OpenAI のテクノロジーについての解説

OpenAI は2015年に、汎用人工知能(端的に言えば、人間と同等の賢さを持つ AI)が、全人類に利益をもたらせるようにすることを目的として、非営利団体として設立されました。AI の安全性、アライメント、ガバナンスのためのツールとベストプラクティスに加え、最先端の AI テクノロジーを研究、開発、リリースしています。OpenAI は現在も非営利団体として運営されています。よって、利益よりも使命を優先し、従業員と投資家への金銭的リターンを制限して、今後の利益を当非営利団体の枠を超えて還元する予定にしています。他にはない、この企業構造のおかげで、当社は他のテクノロジー企業とは異なるインセンティブを与えられています。私たちは、製品をできるだけ多く売ることではなく、AI がもたらす社会的、経済的、技術的な機会から誰もが恩恵を受けられる世界を目指しています。
OpenAI のミッションの一環として、私たちは先進的な基盤モデルを開発し、その機能を世界中の人々(新しいウィンドウで開く)に安全かつ有益な形で届けてまいります。当社のモデルを利用いただく主な方法は2つあります。
- ChatGPT は、ユーザーが会話形式でモデルと対話できるアプリです。ユーザーは、言語モデルに、テキストやコードを解析したり書いたりするよう依頼したり、画像モデルに、テキストの記述に基づいて画像を描くよう依頼したりすることができます。ChatGPT は、chatgpt.com(新しいウィンドウで開く) から無料ですべてのユーザーにご利用いただけます。ユーザーは、追加機能や能力を利用できるプレミアム月額サブスクリプションへのサインアップが可能です。また、企業向けにエンタープライズ版を用意しています。
- 当社の API(アプリケーションプログラミングインターフェース)を使うことで、開発者は、当社モデルの機能と利点を自社のアプリケーションに統合できるようになります。Duolingo、Spotify、Morgan Stanley といった何千もの組織が、当社の API を使って新しい特徴、アプリケーション、ビジネスを構築しています。Be My Eyes というデンマークの企業は、当社の API を使用して、目の不自由なユーザーが画像をアップロードしたり、画像について質問したりする手助けをして、ユーザーが物理的な環境をより快適にナビゲートし、より自立できるよう支援しています。当社の API は platform.openai.com(新しいウィンドウで開く) よりご利用になれます。開発者には API の使用量に応じて API アクセス料をお支払いいただきます。
私たちは ChatGPT と API を、以下に詳述しているとおり、広範な安全性への対策と併せて利用いただけるようにしています。また、音声テキスト変換モデルの Whisper や、画像認識モデルの CLIP など特定のモデルについては、リリースの潜在的なリスクを評価した上で、オープンソースベースで公開しています。
私たちは、ChatGPT を引き続き無料で提供し、プレミアムサービスに料金を支払うことにしたユーザーや企業から収益を得るつもりです。大規模な基盤モデルの開発と提供には高いコストがかかるため、当社は多くの収益は得ておらず、近い将来も利益を上げる見込みがありませんが、引き続き、AI の恩恵を広く安全に世界に提供することを目指してまいります。
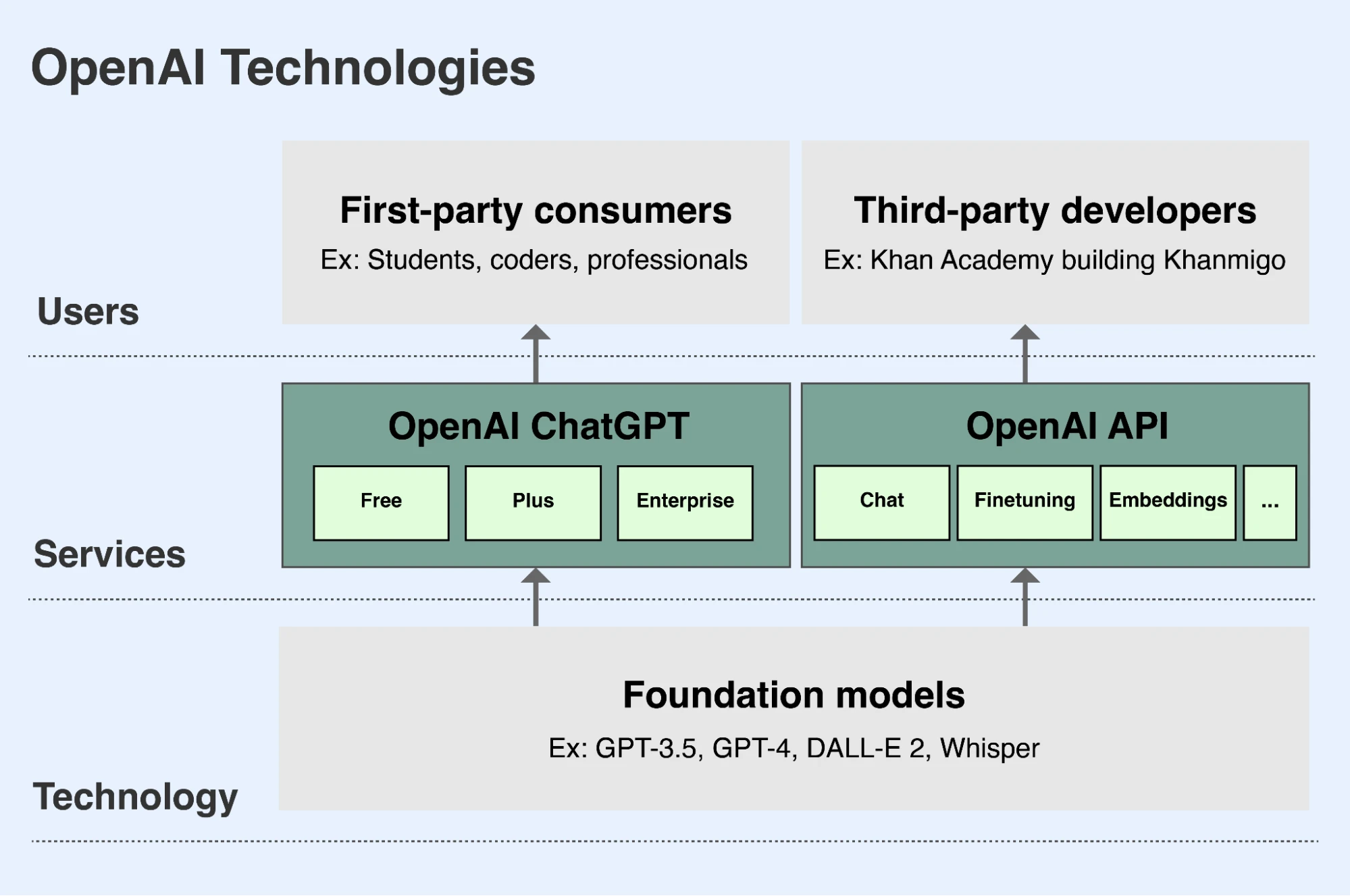
OpenAI は、主に ChatGPT と API を通じて、主要な基盤モデルへのアクセスを提供しています。
GPT‑4 のような高度な言語モデルの開発には、(1)予測、論理的思考、問題解決といった知能を教えることに加えて、(2)人間の価値観や好みに合わせることが必要となります。前者は「事前学習」と呼ばれるプロセスで行われ、数か月にわたって人間の膨大な知識をモデルに提示するものです。その後、人間の選択をモデルに組み込むため、「事後学習」と呼ばれる第二のステップを使い、モデルをより安全で使いやすいものにします。
事前学習では、モデルに幅広いテキストを示して、膨大なシーケンスのそれぞれで次に来る単語を予測させることにより、モデルに言語を教えます。これには膨大な量の計算が必要で、モデルは何兆という単語を見直し、分析し、学習します。ベースモデルの学習にスーパーコンピューターを構築し、単一の新しいベースモデルを学習させるのに数か月を費やすこともあります。この広範なプロセスを通じて、モデルは、単語が文法的にどのように組み合わされているかだけではなく、単語がどのように組み合わされて、より高度な考えを形成するのか、そして最終的には、単語の並び方でどのように構造化された思考が形成されるのか、あるいは首尾一貫した問題を提起するのかを学習します。たとえば、「雲」という単語を考えた際、私たちの心には「空」や「雨」といった関連する単語も浮かぶかもしれません。また、「幸せの秘訣は」といった文章が与えられれば、さまざまな哲学的なアイデアが思い浮かぶかもしれません。次の単語をよどみなく予測できるようになることで、モデルは概念、そして、知能の構成要素を学習します。
このプロセスの出力であるベースモデルは、学習データにはない新しい問題を、さまざまな言語でも解くことができるという驚くべき能力を備えています。しかし、ベースモデルだけでは十分に用をなしません。ベースモデルはパワフルで柔軟です。知的で驚くべきものですが、必ずしも便利で安全なものとは言えません。
ベースモデルに語りかけるのは簡単ではありません。たとえば、GPT‑4 のベースモデルに「お姫様についての物語を書いてください」と頼んでも、通常は書いてくれません。代わりに、あなたの入力した文を拡張して、その続きを予測します。たとえば、 「馬が大好きなお姫様の話」といった具合に出力するのです。ベースモデルは、憎悪を含むものや暴力的なものなど、望ましくないコンテンツを出力しないようにする安全措置も持ち合わせていません。事前学習データセットで不要なコンテンツをフィルタリングしていますが、この緩和策は、モデルに的を絞った変更を加えるにはあまりに不正確で、モデルが何を言ったりしたりすべきでないか理解できない場合、逆効果となる可能性さえあります。何が有用で、どう応えるのが適切か、人間の価値観をモデルに植え付けるために、当社は事後学習と呼ばれるプロセスのためのアライメントと安全性のテクニックを研究、開発しています。
事後学習とは、人間の行う選択をモデルに取り入れ、それを有用で、効果的で、安全なツールに変える方法です。人々がより有用だと思う方法で対応し、有害だと思われる形で反応することを拒否するようにモデルを教育します。事後学習は、研究、人材、デザインの選択、データ作成における多大な投資を必要とします。これは、OpenAI が積極的に研究と投資を行っている分野です。また、社外の多くの方の協力を得て、データを作成し、人間の価値観を反映させるためのデザイン決定を行う作業を進めるつもりです。
事後学習では、理想的な行動を表す比較的小規模で慎重に設計されたデータセットを使用して、モデルにターゲットを絞った変更を行います。人々に回答例を書いてもらったり、モデルが提供する回答を評価してもらったりすることで、これを行い、フォローアップの学習プロセスにおいて、それらの回答例や評価をモデルに提供し直します。当社は、現在では業界標準となっている人間のフィードバックによる強化学習(RLHF)など、こうしたテクニックのパイオニアとなってきました。RLHF を用いて、モデルが指示に従うように訓練し、不正確なコンテンツを返す割合を減らし、安全機能を追加しています。
GPT‑4 の一般公開に先駆け、私たちは6か月間を事後学習のイテレーションに費やしました。この間、潜在的に有害になると考えられる要求への応答を拒否するよう、モデルに教えるテクニックを開発しました。たとえば、爆弾の作り方を要求された場合、モデルは回答を拒否します。GPT‑4 では、前世代のモデル GPT‑3.5 と比較して、当社の内部評価基準で許可されていない内容の要求に応答する可能性は、82%低くなっています。また、この期間を用いて、事実に基づいた応答を生成する可能性を40%増加させ、会話形式で応答するよう訓練し、たとえばアイスランドとの提携などにより、リソースの少ない言語でのパフォーマンスを向上させました。
今後も人間による選択をさらにモデルに反映させられるよう、事後学習の技術開発(新しいウィンドウで開く)を続けていきます。たとえば、当社のアプローチでは、動作の良し悪しの例を評価するのではなく、システムが従うべきルールを記述できるようにしています。
当社が行う事後学習に加えて、独自の言語でソフトウェアコードを記述する、業種特有の知識を教える、ブランドに合わせてトーンを調整するなど、特定の目標を達成するために当社モデルを「ファインチューニング」する機能もお客様に提供しています。達成したい動作を示すデータを準備し、それを当社の API 経由で追加の事後学習のために送信することで、微調整を行っていただけます。データが当社の安全性チェックに合格すると、その結果得られたファインチューニングモデルを、そのお客様のみが利用できるようになります。他の API トラフィックと同様、ファインチューニングされたモデルが当社の利用ポリシーに違反していないか検出するために、当社では後述するモニタリングと検出システムを使用しています。
事後学習での安全性の確保に加え、当社は厳格なテストを実施し、外部の専門家の意見をを求め、安全性および監視システムを構築、強化して、皆様に当社のモデルを責任を持ってご利用いただくためのリソースを提供しています。このように安全性に対する総合的なアプローチをとることで、悪意のある、脅迫的、暴力的なコンテンツの生成、政治的な運動、マルウェアの生成など、害を及ぼす可能性のある形で当社のモデルが使用されることを禁ずる利用ポリシーを実施、強化できるようにしています。
レッドチーミングと評価。当社は、安全上のリスクや、偏見や差別といった潜在的に社会に危害を及ぼすものについて、主要な新モデルをそれぞれ評価しています。社内および社外レッドチーミングを実施しており、社内でモデルのリスクをテストするとともに、さまざまな業種の専門家にいち早く連絡をとれるようにすることで、リスクのマッピングおよび評価を行うシステムの調査に役立てます。私たちはこうした評価を活用して、モデルおよび安全性システムの開発と改良のさらなる指針とし、その結果を公表しています。
安全性監視システム。当社は、望ましくないコンテンツを検知し、特定のインシデントを人間による調査で補完する監視システムを構築、導入しています。コンテンツ違反がこれらのシステムにより検知された場合、当社は、応答を拒否したり、インシデントを人間による調査のためにフラグ付けしたり、極端な場合にはユーザーによる利用を一時停止するなど、さまざまな措置を講じることがあります。コンテンツの分類機能は、綿密に調整された言語モデルによって実現されており、私たちはその適用範囲、効率性、正確性を向上させる方法の研究を続けています。最近では、GPT‑4 を使用したモデレーションシステムの開発も検討しています。
ユーザー向けツール。私たちは、ユーザーおよび当社モデルを基盤としてアプリケーションを構築する開発者向けに、AIを安全に利用するためのドキュメントとツールを開発しています。新しい最先端システムのリリースに先立ち、モデルやシステムの機能、限界、適切な使用と不適切な使用の領域(たとえば、GPT‑4(新しいウィンドウで開く) と GPT‑4V のシステムカード)についての説明レポートを公開しています。また、ユーザーが独自の利用ポリシーを適用できるよう、Moderations API(新しいウィンドウで開く) を無料で提供しています。さらに、当社の安全システムに関する研究(新しいウィンドウで開く)を公開しています。
フィードバックからの学び。私たちは、フィードバックから学び、それに対応することは、長期的に安全な AI システムを構築し、当社の使命を果たす上で重要な要素であると考えています。当社は、ユーザーからの情報やフィードバックに基づいて、モデルの出力、モデレーションシステム、利用ポリシーを継続的に改善しています。また、AI 技術の最も有益な導入と適応について、継続的に利害関係者と話し合いを行っています。
人工知能とは、一般的には人間の知能と関連付けられるような行動を取ることができるコンピューティングシステムを構築することを目的とする、コンピューターサイエンスの一分野です。これには、チェスなどのゲームができるソフトウェア、自動運転車、人間のような会話をシミュレートできるチャットボットなどがあります。
機械学習とは、人工知能の一手法で、段階的にプログラムされるのではなく、コンピュータシステムが情報や実験に基づいてタスクを達成する方法を学習できるものです。たとえば、猫の絵を描く際に、機械学習システムは猫の外見について行ごとに指示を受けるのではなく、さまざまな猫の絵を見て、その特徴を学習することで、猫の絵を描くことを学びます。あるいは、ゲームのルールや終了方法を指示されるのではなく、試行錯誤し、成功した試みに対して報酬をもらうことで、ビデオゲームのプレイ方法を学習します。
モデルとは、人工知能や機械学習の技術を用いて開発されるコンピュータープログラムです。最も一般的なモデルは、データを分析して、そのデータに基づく将来の予測を行うものです。たとえば、将来の買い物客に購入を勧めるために、買い物客の過去の購買履歴を分析するモデルが開発されることがあります。
基盤モデルは、大量のデータに関連する幅広いタスクを実行するために、大量の計算能力を使用して大量のデータから学習を行う AI モデルです。たとえば、大量のテキストを使用して開発された言語モデルは、テキストの分析、作成、およびテキストに関する質問への回答に使用できます。
人工知能と機械学習の分野は急速に進歩しており、こうした定義は今後も進化し続けるでしょう。