post-training we do ourselves, we also offer customers the ability to “fine-tune” our models to accomplish their specific goals, such as writing software code in their proprietary languages, teaching it industry specific knowledge, or aligning its tone to their brand. Customers do this by preparing data that demonstrates the behavior they’re seeking to achieve and submitting it for additional post-training via our API. Assuming the data passes our safety checks, we then make the resulting fine-tuned model available solely to that customer. Similarly to other API traffic, we use our monitoring and detection systems described below to help detect if fine-tuned models violate our usage policies.
In addition to safety through post-training, we conduct rigorous testing, engage external experts for feedback, build and reinforce safety and monitoring systems, and provide resources to help people use our models responsibly. This holistic approach to safety is what allows us to implement and enforce our usage policy that prohibits using our models in ways that may cause harm, such as for generation of hateful, harassing, or violent content, for political campaigning, or for generation of malware.
Red-teaming and evaluations. We evaluate each major new model for safety risks and potential societal harms like bias and discrimination. We perform internal and external red-teaming, where we test the model for risks internally and provide early access to experts from a range of industries to help probe the systems to map and evaluate risks. We use these evaluations to further guide the development and refinement of our models and safety systems, and publish our findings publicly.
Safety monitoring systems. We build and implement monitoring systems that help detect unwanted content and complement human review of specific incidents. When a content violation is detected by these systems, we may take a variety of actions including refusing to respond, flagging the incident for human review, or in extreme cases, suspending a user. Content classifiers are powered by fine-tuned language models and we continue to research how to increase their coverage, efficiency, and accuracy, most recently exploring using GPT‑4 to develop moderation systems.
Tools for users. We develop documentation and tools for our users and the developers that build applications on top of our models to empower them to use AI safely. Prior to releasing new frontier systems, we publish a report describing the model or system capabilities, limitations, and domains of appropriate and inappropriate use (for instance, the system cards for GPT‑4(opens in a new window) and GPT‑4V). We make a free Moderations API(opens in a new window) available so users can enforce their own usage policies. And we publish research(opens in a new window) on our safety systems.
Learning from feedback. We believe that learning from and responding to feedback is a critical component of building safe AI systems over time and delivering on our mission. We continuously improve our model outputs, moderation systems, and usage policies based on user input and feedback. We also engage in continuous stakeholder conversations about the most beneficial adoption of and adaptation to AI technology.
Artificial intelligence is a branch of computer science whose goal is to create computing systems that can behave in a way typically associated with human intelligence. Examples include software that can play games like chess, cars that can drive themselves, and chatbots that can simulate humanlike conversation.
Machine learning is an approach to artificial intelligence where computer systems can learn to accomplish tasks based on information or experimentation, rather than being programmed step by step. For example, a machine learning system could learn to draw a picture of a cat by viewing different pictures of cats and learning characteristics of those pictures, instead of being given line by line instructions on what cats look like. Or, a system could learn to play a video game by experimenting and being rewarded for successful attempts, rather than being provided the game rules and instructions on how to complete the game.
Models are computer programs that are developed using artificial intelligence and machine learning techniques. The most common models are programs that analyze data in order to make future predictions based on that data. For example, a model might be developed to analyze historical purchases made by shoppers in order to recommend purchases to a future shopper.
Foundation models are AI models that are developed using large amounts of computational power to learn from a large amount of data, in order to perform a broad range of tasks related to that data. For example, a language model that is developed using a large amount of text can then be used to analyze, write, and answer questions about text.
The fields of artificial intelligence and machine learning are advancing rapidly, so these definitions will continue to evolve over time.