OpenAI ၏ နည်းပညာ ရှင်းလင်းချက်

OpenAI ကို 2015 ခုနှစ်တွင် အကျိုးအမြတ်မယူသော အဖွဲ့အစည်းအဖြစ် တည်ထောင်ခဲ့ပြီး အထွေထွေ ဉာဏ်ရည်တု—အကျဉ်းချုပ်အားဖြင့် လူတစ်ယောက်လောက် အနည်းဆုံး ဉာဏ်ကောင်းသော AI—သည် လူသားအားလုံးအတွက် အကျိုးဖြစ်စေရန် ရည်ရွယ်ခဲ့သည်။ ကျွန်ုပ်တို့သည် စွမ်းဆောင်ရည်အမြင့်ဆုံး AI နည်းပညာများအပြင် AI ၏ လုံခြုံရေး၊ alignment နှင့် governance အတွက် ကိရိယာများနှင့် အကောင်းဆုံး လုပ်ဆောင်ပုံများကိုလည်း သုတေသနပြု၊ ဖွံ့ဖြိုးတိုးတက်စေပြီး ထုတ်ပြန်ပေးပါသည်။ OpenAI သည် ယနေ့အထိ ကျွန်ုပ်တို့၏ အကျိုးအမြတ်မယူသော အဖွဲ့အစည်းက စီမံအုပ်ချုပ်နေဆဲဖြစ်သည်။ ကျွန်ုပ်တို့သည် အမြတ်အစွန်းထက် မစ်ရှင်ကို ဦးစားပေးပြီး၊ ဝန်ထမ်းများနှင့် ရင်းနှီးမြှုပ်နှံသူများအတွက် ငွေကြေးအကျိုးအမြတ်ကို ကန့်သတ်ထားကာ၊ ကန့်သတ်ချက်ထက် ကျော်လွန်သော အနာဂတ်အမြတ်များကို ကျွန်ုပ်တို့၏ အကျိုးအမြတ်မယူသော အဖွဲ့အစည်းထံ ပြန်လည်ပေးအပ်မည်ဖြစ်သည်။ ဤထူးခြားသော ကော်ပိုရိတ်ဖွဲ့စည်းပုံက အခြား နည်းပညာကုမ္ပဏီများနှင့် မတူညီသော လှုံ့ဆော်မှုများကို ကျွန်ုပ်တို့အား ပေးပါသည်။ ကျွန်ုပ်တို့၏ ရည်မှန်းချက်မှာ မည်သည့်အရာကိုမဆို အများဆုံး ရောင်းချရန် မဟုတ်ဘဲ AI ၏ လူမှုရေး၊ စီးပွားရေးနှင့် နည်းပညာဆိုင်ရာ အခွင့်အလမ်းများမှ လူတိုင်း အကျိုးခံစားရသော ကမ္ဘာတစ်ခုဆီသို့ လုပ်ဆောင်သွားရန် ဖြစ်သည်။
OpenAI ၏ မစ်ရှင်၏ တစ်စိတ်တစ်ပိုင်းအဖြစ် ကျွန်ုပ်တို့သည် ဦးဆောင်နေသော foundation models များကို ဖွံ့ဖြိုးတိုးတက်စေပြီး ၎င်းတို့၏ စွမ်းရည်များကို ကမ္ဘာတစ်ဝန်းရှိ လူများ(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်)ထံ လုံခြုံပြီး အကျိုးရှိသော နည်းလမ်းများဖြင့် ရရှိအသုံးပြုနိုင်အောင် ပြုလုပ်ပေးပါသည်။ လူများက ကျွန်ုပ်တို့၏ မော်ဒယ်များကို အသုံးပြုနိုင်သည့် အဓိက နည်းလမ်းနှစ်ခုရှိပါသည်-
- ChatGPT သည် လူများအား ကျွန်ုပ်တို့၏ မော်ဒယ်များနှင့် စကားပြောဆိုသကဲ့သို့ အပြန်အလှန် ဆက်သွယ်နိုင်စေသော app တစ်ခုဖြစ်သည်။ အသုံးပြုသူများသည် ကျွန်ုပ်တို့၏ ဘာသာစကား မော်ဒယ်များကို စာသား သို့မဟုတ် ကုဒ်ကို ခွဲခြမ်းစိတ်ဖြာရန် သို့မဟုတ် ရေးသားရန် တောင်းဆိုနိုင်ပြီး၊ သို့မဟုတ် ကျွန်ုပ်တို့၏ ရုပ်ပုံ မော်ဒယ်များကို စာသားဖော်ပြချက်အပေါ် အခြေခံ၍ ရုပ်ပုံများ ဆွဲရန် တောင်းဆိုနိုင်ပါသည်။ ChatGPT ကို chatgpt.com(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်) တွင် အသုံးပြုသူအားလုံးအတွက် အခမဲ့ ရရှိနိုင်ပါသည်။ အသုံးပြုသူများသည် ထပ်ဆောင်း လုပ်ဆောင်ချက်များနှင့် စွမ်းရည်များကို အသုံးပြုနိုင်စေသော လစဉ် premium subscription အတွက် စာရင်းသွင်းနိုင်ပြီး၊ စီးပွားရေးလုပ်ငန်းများ ဝယ်ယူနိုင်ရန် enterprise version ကိုလည်း ကျွန်ုပ်တို့ ပေးထားပါသည်။
- ကျွန်ုပ်တို့၏ API (Application Programming Interface) သည် developers များအား ကျွန်ုပ်တို့၏ မော်ဒယ်များ၏ စွမ်းရည်များနှင့် အကျိုးကျေးဇူးများကို ၎င်းတို့၏ ကိုယ်ပိုင် application များထဲတွင် ပေါင်းစည်းနိုင်စေပါသည်။ Duolingo, Spotify နှင့် Morgan Stanley တို့အပါအဝင် အဖွဲ့အစည်းထောင်ပေါင်းများစွာသည် ကျွန်ုပ်တို့၏ API ကို အသုံးပြု၍ လုပ်ဆောင်ချက်အသစ်များ၊ application များနှင့် စီးပွားရေးလုပ်ငန်းများကို တည်ဆောက်နေကြသည်။ Be My Eyes ဟုခေါ်သော ဒိန်းမတ်ကုမ္ပဏီတစ်ခုသည် မျက်မမြင်နှင့် အမြင်အားနည်းသော အသုံးပြုသူများက ရုပ်ပုံများ တင်ပြီး ထိုရုပ်ပုံများအကြောင်း မေးခွန်းများ မေးနိုင်ရန် ကျွန်ုပ်တို့၏ API ကို အသုံးပြုကာ ၎င်းတို့ကို ရုပ်ပိုင်းဆိုင်ရာ ပတ်ဝန်းကျင်များအတွင်း ပိုမိုကောင်းမွန်စွာ သွားလာနိုင်ရန်နှင့် ကိုယ်ပိုင်လွတ်လပ်မှု ပိုမိုရရှိရန် ကူညီပေးပါသည်။ ကျွန်ုပ်တို့၏ API ကို platform.openai.com(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်) တွင် ရရှိနိုင်ပြီး developers များသည် အသုံးပြုသလောက် API access အတွက် ပေးချေရပါသည်။
အောက်တွင် ပိုမိုအသေးစိတ် ဖော်ပြထားသည့်အတိုင်း ကျယ်ပြန့်သော လုံခြုံရေးအစီအမံများနှင့်အတူ ChatGPT နှင့် ကျွန်ုပ်တို့၏ API ကို ရရှိအသုံးပြုနိုင်အောင် ပြုလုပ်ပေးပါသည်။ ထို့အပြင် စကားမှစာသို့ ပြောင်းပေးသော မော်ဒယ် Whisper နှင့် CLIP ဟုခေါ်သော ရုပ်ပုံနားလည်မှု မော်ဒယ်ကဲ့သို့သော မော်ဒယ် အချို့ကိုလည်း ထိုသို့ ထုတ်ပြန်ခြင်း၏ ဖြစ်နိုင်ချေရှိသော အန္တရာယ်များကို အကဲဖြတ်ပြီးနောက် open source ပုံစံဖြင့် ရရှိစေပါသည်။
ChatGPT ကို အခမဲ့ ဆက်လက် ရရှိနိုင်အောင် ပြုလုပ်ထားမည်ဖြစ်ပြီး premium ဝန်ဆောင်မှုများအတွက် ပေးချေရန် ရွေးချယ်သော အသုံးပြုသူများနှင့် စီးပွားရေးလုပ်ငန်းများထံမှ ဝင်ငွေ ရရှိမည်ဟု ကျွန်ုပ်တို့ ရည်ရွယ်ထားပါသည်။ ကြီးမားသော အတိုင်းအတာရှိ foundation models များကို ဖွံ့ဖြိုးတိုးတက်စေခြင်းနှင့် ပံ့ပိုးပေးခြင်း၏ ကုန်ကျစရိတ်များ မြင့်မားသောကြောင့် ကျွန်ုပ်တို့၏ အဖွဲ့အစည်းသည် အမြတ်မရသေးသလို မကြာမီကာလအတွင်း အမြတ်ရမည်ဟုလည်း မမျှော်လင့်ထားပါ—ကျွန်ုပ်တို့၏ ရည်မှန်းချက်မှာ AI ၏ အကျိုးကျေးဇူးများကို ကမ္ဘာအနှံ့သို့ ကျယ်ကျယ်ပြန့်ပြန့်နှင့် လုံခြုံစွာ ရရှိစေရန် ဆက်လက်လုပ်ဆောင်ရန် ဖြစ်ပါသည်။
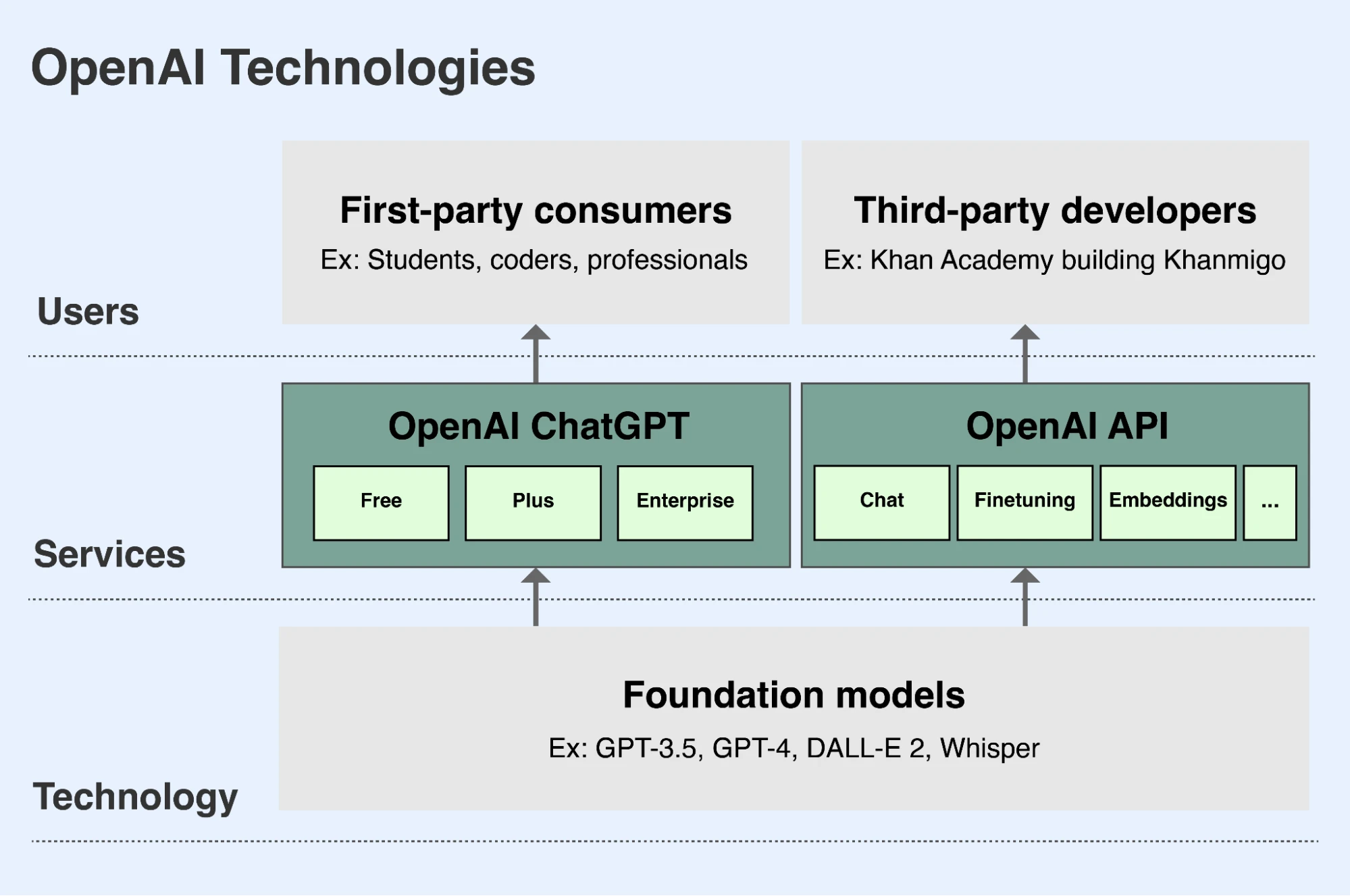
OpenAI သည် ကျွန်ုပ်တို့၏ ဦးဆောင်နေသော foundation models များကို အဓိကအားဖြင့် ChatGPT နှင့် ကျွန်ုပ်တို့၏ API မှတစ်ဆင့် ရရှိအသုံးပြုနိုင်အောင် ပြုလုပ်ပေးပါသည်။
GPT‑4 ကဲ့သို့ အဆင့်မြင့် ဘာသာစကား မော်ဒယ်တစ်ခုကို ဖန်တီးရန် (1) ခန့်မှန်းနိုင်မှု၊ အကြောင်းပြချက်ချနိုင်မှုနှင့် ပြဿနာဖြေရှင်းနိုင်မှုကဲ့သို့သော ဉာဏ်ရည်စွမ်းရည်များကို သင်ပေးရပြီး၊ ထို့အပြင် (2) လူသားတို့၏ တန်ဖိုးများနှင့် နှစ်သက်မှုများနှင့် ကိုက်ညီအောင် လိုက်ဖက်စေရပါသည်။ ပထမပိုင်းကို “အကြိုလေ့ကျင့်သင်ကြားခြင်း” ဟုခေါ်သော လုပ်ငန်းစဉ်ဖြင့် ဆောင်ရွက်ပြီး၊ ထိုလုပ်ငန်းစဉ်တွင် လများတစ်လျှောက် လူသားအသိပညာ အများအပြားကို မော်ဒယ်အား ပြသပေးပါသည်။ ထို့နောက် လူသားရွေးချယ်မှုကို မော်ဒယ်ထဲ ထည့်သွင်းရန် “post-training” ဟုခေါ်သော ဒုတိယအဆင့်ကို အသုံးပြုပြီး မော်ဒယ်ကို ပိုမိုလုံခြုံကာ ပိုမိုအသုံးဝင်အောင် လုပ်ဆောင်ပါသည်။
အကြိုလေ့ကျင့်သင်ကြားခြင်း သည် စာသားအမျိုးမျိုးကို မော်ဒယ်အား ပြသပြီး၊ များစွာသော စာကြောင်းအစဉ်အဆက်များတစ်ခုချင်းစီတွင် နောက်လာမည့် စကားလုံးကို ခန့်မှန်းစေခြင်းဖြင့် ဘာသာစကားကို မော်ဒယ်အား သင်ပေးခြင်းဖြစ်သည်။ မော်ဒယ်များသည် စကားလုံး ထရီလီယံများစွာကို ပြန်လည်ကြည့်ရှု၊ ခွဲခြမ်းစိတ်ဖြာ၊ သင်ယူရသဖြင့် အလွန်ကြီးမားသော ကွန်ပျူတာတွက်ချက်မှုလိုအပ်ပါသည်။ ကျွန်ုပ်တို့သည် အခြေခံ မော်ဒယ်များကို လေ့ကျင့်ရန် စူပါကွန်ပျူတာများ တည်ဆောက်ထားပြီး၊ အခြေခံ မော်ဒယ်အသစ်တစ်ခုကို လေ့ကျင့်ခြင်းတစ်ခုတည်းပင် စူပါကွန်ပျူတာတစ်လုံးကို လများစွာ အလုပ်လုပ်စေနိုင်ပါသည်။ ဤကျယ်ပြန့်သော လုပ်ငန်းစဉ်မှတစ်ဆင့် မော်ဒယ်သည် စကားလုံးများကို သဒ္ဒါအရ မည်သို့ချိတ်ဆက်ရသည်သာမက၊ စကားလုံးများပေါင်းစည်းကာ ပိုမိုမြင့်မားသော အယူအဆများ ဖွဲ့စည်းပုံနှင့် နောက်ဆုံးတွင် စကားလုံးအစဉ်အဆက်များက ဖွဲ့စည်းတည်ဆောက်ထားသော အတွေးများ သို့မဟုတ် တိကျရှင်းလင်းသော ပြဿနာများကို မည်သို့ပေါ်ပေါက်စေသည်ကိုပါ သင်ယူပါသည်။ ဥပမာအားဖြင့် “cloud” ဟူသော စကားလုံးကို စဉ်းစားသောအခါ “sky” နှင့် “rain” ကဲ့သို့ ဆက်စပ်စကားလုံးများကိုလည်း စဉ်းစားမိနိုင်ပါသည်။ “The secret to happiness is” ကဲ့သို့သော ဝါကျတစ်ကြောင်းကို ပေးလိုက်ပါက အမျိုးမျိုးသော ဒဿနအယူအဆများကို စဉ်းစားမိနိုင်ပါသည်။ နောက်လာမည့် စကားလုံးကို ခန့်မှန်းရာတွင် ကျွမ်းကျင်လာခြင်းဖြင့် မော်ဒယ်သည် အယူအဆများနှင့် ဉာဏ်ရည်၏ အခြေခံတည်ဆောက်ပုံများကို သင်ယူလာပါသည်။
ဤလုပ်ငန်းစဉ်၏ ရလဒ်ဖြစ်သော အခြေခံ မော်ဒယ်သည် ၎င်း၏ လေ့ကျင့်ဒေတာတွင် မမြင်ဖူးသေးသော အသစ်သော ပြဿနာများကိုပင် ဘာသာစကားအမျိုးမျိုးအတွင်း အံ့အားသင့်ဖွယ် ဖြေရှင်းနိုင်စွမ်းရှိပါသည်။ သို့သော် အခြေခံ မော်ဒယ်တစ်ခုတည်းဖြင့် အသုံးပြုရန် အဆင်သင့် မဖြစ်သေးပါ။ အခြေခံ မော်ဒယ်များသည် အားကောင်းပြီး ပြောင်းလွယ်ပြင်လွယ်ရှိသည်။ ၎င်းတို့သည် ဉာဏ်ရည်ရှိပြီး အံ့အားသင့်စရာဖြစ်သော်လည်း မဖြစ်မနေ အသုံးဝင်သို့မဟုတ် လုံခြုံမည်ဟု မဆိုနိုင်ပါ။
အခြေခံ မော်ဒယ်နှင့် စကားပြောဆက်ဆံရန် မလွယ်ကူပါ။ ဥပမာအားဖြင့် GPT‑4 အခြေခံ မော်ဒယ်အား “မင်းသမီးတစ်ယောက်အကြောင်း ဇာတ်လမ်းရေးပါ…” ဟု မေးပါက များသောအားဖြင့် ဇာတ်လမ်းတစ်ပုဒ် မရေးပေးပါ။ ယင်းအစား သင့်ပြောဆိုချက်ကို ဆက်ချဲ့ကာ နောက်ထပ် မည်သို့ဆက်မည်ကို ခန့်မှန်းပေးပါလိမ့်မည်။ ဥပမာအားဖြင့် “...မြင်းတွေကို ချစ်တဲ့ မင်းသမီးတစ်ယောက်အကြောင်း” ဟု ထုတ်ပေးနိုင်ပါသည်။ အခြေခံ မော်ဒယ်တွင် မုန်းတီးဖွယ်၊ အကြမ်းဖက်ဆန်သော အကြောင်းအရာများကဲ့သို့ မလိုလားအပ်သော အကြောင်းအရာများ မထုတ်ပေးစေရန် ကာကွယ်ရေးစနစ်များလည်း မပါဝင်သေးပါ။ ကျွန်ုပ်တို့သည် အကြိုလေ့ကျင့်သင်ကြားခြင်း ဒေတာစုစည်းမှုမှ မလိုလားအပ်သော အကြောင်းအရာများကို စစ်ထုတ်သော်လည်း၊ ဤလျော့ပါးရေးနည်းလမ်းသည် မော်ဒယ်ကို တိကျစွာ ပြောင်းလဲရန် လုံလောက်အောင် မတိကျဘဲ၊ မပြောသင့် သို့မဟုတ် မလုပ်သင့်သည်များကို မော်ဒယ်နားလည်ခြင်းကိုပင် တားဆီးမိနိုင်သောကြောင့် တစ်ခါတရံ ဆိုးကျိုးပြန်ပေးနိုင်ပါသည်။ ဘာအသုံးဝင်သည်၊ ဘာကို သင့်တော်စွာ ပြောသင့်သည်တို့ အပါအဝင် လူသားတန်ဖိုးများကို မော်ဒယ်များထဲ ထည့်သွင်းနိုင်ရန် ကျွန်ုပ်တို့သည် post-training ဟုခေါ်သော လုပ်ငန်းစဉ်အတွက် alignment နှင့် safety နည်းပညာများကို သုတေသနပြု ဖွံ့ဖြိုးတိုးတက်လျက်ရှိပါသည်။
Post-training သည် ကျွန်ုပ်တို့၏ မော်ဒယ်များထဲ လူသားရွေးချယ်မှုကို ထည့်သွင်းကာ ၎င်းတို့ကို အသုံးဝင်ပြီး ထိရောက်ကာ ပိုမိုလုံခြုံသော ကိရိယာများအဖြစ် ပြောင်းလဲပေးသော နည်းလမ်းဖြစ်သည်။ လူများက ပိုအသုံးဝင်သည်ဟု ထင်မြင်သော ပုံစံများဖြင့် မော်ဒယ်ကို တုံ့ပြန်တတ်အောင် သင်ပေးပြီး၊ အန္တရာယ်ဖြစ်စေမည်ဟု ကျွန်ုပ်တို့ ယုံကြည်သော ပုံစံများဖြင့် တုံ့ပြန်ရန်ကိုလည်း ငြင်းဆိုတတ်အောင် သင်ပေးပါသည်။ Post-training အတွက် သုတေသန၊ ဝန်ထမ်းအင်အား၊ ဒီဇိုင်းရွေးချယ်မှုများနှင့် ဒေတာဖန်တီးမှုတို့တွင် အရေးကြီးသော ရင်းနှီးမြှုပ်နှံမှုများ လိုအပ်ပါသည်။ ဤသည်မှာ OpenAI အတွက် လက်ရှိတက်ကြွစွာ သုတေသနပြုနေပြီး ရင်းနှီးမြှုပ်နှံနေသော နယ်ပယ်တစ်ခုဖြစ်သည်။ လူသားတန်ဖိုးများကို ထင်ဟပ်စေရန် ဒေတာဖန်တီးခြင်းနှင့် ဒီဇိုင်းဆိုင်ရာ ဆုံးဖြတ်ချက်များချမှတ်ခြင်း အလုပ်တွင် ကျွန်ုပ်တို့ ကုမ္ပဏီပြင်ပမှ လူအများအပြားလည်း ပါဝင်မည်ဟု ကျွန်ုပ်တို့ ယုံကြည်ပါသည်။
Post-training သည် စံပြအပြုအမူကို ကိုယ်စားပြုသော အတော်လေး သေးငယ်ပြီး ဂရုတစိုက် အင်ဂျင်နီယာလုပ်ထားသော ဒေတာစုများကို အသုံးပြု၍ မော်ဒယ်တွင် ရည်ရွယ်ချက်ရှိသော ပြောင်းလဲမှုများ ဖြစ်ပေါ်စေပါသည်။ ကျွန်ုပ်တို့သည် လူများအား နမူနာအဖြေများ ရေးစေပြီး၊ မော်ဒယ်က ပေးသော အဖြေများကို အဆင့်သတ်မှတ်စေကာ၊ ထိုနမူနာများနှင့် အဆင့်သတ်မှတ်ချက်များကို နောက်ဆက်တွဲ လေ့ကျင့်မှုလုပ်ငန်းစဉ်များတွင် မော်ဒယ်ထံ ပြန်ပေးခြင်းဖြင့် ဤအရာကို ဆောင်ရွက်ပါသည်။ ကျွန်ုပ်တို့သည် ဤနည်းပညာများ၏ ရှေ့ပြေးဖြစ်ခဲ့ပြီး လူတုံ့ပြန်မှုမှ အားဖြည့် သင်ယူလေ့လာခြင်း (RLHF) ကိုလည်း အပါအဝင် ဖွံ့ဖြိုးတိုးတက်စေခဲ့ရာ ယခုအခါ စက်မှုလုပ်ငန်းစံဖြစ်လာပါပြီ။ ကျွန်ုပ်တို့သည် RLHF ကို အသုံးပြု၍ မော်ဒယ်အား ညွှန်ကြားချက်များကို လိုက်နာတတ်စေရန်၊ မှားယွင်းသော အကြောင်းအရာများ ပြန်ပေးနိုင်ချေကို လျှော့ချရန်နှင့် လုံခြုံရေးဆိုင်ရာ လုပ်ဆောင်ချက်များ ထည့်သွင်းရန် သင်ပေးပါသည်။
GPT‑4 ကို အများပြည်သူထံ မထုတ်ပြန်မီ ကျွန်ုပ်တို့သည် post-training ကို ၆ လကြာ ထပ်ခါတလဲလဲ ပြုပြင်တိုးတက်စေခဲ့ပါသည်။ ဤကာလအတွင်း ကျွန်ုပ်တို့သည် အန္တရာယ်ဖြစ်စေနိုင်သည့် တောင်းဆိုမှုများကို ကျွန်ုပ်တို့၏ မော်ဒယ်များက တုံ့ပြန်ရန် ငြင်းဆိုတတ်အောင် သင်ပေးရန် နည်းပညာများကို ဖွံ့ဖြိုးတိုးတက်စေခဲ့ပါသည်။ ဥပမာအားဖြင့် ဗုံးတစ်လုံး တည်ဆောက်နည်း ညွှန်ကြားချက်များကို မေးပါက မော်ဒယ်က တုံ့ပြန်ရန် ငြင်းဆိုပါလိမ့်မည်။ GPT‑4 သည် ယခင်မျိုးဆက် မော်ဒယ် GPT‑3.5 နှင့် နှိုင်းယှဉ်ပါက ခွင့်မပြုထားသော အကြောင်းအရာများအတွက် တောင်းဆိုမှုများကို တုံ့ပြန်နိုင်ချေ 82% လျော့နည်းစေခဲ့ကြောင်း ကျွန်ုပ်တို့၏ အတွင်းပိုင်း အကဲဖြတ်ချက်များအရ သိရပါသည်။ ထို့ပြင် အချက်အလက်မှန်ကန်သော တုံ့ပြန်ချက်များ ထုတ်ပေးနိုင်ချေကို 40% တိုးမြှင့်ရန်၊ စကားပြောဆိုသကဲ့သို့ တုံ့ပြန်တတ်အောင် သင်ပေးရန်နှင့် Iceland နှင့် မိတ်ဖက်ပူးပေါင်း၍ အရင်းအမြစ်နည်းသော ဘာသာစကားများတွင် စွမ်းဆောင်ရည်ကို မြှင့်တင်ရန်လည်း ဤအချိန်ကို အသုံးပြုခဲ့ပါသည်။
ကျွန်ုပ်တို့သည် မော်ဒယ်များအတွင်း လူသားရွေးချယ်မှုကို ပိုမိုကောင်းမွန်စွာ ထင်ဟပ်စေရန် post-training နည်းပညာများကို ဆက်လက် ဖွံ့ဖြိုးတိုးတက်(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်) လျက်ရှိပါသည်။ ဥပမာအားဖြင့် ကျွန်ုပ်တို့၏ နည်းလမ်းအချို့သည် ပိုကောင်း သို့မဟုတ် ပိုဆိုးသော အပြုအမူ ဥပမာများကို အမှတ်ပေးရန် မလိုဘဲ စနစ်တစ်ခုက လိုက်နာသင့်သော စည်းမျဉ်းများကို လူများက ဖော်ပြနိုင်စွမ်း ရှိလာစေပါသည်။
ကျွန်ုပ်တို့ကိုယ်တိုင် ပြုလုပ်သော post-training အပြင်၊ ဖောက်သည်များအနေဖြင့် ၎င်းတို့၏ သီးခြားရည်မှန်းချက်များကို ပြီးမြောက်စေရန် ကျွန်ုပ်တို့၏ မော်ဒယ်များကို “fine-tune” လုပ်နိုင်စွမ်းကိုလည်း ပေးထားပါသည်။ ဥပမာအားဖြင့် ၎င်းတို့ပိုင်ဆိုင်သည့် ဘာသာစကားများဖြင့် ဆော့ဖ်ဝဲကုဒ်ရေးခြင်း၊ လုပ်ငန်းနယ်ပယ် သီးသန့် အသိပညာ သင်ပေးခြင်း သို့မဟုတ် ၎င်းတို့၏ အမှတ်တံဆိပ်နှင့် ကိုက်ညီသော အသံနေအသံထားဖြစ်စေရန် လိုက်ဖက်စေခြင်းတို့ဖြစ်သည်။ ဖောက်သည်များသည် ရရှိလိုသော အပြုအမူကို ပြသသော ဒေတာများကို ပြင်ဆင်ကာ ကျွန်ုပ်တို့၏ API မှတစ်ဆင့် နောက်ထပ် post-training အတွက် တင်သွင်းခြင်းဖြင့် ဤအရာကို ဆောင်ရွက်ပါသည်။ ဒေတာသည် ကျွန်ုပ်တို့၏ လုံခြုံရေးစစ်ဆေးမှုများကို ကျော်လွန်ပါက ထို fine-tuned မော်ဒယ်ကို ထိုဖောက်သည်တစ်ဦးတည်းအတွက်သာ အသုံးပြုနိုင်အောင် ပြုလုပ်ပေးပါသည်။ အခြား API traffic များကဲ့သို့ပင် fine-tuned မော်ဒယ်များက ကျွန်ုပ်တို့၏ အသုံးပြုမှုမူဝါဒများကို ချိုးဖောက်ခြင်း ရှိမရှိကို တွေ့ရှိနိုင်ရန် အောက်တွင် ဖော်ပြထားသော စောင့်ကြည့်ခြင်းနှင့် ရှာဖွေထောက်လှမ်းခြင်း စနစ်များကို ကျွန်ုပ်တို့ အသုံးပြုပါသည်။
Post-training မှတစ်ဆင့် လုံခြုံရေး ရရှိခြင်းအပြင် ကျွန်ုပ်တို့သည် တင်းကျပ်သော စမ်းသပ်မှုများ ပြုလုပ်ပြီး၊ ပြင်ပကျွမ်းကျင်သူများ၏ အကြံပြုချက်များကို ရယူကာ၊ လုံခြုံရေးနှင့် စောင့်ကြည့်ရေးစနစ်များကို တည်ဆောက်ကာ အားဖြည့်ကာ၊ လူများက ကျွန်ုပ်တို့၏ မော်ဒယ်များကို တာဝန်သိစွာ အသုံးပြုနိုင်ရန် အရင်းအမြစ်များ ပံ့ပိုးပေးပါသည်။ လုံခြုံရေးအတွက် ဤပြည့်စုံသော ချဉ်းကပ်မှုကြောင့် မုန်းတီးဖွယ်၊ နှောင့်ယှက်ဖွယ် သို့မဟုတ် အကြမ်းဖက်ဆန်သော အကြောင်းအရာများ ဖန်တီးခြင်း၊ နိုင်ငံရေး မဲဆွယ်စည်းရုံးရေးအတွက် အသုံးပြုခြင်း သို့မဟုတ် malware ဖန်တီးခြင်းကဲ့သို့ အန္တရာယ်ဖြစ်စေနိုင်သော နည်းလမ်းများဖြင့် ကျွန်ုပ်တို့၏ မော်ဒယ်များကို အသုံးပြုခြင်းကို တားမြစ်ထားသော အသုံးပြုမှုမူဝါဒ ကို အကောင်အထည်ဖော်နိုင်ပြီး လိုက်နာစေရန် ဆောင်ရွက်နိုင်ပါသည်။
Red-teaming နှင့် အကဲဖြတ်မှုများ။ ကျွန်ုပ်တို့သည် အဓိက မော်ဒယ်အသစ်တစ်ခုချင်းစီကို လုံခြုံရေးအန္တရာယ်များနှင့် ဘက်လိုက်မှု၊ ခွဲခြားဆက်ဆံမှုကဲ့သို့သော လူမှုရေး ထိခိုက်နစ်နာမှုများအတွက် အကဲဖြတ်ပါသည်။ ကျွန်ုပ်တို့သည် အတွင်းပိုင်းနှင့် ပြင်ပ red-teaming ကို ပြုလုပ်ပြီး၊ အန္တရာယ်များအတွက် မော်ဒယ်ကို အတွင်းပိုင်း စမ်းသပ်သကဲ့သို့ လုပ်ငန်းနယ်ပယ်မျိုးစုံမှ ကျွမ်းကျင်သူများကိုလည်း အစောပိုင်း အသုံးပြုခွင့် ပေးကာ စနစ်များကို စူးစမ်းစမ်းသပ်၍ အန္တရာယ်များကို မြေပုံဆွဲပြီး အကဲဖြတ်ရန် ကူညီစေပါသည်။ ကျွန်ုပ်တို့သည် ဤအကဲဖြတ်မှုများကို အသုံးပြု၍ မော်ဒယ်များနှင့် လုံခြုံရေးစနစ်များ၏ ဖွံ့ဖြိုးတိုးတက်မှုနှင့် ပိုမိုကောင်းမွန်အောင် ပြင်ဆင်မှုကို လမ်းညွှန်ကာ၊ တွေ့ရှိချက်များကိုလည်း အများပြည်သူထံ ထုတ်ပြန်ပါသည်။
လုံခြုံရေး စောင့်ကြည့်ရေးစနစ်များ။ ကျွန်ုပ်တို့သည် မလိုလားအပ်သော အကြောင်းအရာများကို ရှာဖွေတွေ့ရှိရန် ကူညီပြီး သီးခြားဖြစ်ရပ်များအပေါ် လူသား ပြန်လည်သုံးသပ်မှုကို အားဖြည့်ပေးသော စောင့်ကြည့်ရေးစနစ်များကို တည်ဆောက်ကာ အကောင်အထည်ဖော်ပါသည်။ ဤစနစ်များက အကြောင်းအရာချိုးဖောက်မှုကို တွေ့ရှိသောအခါ တုံ့ပြန်ရန် ငြင်းဆိုခြင်း၊ ဖြစ်ရပ်ကို လူသား ပြန်လည်သုံးသပ်မှုအတွက် အမှတ်အသားပြုခြင်း သို့မဟုတ် အလွန်ပြင်းထန်သော အခြေအနေများတွင် အသုံးပြုသူကို ယာယီပိတ်ခြင်းတို့အပါအဝင် လုပ်ဆောင်ချက်မျိုးစုံကို ကျွန်ုပ်တို့ ဆောင်ရွက်နိုင်ပါသည်။ Content classifiers များသည် fine-tuned ဘာသာစကား မော်ဒယ်များဖြင့် လည်ပတ်ပြီး၊ ၎င်းတို့၏ လွှမ်းခြုံနိုင်မှု၊ ထိရောက်မှုနှင့် တိကျမှုကို မည်သို့မြှင့်တင်ရမည်ကို ကျွန်ုပ်တို့ ဆက်လက် သုတေသနပြုနေပါသည်။ နောက်ဆုံးတွင် GPT‑4 ကို အသုံးပြု၍ moderation systems များ ဖွံ့ဖြိုးတိုးတက်စေခြင်း ကိုလည်း စူးစမ်းလေ့လာခဲ့ပါသည်။
အသုံးပြုသူများအတွက် ကိရိယာများ။ ကျွန်ုပ်တို့သည် AI ကို လုံခြုံစွာ အသုံးပြုနိုင်ရန် ကျွန်ုပ်တို့၏ အသုံးပြုသူများနှင့် ကျွန်ုပ်တို့၏ မော်ဒယ်များအပေါ် အခြေခံ၍ application များ တည်ဆောက်သော developers များကို အားပေးပံ့ပိုးရန် စာတမ်းများနှင့် ကိရိယာများကို ဖွံ့ဖြိုးတိုးတက်စေပါသည်။ စွမ်းဆောင်ရည်အမြင့်ဆုံး စနစ်အသစ်များကို မထုတ်ပြန်မီ မော်ဒယ် သို့မဟုတ် စနစ်၏ စွမ်းရည်များ၊ ကန့်သတ်ချက်များ၊ သင့်တော်သောနှင့် မသင့်တော်သော အသုံးပြုမှုနယ်ပယ်များကို ဖော်ပြသော အစီရင်ခံစာတစ်စောင်ကို ကျွန်ုပ်တို့ ထုတ်ပြန်ပါသည် (ဥပမာ GPT‑4(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်) နှင့် GPT‑4V အတွက် စနစ်ကဒ်များ)။ အသုံးပြုသူများက ၎င်းတို့၏ ကိုယ်ပိုင် အသုံးပြုမှုမူဝါဒများကို အကောင်အထည်ဖော်နိုင်ရန် အခမဲ့ Moderations API(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်) ကိုလည်း ရရှိစေပါသည်။ ထို့အပြင် ကျွန်ုပ်တို့၏ လုံခြုံရေးစနစ်များအပေါ် သုတေသနစာတမ်းများ ထုတ်ပြန်(ဝင်းဒိုးအသစ်တွင် ဖွင့်မည်) ပါသည်။
အကြံပြုချက်များမှ သင်ယူခြင်း။ အချိန်နှင့်အမျှ လုံခြုံသော AI စနစ်များ တည်ဆောက်ခြင်းနှင့် ကျွန်ုပ်တို့၏ မစ်ရှင်ကို အကောင်အထည်ဖော်နိုင်ခြင်းတွင် အကြံပြုချက်များမှ သင်ယူပြီး တုံ့ပြန်ခြင်းသည် အရေးကြီးသော အစိတ်အပိုင်းတစ်ခုဖြစ်သည်ဟု ကျွန်ုပ်တို့ ယုံကြည်ပါသည်။ အသုံးပြုသူ input များနှင့် အကြံပြုချက်များအပေါ် အခြေခံ၍ မော်ဒယ် output များ၊ moderation systems များနှင့် အသုံးပြုမှုမူဝါဒများကို ကျွန်ုပ်တို့ ဆက်လက် တိုးတက်ကောင်းမွန်အောင် လုပ်ဆောင်နေပါသည်။ ထို့အပြင် AI နည်းပညာကို အကျိုးအရှိဆုံး လက်ခံအသုံးပြုခြင်းနှင့် လိုက်လျောညီထွေ ပြောင်းလဲအသုံးပြုခြင်းတို့အကြောင်း ဆက်တိုက် stakeholder ဆွေးနွေးမှုများလည်း ပြုလုပ်နေပါသည်။
အထွေထွေ ဉာဏ်ရည်တုသည် လူသားဉာဏ်ရည်နှင့် ဆက်စပ်လေ့ရှိသော ပုံစံဖြင့် ပြုမူနိုင်သည့် ကွန်ပျူတာစနစ်များကို ဖန်တီးရန် ရည်ရွယ်သည့် ကွန်ပျူတာသိပ္ပံ၏ ခွဲဘာသာရပ်တစ်ခုဖြစ်သည်။ ဥပမာများတွင် chess ကဲ့သို့သော ဂိမ်းများကို ကစားနိုင်သော software၊ ကိုယ်တိုင်မောင်းနှင်နိုင်သော ကားများနှင့် လူသားဆန်သော စကားပြောဆိုမှုကို တုပနိုင်သော chatbot များ ပါဝင်သည်။
စက်သင်ယူမှုသည် အချက်အလက်များ သို့မဟုတ် စမ်းသပ်မှုများအပေါ် အခြေခံပြီး ကွန်ပျူတာစနစ်များက အလုပ်တာဝန်များကို သင်ယူပြီး ဆောင်ရွက်နိုင်သည့် အထွေထွေ ဉာဏ်ရည်တု နည်းလမ်းတစ်ခုဖြစ်သည်။ အဆင့်လိုက် ပရိုဂရမ်ရေးသွင်းထားရန် မလိုအပ်ပါ။ ဥပမာအားဖြင့် စက်သင်ယူမှုစနစ်တစ်ခုသည် ကြောင်ပုံအမျိုးမျိုးကို ကြည့်ပြီး ထိုပုံများ၏ လက္ခဏာများကို သင်ယူခြင်းဖြင့် ကြောင်ပုံတစ်ပုံကို ဆွဲတတ်လာနိုင်သည်။ ကြောင်၏ ပုံစံကို စာကြောင်းလိုက် ညွှန်ကြားချက်များ ပေးထားရန် မလိုပါ။ သို့မဟုတ် စနစ်တစ်ခုသည် ဗီဒီယိုဂိမ်းတစ်ခုကို စမ်းသပ်ကစားကာ အောင်မြင်သော ကြိုးပမ်းမှုများအတွက် ဆုလာဘ်ရရှိခြင်းမှ သင်ယူနိုင်သည်။ ဂိမ်းစည်းမျဉ်းများနှင့် ဂိမ်းကို မည်သို့ ပြီးမြောက်ရမည်ဆိုသော ညွှန်ကြားချက်များ ပေးထားရန် မလိုပါ။
မော်ဒယ်များသည် အထွေထွေ ဉာဏ်ရည်တုနှင့် စက်သင်ယူမှု နည်းလမ်းများကို အသုံးပြု၍ ဖွံ့ဖြိုးတိုးတက်စေထားသော ကွန်ပျူတာပရိုဂရမ်များဖြစ်သည်။ အများဆုံးတွေ့ရသော မော်ဒယ်များမှာ ဒေတာကို ခွဲခြမ်းစိတ်ဖြာကာ ထိုဒေတာအပေါ် အခြေခံ၍ အနာဂတ် ခန့်မှန်းချက်များ ပြုလုပ်သော ပရိုဂရမ်များဖြစ်သည်။ ဥပမာအားဖြင့် စျေးဝယ်သူများ၏ ယခင်ဝယ်ယူမှုများကို ခွဲခြမ်းစိတ်ဖြာရန် မော်ဒယ်တစ်ခုကို ဖွံ့ဖြိုးတိုးတက်စေပြီး အနာဂတ် စျေးဝယ်သူတစ်ဦးအတွက် ဝယ်ယူရန် သင့်တော်သော အရာများကို အကြံပြုနိုင်ပါသည်။
Foundation models များသည် ဒေတာအမြောက်အများနှင့် သက်ဆိုင်သော လုပ်ငန်းတာဝန်အမျိုးမျိုးကို ဆောင်ရွက်နိုင်ရန် ဒေတာအမြောက်အများမှ သင်ယူစေရန် ကြီးမားသော ကွန်ပျူတာတွက်ချက်မှုစွမ်းအားကို အသုံးပြု၍ ဖန်တီးထားသော AI မော်ဒယ်များဖြစ်သည်။ ဥပမာအားဖြင့် စာသားအမြောက်အများကို အသုံးပြု၍ ဖန်တီးထားသော ဘာသာစကား မော်ဒယ်တစ်ခုကို စာသားကို ခွဲခြမ်းစိတ်ဖြာရန်၊ ရေးသားရန်နှင့် စာသားနှင့်ပတ်သက်သော မေးခွန်းများကို ဖြေဆိုရန် အသုံးပြုနိုင်သည်။
အထွေထွေ ဉာဏ်ရည်တုနှင့် စက်သင်ယူမှု နယ်ပယ်များသည် အလွန်လျင်မြန်စွာ တိုးတက်နေသဖြင့် ဤအဓိပ္ပာယ်ဖွင့်ဆိုချက်များသည်လည်း အချိန်နှင့်အမျှ ဆက်လက် ပြောင်းလဲနေမည်ဖြစ်သည်။