Neu: Codex
Ein Cloud-basierter Software-Engineering-Agent, der viele Aufgaben parallel bearbeiten kann, unterstützt von codex-1. Jetzt für ChatGPT Pro-, Team- und Enterprise-Benutzer verfügbar, bald auch für Plus-Benutzer.
Update vom 3. Juni 2025: Codex ist jetzt für Benutzer von ChatGPT Plus verfügbar. Wir ermöglichen es Benutzern außerdem, Codex während der Aufgabenausführung Internetzugang zu gewähren. Weitere Einzelheiten findest du im Changelog(wird in einem neuen Fenster geöffnet) und in der Dokumentation(wird in einem neuen Fenster geöffnet).
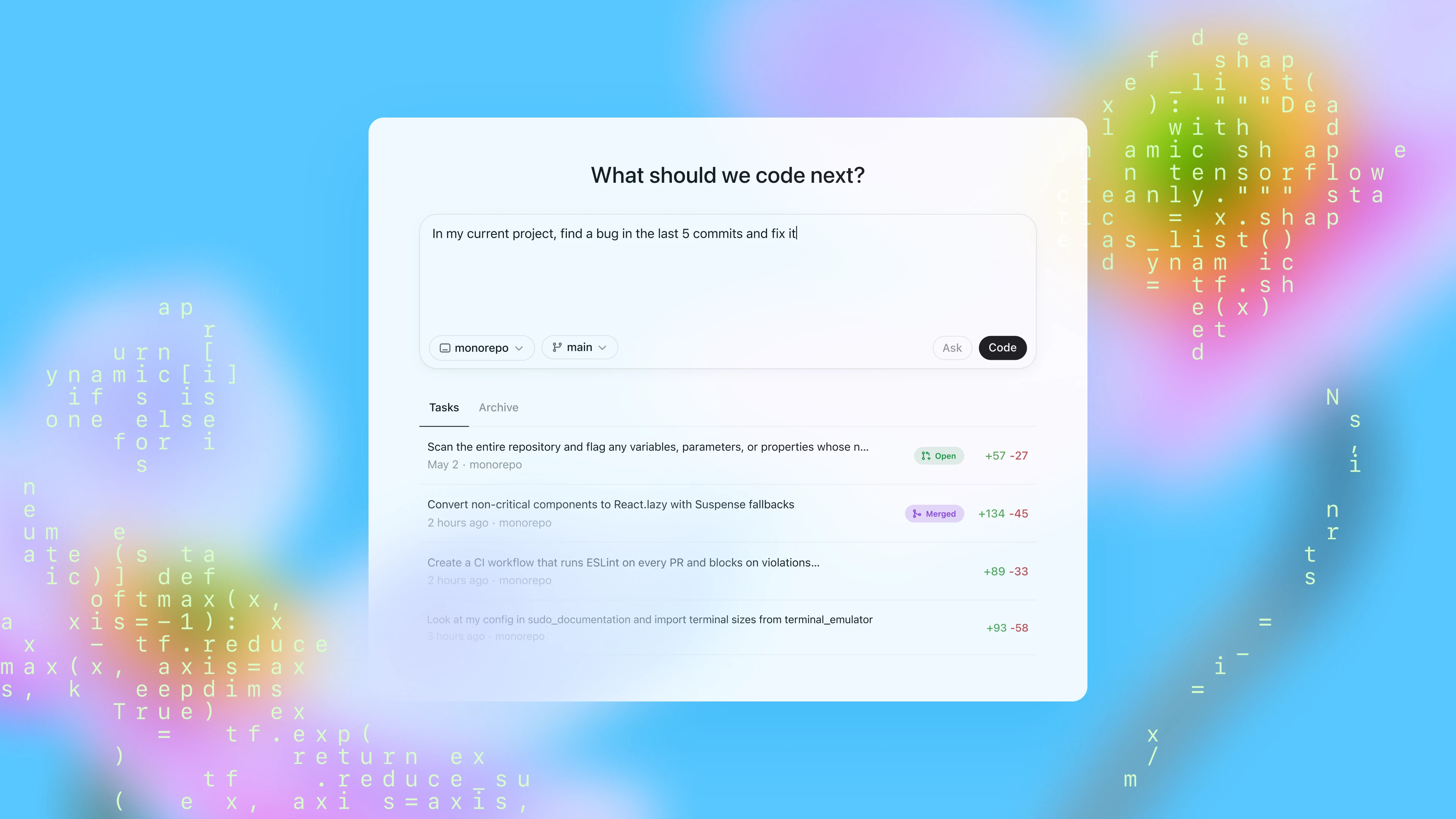
Heute führen wir eine Research-Preview für Codex ein: ein Cloud-basierter Software-Engineering-Agent, der viele Aufgaben parallel bearbeiten kann. Codex kann Aufgaben wie das Schreiben von Funktionen, das Beantworten von Fragen zur Codebasis, die Fehlerbehebung und Vorschläge für Pull Requests zur Überprüfung für dich ausführen. Jede Aufgabe wird in einer eigenen Cloud-Sandbox-Umgebung ausgeführt, in der dein Repository bereits vorhanden ist.
Codex wird von codex-1 betrieben, einer für die Softwareentwicklung optimierten Version von OpenAI o3. Es wurde mithilfe von Reinforcement Learning anhand realer Codierungsaufgaben in verschiedenen Umgebungen trainiert, um Code zu generieren, der den menschlichen Stil und die PR-Präferenzen genau widerspiegelt, Anweisungen präzise befolgt und iterativ Tests ausführen kann, bis ein positives Ergebnis erzielt wird. Wir beginnen heute mit der Einführung von Codex für ChatGPT Pro-, Enterprise- und Team-Benutzer. Der Support für Plus und Edu folgt in Kürze.
Heute kannst du über die Seitenleiste in ChatGPT auf Codex zugreifen und ihm neue Codierungsaufgaben zuweisen, indem du einen Prompt eingibst und auf „Code“ klickst. Wenn du Codex eine Frage zu deiner Codebasis stellen möchtest, klicke auf „Fragen“. Jede Aufgabe wird unabhängig in einer separaten, isolierten Umgebung verarbeitet, in der deine Codebasis bereits vorhanden ist. Codex kann Dateien lesen und bearbeiten sowie Befehle ausführen, darunter Test-Harnische, Lint-Prüfungen und Type Checker. Die Erledigung der Aufgabe dauert je nach Komplexität zwischen 1 und 30 Minuten. Du kannst den Fortschritt von Codex in Echtzeit überwachen.
Sobald Codex eine Aufgabe abgeschlossen hat, werden die Änderungen in der Umgebung übernommen. Codex liefert überprüfbare Beweise für seine Aktionen durch Zitate aus Terminalprotokollen und Test-Outputs, sodass du jeden Schritt der Aufgabenerledigung nachvollziehen kannst. Anschließend kannst du die Ergebnisse überprüfen, weitere Überarbeitungen anfordern, einen GitHub-Pull-Request öffnen oder die Änderungen direkt in deine lokale Umgebung integrieren. Im Produkt kannst du die Codex-Umgebung so konfigurieren, dass sie deiner realen Entwicklungsumgebung möglichst nahe kommt.
Codex kann durch AGENTS.md-Dateien geleitet werden, die in deinem Repository abgelegt sind. Dabei handelt es sich um Textdateien, ähnlich wie README.md, in denen du Codex mitteilen kannst, wie es in deiner Codebasis navigieren soll, welche Befehle zum Testen ausgeführt werden sollen und wie es die Standardverfahren deines Projekts am besten einhält. Wie menschliche Entwickler erbringen Codex-Agenten die beste Leistung, wenn sie über konfigurierte Entwicklungsumgebungen, zuverlässige Test-Setups und eine klare Dokumentation verfügen.
Bei Code-Bewertungen und internen Benchmarks zeigt codex-1 auch ohne AGENTS.md-Dateien oder benutzerdefiniertes Scaffolding eine starke Leistung.
23 von SWE-Bench verifizierte Beispiele, die auf unserer internen Infrastruktur nicht ausgeführt werden konnten, wurden ausgeschlossen. Codex-1 wurde mit einer maximalen Kontextlänge von 192.000 Token und mittlerem „Reasoning-Aufwand“ getestet. Dies ist die Einstellung, die heute im Produkt verfügbar sein wird. Details zu den o3‑Bewertungen findest du hier.
Unsere interne SWE-Aufgaben-Benchmark ist ein kuratierter Satz realer interner SWE-Aufgaben bei OpenAI.
Wir veröffentlichen Codex als Research-Preview im Einklang mit unserer iterativen Bereitstellungsstrategie. Bei der Entwicklung von Codex haben wir Sicherheit und Transparenz priorisiert, damit Benutzer die Ergebnisse überprüfen können – eine Sicherheitsmaßnahme, die immer wichtiger wird, da KI-Modelle immer komplexere Programmieraufgaben selbstständig bewältigen und Sicherheitsaspekte sich weiterentwickeln. Benutzer können die Arbeit von Codex anhand von Zitaten, Terminalprotokollen und Testergebnissen überprüfen. Bei Unsicherheiten oder Testfehlern teilt der Codex-Agent diese Probleme explizit mit und ermöglicht den Benutzern so, fundierte Entscheidungen zum weiteren Vorgehen zu treffen. Es ist für Benutzer weiterhin unerlässlich, den gesamten vom Agenten generierten Code vor der Integration und Ausführung manuell zu überprüfen und zu validieren.
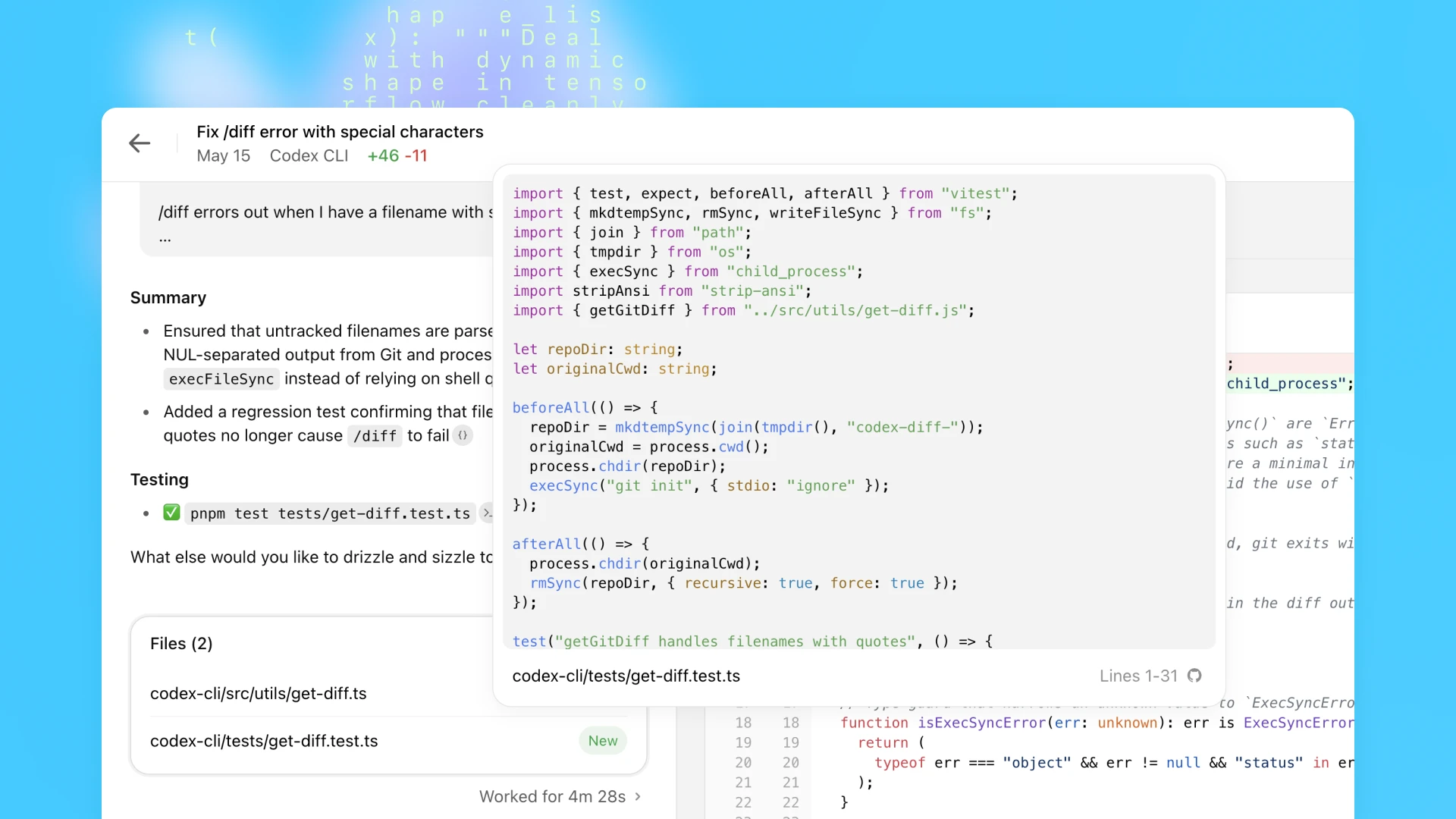
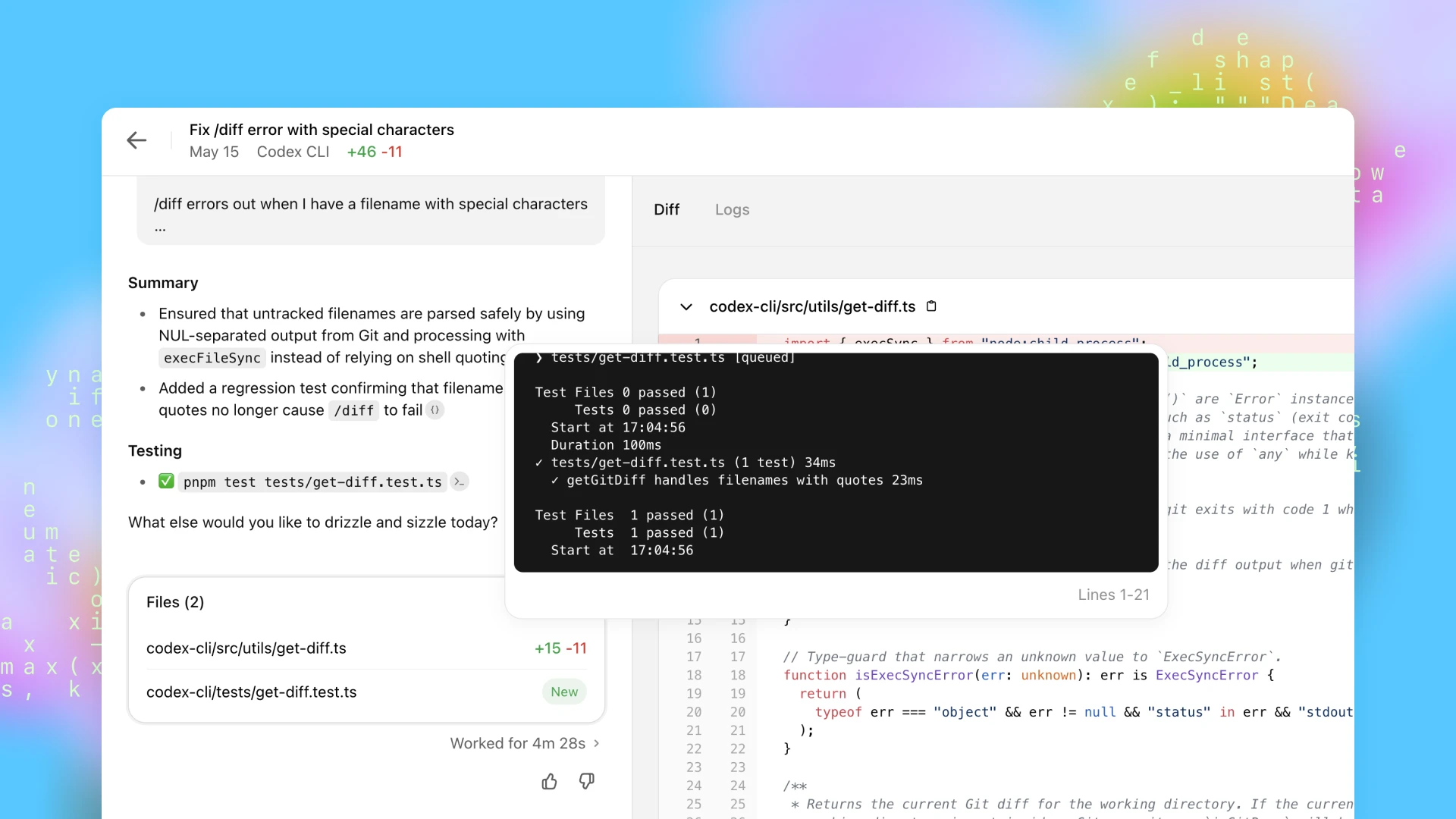
Ein Hauptziel beim Training von codex-1 bestand darin, die Ergebnisse eng an menschliche Programmierungspräferenzen und -standards anzupassen. Im Vergleich zu OpenAI o3 erstellt codex-1 durchweg sauberere Patches, die für eine sofortige menschliche Überprüfung und Integration in Standard-Workflows bereit sind.
Der Schutz vor bösartigen Anwendungen KI-gestützter Softwareentwicklung, wie etwa der Entwicklung von Malware, wird immer wichtiger. Gleichzeitig ist es unerlässlich, dass Schutzmaßnahmen legitime und nützliche Anwendungen nicht übermäßig behindern, wenn diese Techniken beinhalten, die manchmal auch zur Entwicklung von Malware verwendet werden, wie etwa Low-Level-Kernel-Engineering.
Um ein Gleichgewicht zwischen Sicherheit und Nutzen herzustellen, wurde Codex darauf trainiert, Anfragen zur Entwicklung bösartiger Software zu erkennen und präzise abzulehnen, während es legitime Aufgaben klar unterscheidet und unterstützt. Wir haben außerdem unsere Richtlinienrahmen verbessert und strenge Sicherheitsbewertungen integriert, um diese Grenzen wirksam zu verstärken. Um diese Bewertungen zu berücksichtigen, haben wir einen Zusatz zur o3‑Systemkarte veröffentlicht.
Der Codex-Agent arbeitet vollständig in einem sicheren, isolierten Container in der Cloud. Während der Ausführung der Aufgaben ist der Internetzugang deaktiviert, wodurch die Interaktion des Agenten ausschließlich auf den Code beschränkt ist, der explizit über GitHub-Repositorys bereitgestellt wird, und auf vorinstallierte Abhängigkeiten, die vom Benutzer über ein Setup-Skript konfiguriert werden. Der Agent kann nicht auf externe Websites, APIs oder andere Dienste zugreifen.
Die technischen Teams bei OpenAI haben begonnen, Codex als Teil ihres täglichen Toolkits zu verwenden. Es wird am häufigsten von OpenAI-Ingenieuren verwendet, um sich wiederholende, gut abgegrenzte Aufgaben wie Refactoring, Umbenennen und Schreiben von Tests auszulagern, die ansonsten den Fokus stören würden. Es ist gleichermaßen nützlich für die Entwicklung neuer Funktionen, die Verdrahtung von Komponenten, die Behebung von Fehlern und die Erstellung von Dokumentationen. Die Teams entwickeln in diesem Zusammenhang neue Gewohnheiten: Sie priorisieren Bereitschaftsprobleme, planen Aufgaben zu Beginn des Tages und delegieren Hintergrundarbeiten, um stetig voranzukommen. Indem Codex Kontextwechsel verringert und vergessene Aufgaben anzeigt, hilft es Ingenieuren dabei, schneller zu liefern und sich auf das Wesentliche zu konzentrieren.
Im Vorfeld der Veröffentlichung haben wir auch mit einer kleinen Gruppe externer Tester zusammengearbeitet, um besser zu verstehen, wie Codex für unterschiedliche Codebasen, Entwicklungsprozesse und Teams funktioniert.
- Cisco(wird in einem neuen Fenster geöffnet) untersucht, wie Codex seinen Entwicklungsteams dabei helfen kann, ehrgeizige Ideen schneller in die Tat umzusetzen. Als früher Designpartner hilft Cisco dabei, die Zukunft von Codex zu gestalten, indem das Unternehmen Codex für reale Anwendungsfälle im gesamten Produktportfolio evaluiert und dem OpenAI-Team Feedback liefert.
- Temporal(wird in einem neuen Fenster geöffnet) verwendet Codex, um die Entwicklung von Funktionen zu beschleunigen, Probleme zu beheben, Tests zu schreiben und auszuführen und große Codebasen zu refaktorieren. Darüber hinaus hilft Codex ihnen, konzentriert zu bleiben, indem komplexe Aufgaben im Hintergrund ausgeführt werden. So bleiben die Ingenieure fokussiert und die Iteration wird beschleunigt.
- Superhuman(wird in einem neuen Fenster geöffnet) verwendet Codex, um kleine, aber sich wiederholende Aufgaben wie die Verbesserung der Testabdeckung und die Behebung von Integrationsfehlern zu beschleunigen. Darüber hinaus kann das Unternehmen schneller liefern, indem Produktmanager leichte Codeänderungen vornehmen können, ohne einen Ingenieur hinzuziehen zu müssen, mit Ausnahme der Codeüberprüfung.
- Kodiak(wird in einem neuen Fenster geöffnet) verwendet Codex zum Schreiben von Tools zur Fehlerbehebung, zur Verbesserung der Testabdeckung und zum Refactoring von Code – und beschleunigt so die Entwicklung von Kodiak Driver, seiner autonomen Fahrtechnologie. Codex ist außerdem zu einem wertvollen Nachschlagewerk geworden, das Ingenieuren hilft, unbekannte Stack-Teile zu verstehen, indem relevante Zusammenhänge und frühere Änderungen ans Licht gebracht werden.
Basierend auf den Erkenntnissen früherer Tester empfehlen wir, mehreren Agenten gleichzeitig gut abgegrenzte Aufgaben zuzuweisen und mit unterschiedlichen Aufgabentypen und Prompts zu experimentieren, um die Fähigkeiten des Modells effektiv zu erkunden.
Letzten Monat haben wir Codex CLI eingeführt, einen Open-Source-Programmieragenten, der in deinem Terminal ausgeführt wird. Er bringt die Leistung von Modellen wie o3 und o4-mini in deinen lokalen Arbeitsablauf und erleichtert die Kopplung mit ihnen, um Aufgaben schneller zu erledigen.
Heute veröffentlichen wir auch eine kleinere Version von codex-1, eine Version von o4-mini, die speziell für die Verwendung in Codex CLI entwickelt wurde. Dieses neue Modell unterstützt schnellere Arbeitsabläufe in der CLI und ist für Code-Fragen und -Antworten sowie die Bearbeitung mit geringer Latenz optimiert, wobei die gleichen Stärken bei der Befolgung von Anweisungen und beim Stil erhalten bleiben. Es ist jetzt als Standardmodell in Codex CLI und in der API als codex-mini-latest verfügbar. Der zugrunde liegende Snapshot wird regelmäßig aktualisiert, während wir das Codex-mini-Modell weiter verbessern.
Wir machen es außerdem einfacher, dein Entwicklerkonto mit Codex CLI zu verbinden. Anstatt ein API-Token manuell zu generieren und zu konfigurieren, kannst du dich jetzt mit deinem ChatGPT‑Konto anmelden und die API-Organisation auswählen, die du verwenden möchtest. Wir generieren und konfigurieren den API-Schlüssel automatisch für dich. Plus- und Pro-Benutzer, die sich mit ChatGPT bei Codex CLI anmelden, können außerdem für die nächsten 30 Tage kostenlose API-Guthaben im Wert von 5 bzw. 50 US-Dollar einlösen.
Wir beginnen heute mit der Einführung von Codex für ChatGPT Pro-, Enterprise- und Team-Benutzer weltweit. Der Support für Plus und Edu folgt in Kürze. In den kommenden Wochen erhalten Benutzer umfassenden Zugriff ohne zusätzliche Kosten, sodass du die Möglichkeiten von Codex erkunden kannst. Anschließend führen wir eingeschränkten Zugriff und flexible Preisoptionen ein, mit denen du bei Bedarf zusätzliche Nutzung erwerben kannst. Wir planen, den Zugriff zeitnah auf Plus- und Edu-Benutzer zu erweitern.
Für Entwickler, die mit codex-mini-latest arbeiten, ist das Modell auf der Responses API verfügbar zum Preis von 1,50 USD pro 1 Million Eingabetokens und 6 USD pro 1 Million Ausgabetokens, mit einem Prompt-Caching-Rabatt von 75 %.
Codex befindet sich noch in der Frühentwicklungsphase. Im Rahmen der Research-Preview fehlen derzeit Funktionen wie Bildeingaben für die Frontend-Arbeit und die Möglichkeit, den Agenten während seiner Arbeit zu korrigieren. Darüber hinaus dauert das Delegieren an einen Remote-Agenten länger als die interaktive Bearbeitung, was eine gewisse Gewöhnung erfordern kann. Im Laufe der Zeit wird die Interaktion mit Codex-Agenten immer mehr einer asynchronen Zusammenarbeit mit Kollegen ähneln. Mit der Weiterentwicklung der Modellfunktionen erwarten wir, dass Agenten über längere Zeiträume hinweg komplexere Aufgaben bewältigen können.
Wir stellen uns eine Zukunft vor, in der Entwickler nach Wunsch einen Teil der Arbeit selbst erledigen und den Rest an Agenten delegieren – und dabei mit KI schneller und produktiver arbeiten können. Um dies zu erreichen, entwickeln wir eine Reihe von Codex-Tools, die sowohl die Zusammenarbeit in Echtzeit als auch die asynchrone Delegierung unterstützen.
Die Kopplung mit KI-Tools wie Codex CLI und anderen hat sich schnell zum Branchenstandard entwickelt und hilft Entwicklern, beim Programmieren schneller voranzukommen. Wir sind jedoch davon überzeugt, dass der von Codex in ChatGPT eingeführte asynchrone Multi-Agenten-Workflow für Ingenieure zum Standardverfahren für die Erstellung von qualitativ hochwertigem Code werden wird.
Letztendlich sehen wir, dass diese beiden Interaktionsmodi – Echtzeit-Pairing und Aufgabendelegation – zusammenlaufen. Entwickler werden in ihren IDEs und alltäglichen Tools mit KI-Agenten zusammenarbeiten, um Fragen zu stellen, Vorschläge zu erhalten und längere Aufgaben auszulagern – alles in einem einheitlichen Workflow.
Für die Zukunft planen wir die Einführung von stärker interaktiven und flexiblen Agenten-Workflows. Entwickler können bald mitten in der Aufgabe Anleitungen geben, bei Implementierungsstrategien zusammenarbeiten und proaktive Updates zum Fortschritt erhalten. Wir planen außerdem tiefere Integrationen über alle Tools hinweg, die du bereits verwendest: Heute wird Codex mit GitHub verbunden, und schon bald kannst du Aufgaben von Codex CLI, ChatGPT Desktop oder sogar Tools wie deinem Issue-Tracker oder CI-System zuweisen.
Die Softwareentwicklung ist eine der ersten Branchen, die durch KI erhebliche Produktivitätssteigerungen verzeichnet und Einzelpersonen und kleinen Teams neue Möglichkeiten eröffnet. Wir sind bezüglich dieser Erfolge zwar optimistisch, arbeiten aber auch mit Partnern zusammen, um die Auswirkungen einer breiten Übernahme von Agenten auf die Arbeitsabläufe der Entwickler, die Kompetenzentwicklung der einzelnen Mitarbeiter, die Kompetenzstufen und die geografische Lage besser zu verstehen.
Dies ist erst der Anfang – und wir sind gespannt, was du mit Codex erstellen wirst.
Systemnachricht
Wir teilen die codex-1-Systemnachricht, um Entwicklern dabei zu helfen, das Standardverhalten des Modells zu verstehen und Codex so anzupassen, dass es in benutzerdefinierten Arbeitsabläufen effektiv funktioniert. Beispielsweise fordert die codex-1-Systemnachricht Codex dazu auf, alle in der Datei „AGENTS.md“ genannten Tests auszuführen. Wenn du jedoch unter Zeitdruck stehst, kannst du Codex bitten, diese Tests zu überspringen.