გაიცანით Codex
ღრუბელზე დაფუძნებული პროგრამული ინჟინერიის აგენტი, რომელსაც მრავალი დავალების პარალელურად შესრულება შეუძლია და რომელსაც codex-1 ამუშავებს. დღეს ხელმისაწვდომია ChatGPT Pro, Business და Enterprise მომხმარებლებისთვის, მალე კი Plus მომხმარებლებისთვისაც.
განახლება 2025 წლის 3 ივნისს: Codex ახლა უკვე ChatGPT Plus მომხმარებლებისთვისაც ხელმისაწვდომია. ასევე მომხმარებლებს ვაძლევთ შესაძლებლობას, დავალების შესრულებისას Codex-ს ინტერნეტთან წვდომა მიაწოდონ. დამატებითი დეტალებისთვის იხილეთ ცვლილებების ჟურნალი(იხსნება ახალ ფანჯარაში) და დოკუმენტაცია(იხსნება ახალ ფანჯარაში).
დღეს ვუშვებთ Codex-ის კვლევით წინასწარ ვერსიას: ღრუბელზე დაფუძნებულ პროგრამული ინჟინერიის აგენტს, რომელსაც მრავალი დავალების პარალელურად შესრულება შეუძლია. Codex-ს შეუძლია თქვენთვის ისეთი დავალებების შესრულება, როგორიცაა ფუნქციების წერა, თქვენს კოდურ ბაზაზე კითხვებზე პასუხი, შეცდომების გამოსწორება და მიმოხილვისთვის შერწყმის მოთხოვნების შეთავაზება; თითოეული დავალება თავის საკუთარ ღრუბლოვან sandbox გარემოში სრულდება, სადაც თქვენი რეპოზიტორიუმი წინასწარაა ჩატვირთული.
Codex-ს ამუშავებს codex-1, OpenAI o3‑ის ვერსია, რომელიც პროგრამული ინჟინერიისთვისაა ოპტიმიზებული. ის რეალური სამყაროს კოდირების დავალებებზე სხვადასხვა გარემოში განამამტკიცებელი სწავლებით გაწვრთნეს, რათა შექმნას კოდი, რომელიც ახლოსაა ადამიანის სტილთან და PR პრეფერენციებთან, ზუსტად მიჰყვება ინსტრუქციებს და შეუძლია იტერაციულად გაუშვას ტესტები, სანამ წარმატებულ შედეგს არ მიიღებს. დღესვე ვიწყებთ Codex-ის ეტაპობრივ მიწოდებას ChatGPT Pro, Enterprise და Business მომხმარებლებისთვის, ხოლო Plus-ისა და Edu-ს მხარდაჭერა მალე დაემატება.
დღეს Codex-ზე წვდომა შეგიძლიათ ChatGPT‑ის გვერდითი პანელიდან და ახალი კოდირების დავალებები მიანიჭოთ მოთხოვნის აკრეფით და „კოდი“-ზე დაჭერით. თუ გსურთ Codex-ს კითხვა დაუსვათ თქვენი კოდური ბაზის შესახებ, დააჭირეთ „კითხვა“-ს. თითოეული დავალება დამოუკიდებლად მუშავდება ცალკე, იზოლირებულ გარემოში, სადაც თქვენი კოდური ბაზა წინასწარაა ჩატვირთული. Codex-ს შეუძლია ფაილების წაკითხვა და რედაქტირება, ასევე ბრძანებების გაშვება, მათ შორის test harness-ების, linter-ებისა და type checker-ების. დავალების დასრულებას, როგორც წესი, 1-დან 30 წუთამდე სჭირდება, სირთულიდან გამომდინარე, და Codex-ის პროგრესის მონიტორინგი რეალურ დროში შეგიძლიათ.
მას შემდეგ, რაც Codex დავალებას დაასრულებს, ის თავის გარემოში ცვლილებებს commit-ს გაუკეთებს. Codex თავისი მოქმედებების გადამოწმებად მტკიცებულებებს გვაწვდის ტერმინალის ლოგებისა და ტესტის შედეგების ციტირებით, რაც საშუალებას გაძლევთ დავალების შესრულებისას გადადგმულ ყოველ ნაბიჯს თვალი მიადევნოთ. შემდეგ შეგიძლიათ შედეგები გადაამოწმოთ, მოითხოვოთ დამატებითი ცვლილებები, გახსნათ GitHub შერწყმის მოთხოვნა ან პირდაპირ მოახდინოთ ცვლილებების ინტეგრაცია თქვენს ლოკალურ გარემოში. პროდუქტში შეგიძლიათ Codex-ის გარემო ისე დააკონფიგურიროთ, რომ რაც შეიძლება მეტად ემთხვეოდეს თქვენს რეალურ დეველოპერულ გარემოს.
Codex-ს შეიძლება უხელმძღვანელონ თქვენს რეპოზიტორიუმში განთავსებულმა AGENTS.md ფაილებმა. ეს ტექსტური ფაილებია, README.md-ის მსგავსი, სადაც შეგიძლიათ აცნობოთ Codex-ს, როგორ მოინახულოს თქვენი კოდური ბაზა, რომელი ბრძანებები გაუშვას ტესტირებისთვის და როგორ დაიცვას საუკეთესოდ თქვენი პროექტის სტანდარტული პრაქტიკები. ადამიან დეველოპერების მსგავსად, Codex აგენტები საუკეთესოდ მუშაობენ მაშინ, როცა მათ მიეწოდებათ კონფიგურირებული dev გარემოები, საიმედო ტესტირების გამართვები და მკაფიო დოკუმენტაცია.
კოდირების შეფასებებსა და შიდა ბენჩმარკებზე codex-1 ძლიერ შედეგებს აჩვენებს AGENTS.md ფაილების ან მორგებული scaffolding-ის გარეშეც.
23 SWE-Bench Verified ნიმუში, რომლებიც ჩვენს შიდა ინფრასტრუქტურაზე გაშვებადი არ იყო, გამორიცხულია. codex-1 გამოიცადა მაქსიმალური 192k token კონტექსტის სიგრძით და საშუალო „მსჯელობის ძალისხმევით“, რაც ის პარამეტრია, რომელიც დღეს პროდუქტში იქნება ხელმისაწვდომი. o3‑ის შეფასებების დეტალებისთვის იხილეთ აქ.
ჩვენი შიდა SWE დავალებების ბენჩმარკი წარმოადგენს OpenAI-ის რეალური შიდა SWE დავალებების კურირებულ ნაკრებს.
ჩვენ Codex-ს ვუშვებთ როგორც კვლევით წინასწარ ვერსიას, ჩვენი ეტაპობრივი დანერგვის სტრატეგიის შესაბამისად. Codex-ის დაპროექტებისას პრიორიტეტად დავაყენეთ უსაფრთხოება და გამჭვირვალობა, რათა მომხმარებლებს შეეძლოთ მისი შედეგების გადამოწმება — დაცვის მექანიზმი, რომელიც სულ უფრო მნიშვნელოვანი ხდება, რადგან AI მოდელები უფრო რთულ კოდირების დავალებებს დამოუკიდებლად ასრულებენ და უსაფრთხოების საკითხები ვითარდება. მომხმარებლებს შეუძლიათ Codex-ის ნამუშევარი შეამოწმონ ციტირებების, ტერმინალის ლოგებისა და ტესტის შედეგების მეშვეობით. როცა Codex აგენტი დარწმუნებული არ არის ან ტესტის ჩავარდნებს აწყდება, ის ამ პრობლემებს აშკარად ატყობინებს, რაც მომხმარებლებს ინფორმირებული გადაწყვეტილების მიღების საშუალებას აძლევს, როგორ გააგრძელონ. მაინც აუცილებელია, რომ მომხმარებლებმა ინტეგრაციასა და გაშვებამდე ხელით გადაამოწმონ და დაადასტურონ აგენტის მიერ გენერირებული მთელი კოდი.
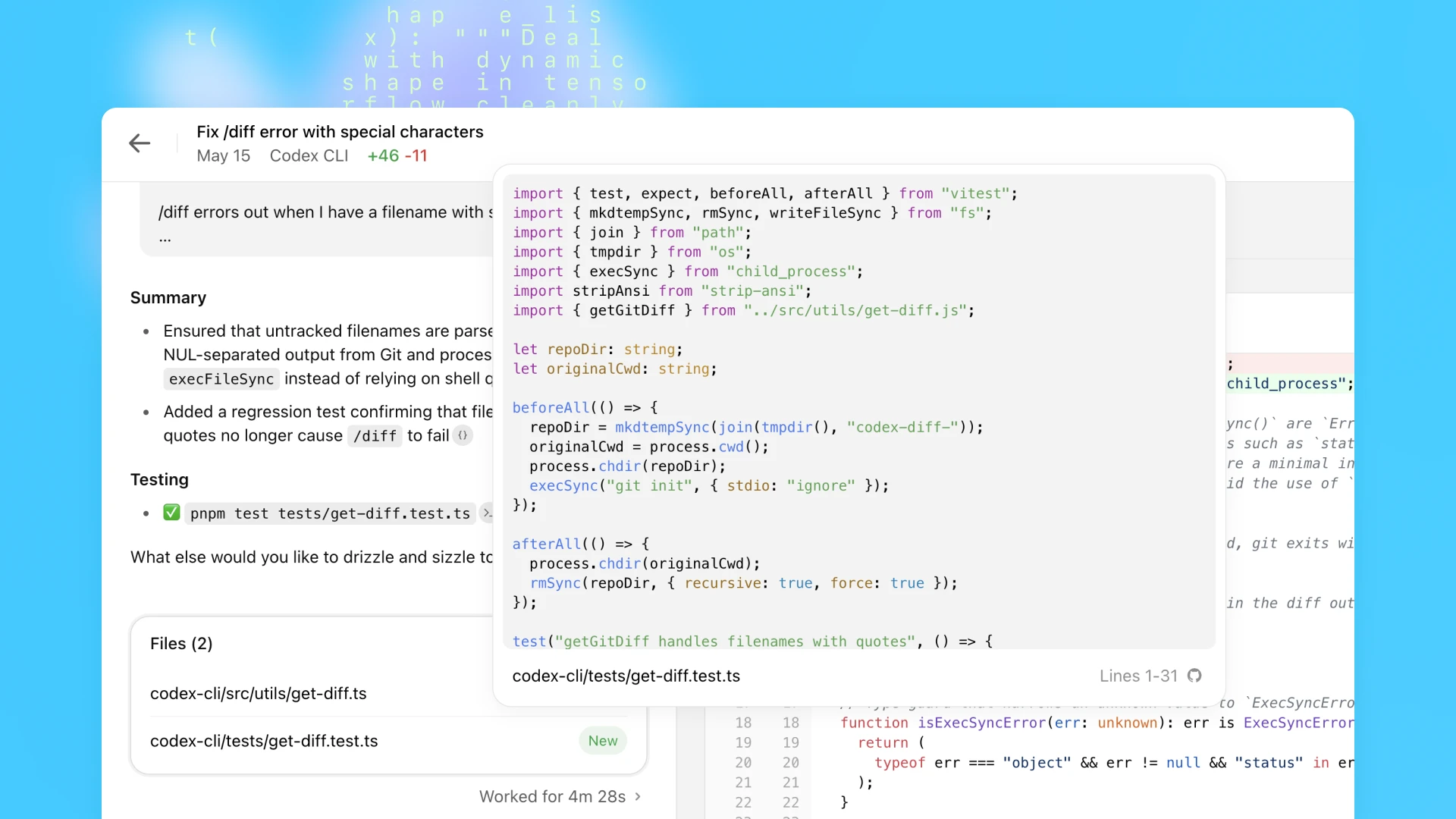
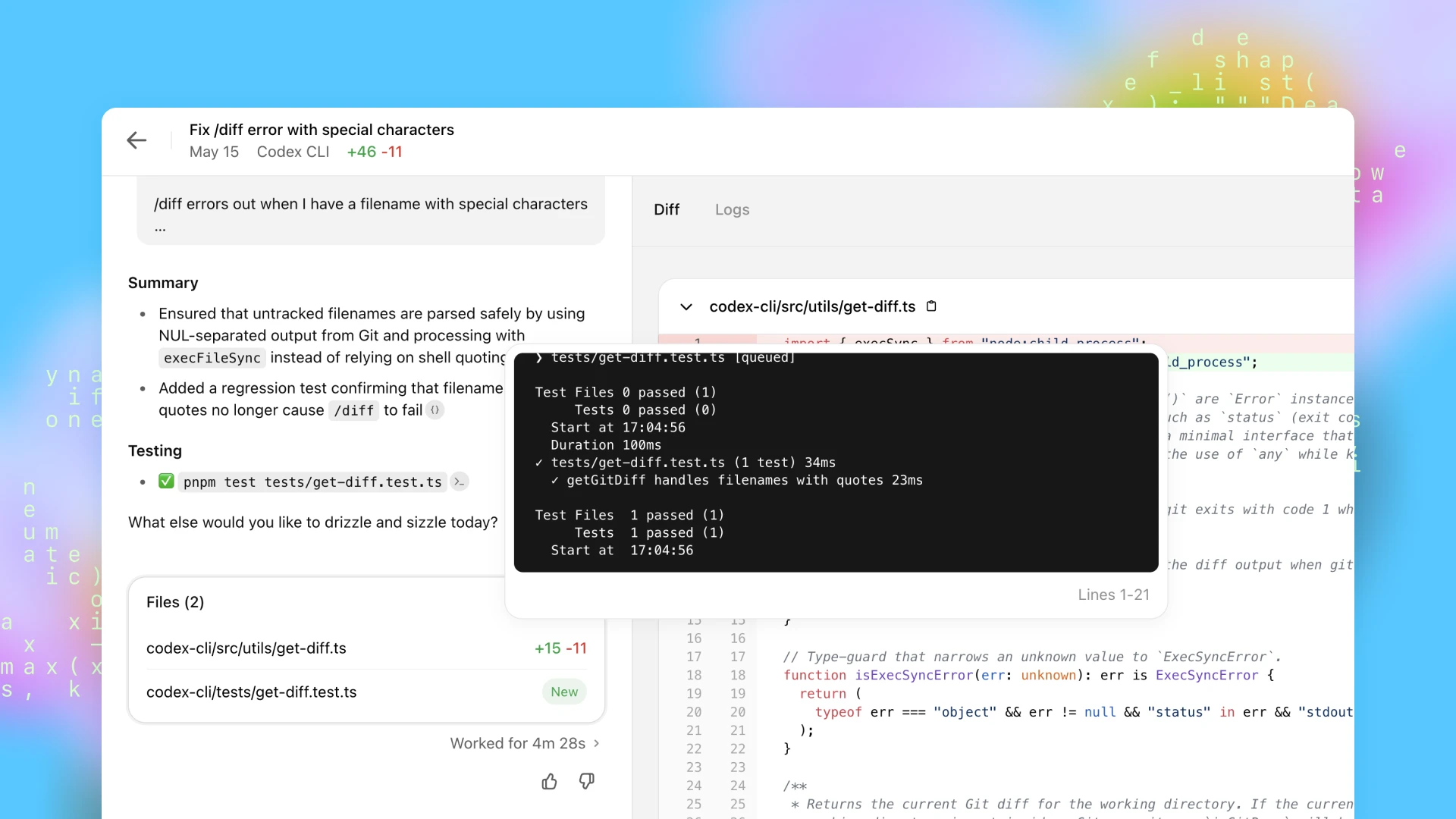
codex-1-ის გაწვრთნისას ერთ-ერთი მთავარი მიზანი იყო შედეგების მაქსიმალურად დაახლოება ადამიანის კოდირების პრეფერენციებსა და სტანდარტებთან. OpenAI o3‑თან შედარებით, codex-1 სტაბილურად აწარმოებს უფრო სუფთა პატჩებს, რომლებიც მზადაა ადამიანური მიმოხილვისა და სტანდარტულ სამუშაო პროცესებში ინტეგრაციისთვის.
ხელოვნური ინტელექტით მართული პროგრამული ინჟინერიის მავნე გამოყენებებისგან, მაგალითად მავნე პროგრამების შექმნისგან, დაცვა სულ უფრო კრიტიკული ხდება. ამავე დროს, მნიშვნელოვანია, რომ დამცავმა ზომებმა ზედმეტად არ შეაფერხოს ლეგიტიმური და სასარგებლო გამოყენებები, რომლებიც შეიძლება მოიცავდეს ისეთ ტექნიკებსაც, რომლებიც ზოგჯერ მავნე პროგრამების განვითარებაშიც გამოიყენება, როგორიცაა დაბალი დონის kernel ინჟინერია.
უსაფრთხოებისა და სარგებლიანობის დასაბალანსებლად, Codex გაწვრთნილი იყო, რომ ამოიცნოს და ზუსტად უარყოს მოთხოვნები, რომლებიც მავნე პროგრამული უზრუნველყოფის განვითარებას ისახავს მიზნად, და ამავე დროს მკაფიოდ გაარჩიოს და მხარი დაუჭიროს ლეგიტიმურ დავალებებს. ჩვენ ასევე გავაძლიერეთ ჩვენი პოლიტიკის ჩარჩოები და ჩავრთეთ მკაცრი უსაფრთხოების შეფასებები, რათა ეს საზღვრები ეფექტიანად გავამყაროთ. ამ შეფასებების ასასახად გამოვაქვეყნეთ o3 სისტემური ბარათის დამატება.
Codex აგენტი მთლიანად ფუნქციონირებს ღრუბელში მდებარე უსაფრთხო, იზოლირებულ კონტეინერში. დავალების შესრულების დროს ინტერნეტთან წვდომა გამორთულია, რაც აგენტის ურთიერთქმედებას ზღუდავს მხოლოდ იმ კოდით, რომელიც ცხადადაა მიწოდებული GitHub რეპოზიტორიუმებით და იმ წინასწარ დაყენებული დამოკიდებულებებით, რომლებიც მომხმარებელმა setup script-ის მეშვეობით დააკონფიგურა. აგენტს არ შეუძლია წვდომა გარე ვებსაიტებზე, API-ებზე ან სხვა სერვისებზე.
OpenAI-ის ტექნიკურმა გუნდებმა დაიწყეს Codex-ის გამოყენება, როგორც მათი ყოველდღიური ინსტრუმენტარიუმის ნაწილის. OpenAI-ის ინჟინრები მას ყველაზე ხშირად იყენებენ განმეორებადი, მკაფიოდ განსაზღვრული დავალებების გადასაბარებლად, როგორიცაა რეფაქტორინგი, სახელების შეცვლა და ტესტების წერა, რომლებიც სხვა შემთხვევაში ფოკუსს დაარღვევდა. ის თანაბრად სასარგებლოა ახალი ფუნქციების ჩონჩხის შესაქმნელად, კომპონენტების დასაკავშირებლად, შეცდომების გამოსასწორებლად და დოკუმენტაციის მონახაზის დასაწერად. გუნდები მის გარშემო ახალ ჩვევებს აყალიბებენ: მორიგეობისას ინციდენტების triage, დღის დასაწყისში დავალებების დაგეგმვა და ფონური სამუშაოს გადაბარება, რათა მოძრაობა არ შეჩერდეს. კონტექსტის ხშირი გადართვის შემცირებით და დავიწყებული to-do-ების გამოჩენით, Codex ეხმარება ინჟინრებს უფრო სწრაფად გამოუშვან და ყურადღება ყველაზე მნიშვნელოვანზე შეინარჩუნონ.
რელიზამდე ჩვენ ასევე ვმუშაობდით გარე ტესტერების მცირე ჯგუფთან, რათა უკეთ გაგვეგო, როგორ მუშაობს Codex მრავალფეროვან კოდურ ბაზებზე, დეველოპერულ პროცესებსა და გუნდებში.
- Cisco(იხსნება ახალ ფანჯარაში) იკვლევს, როგორ შეუძლია Codex-ს დაეხმაროს მათ საინჟინრო გუნდებს ამბიციური იდეების უფრო სწრაფად განხორციელებაში. როგორც ადრეული დიზაინის პარტნიორი, Cisco ეხმარება Codex-ის მომავლის ფორმირებას, აფასებს მას რეალური გამოყენების შემთხვევებისთვის მათი პროდუქტის პორტფელში და OpenAI-ის გუნდს უკუკავშირს აწვდის.
- Temporal(იხსნება ახალ ფანჯარაში) იყენებს Codex-ს ფუნქციების განვითარების დასაჩქარებლად, პრობლემების დასაბაგად, ტესტების დასაწერად და გასაშვებად, ასევე დიდი კოდური ბაზების რეფაქტორინგისთვის. ის ასევე ეხმარება მათ ფოკუსის შენარჩუნებაში რთული დავალებების ფონურად გაშვებით — რაც ინჟინრებს ნაკადში ტოვებს და იტერაციას აჩქარებს.
- Superhuman(იხსნება ახალ ფანჯარაში) იყენებს Codex-ს მცირე, მაგრამ განმეორებადი დავალებების დასაჩქარებლად, როგორიცაა ტესტების დაფარვის გაუმჯობესება და ინტეგრაციის ჩავარდნების გამოსწორება. ის ასევე ეხმარება მათ უფრო სწრაფად გამოშვებაში, რადგან პროდუქტის მენეჯერებს საშუალებას აძლევს შეიტანონ მსუბუქი კოდის ცვლილებები ინჟინრის ჩართვის გარეშე, გარდა კოდის მიმოხილვისა.
- Kodiak(იხსნება ახალ ფანჯარაში) იყენებს Codex-ს დასაბაგი ხელსაწყოების დაწერაში, ტესტების დაფარვის გაუმჯობესებასა და კოდის რეფაქტორინგში დასახმარებლად — რაც აჩქარებს მათი ავტონომიური მართვის ტექნოლოგიის, Kodiak Driver-ის, განვითარებას. Codex ასევე იქცა ღირებულ საცნობარო ინსტრუმენტად, რომელიც ინჟინრებს ეხმარება სტეკის უცნობი ნაწილების გაგებაში შესაბამისი კონტექსტისა და წინა ცვლილებების გამოტანით.
ადრეული ტესტერებისგან მიღებულ გამოცდილებაზე დაყრდნობით, გირჩევთ, რამდენიმე აგენტს ერთდროულად მიანიჭოთ მკაფიოდ განსაზღვრული დავალებები და სხვადასხვა ტიპის დავალებებსა და მოთხოვნებზე ექსპერიმენტი ჩაატაროთ, რათა მოდელის შესაძლებლობები ეფექტიანად გამოიკვლიოთ.
გასულ თვეში გამოვუშვით Codex CLI, მსუბუქი ღია კოდის კოდირების აგენტი, რომელიც თქვენს ტერმინალში მუშაობს. მას თქვენს ლოკალურ სამუშაო პროცესში შემოაქვს ისეთი მოდელების ძალა, როგორიცაა o3 და o4-mini, და ამარტივებს მათთან წყვილში მუშაობას, რათა დავალებები უფრო სწრაფად დაასრულოთ.
დღეს ასევე ვუშვებთ codex-1-ის უფრო მცირე ვერსიას, o4-mini-ის ვერსიას, რომელიც სპეციალურად Codex CLI-ში გამოსაყენებლადაა შექმნილი. ეს ახალი მოდელი CLI-ში უფრო სწრაფ სამუშაო პროცესებს უჭერს მხარს და ოპტიმიზებულია დაბალი დაყოვნების კოდის კითხვა-პასუხისა და რედაქტირებისთვის, ამასთან ინარჩუნებს იმავე სიძლიერეს ინსტრუქციების მიყოლასა და სტილში. ის უკვე ხელმისაწვდომია როგორც ნაგულისხმევი მოდელი Codex CLI-ში და API-ში როგორც codex-mini-latest. საბაზისო snapshot რეგულარულად განახლდება, რადგან Codex-mini მოდელის გაუმჯობესებას ვაგრძელებთ.
ასევე ბევრად ვამარტივებთ თქვენი დეველოპერული ანგარიშის Codex CLI-სთან დაკავშირებას. API token-ის ხელით გენერირებისა და კონფიგურაციის ნაცვლად, ახლა შეგიძლიათ შეხვიდეთ თქვენი ChatGPT ანგარიშით და აირჩიოთ API ორგანიზაცია, რომლის გამოყენებაც გსურთ. API გასაღებს ავტომატურად დავაგენერირებთ და დავაკონფიგურირებთ. გარდა ამისა, Plus და Pro მომხმარებლებს, რომლებიც ChatGPT‑ით შედიან Codex CLI-ში, დღეის მოგვიანებით უკვე შეეძლებათ, შესაბამისად, $5 და $50 უფასო API კრედიტების მიღება მომდევნო 30 დღის განმავლობაში.
დღეიდან Codex-ს ეტაპობრივად ვაწვდით ChatGPT Pro, Enterprise და Business მომხმარებლებს გლობალურად, ხოლო Plus-ისა და Edu-ს მხარდაჭერა მალე დაემატება. მომდევნო კვირების განმავლობაში მომხმარებლებს ექნებათ უხვი წვდომა დამატებითი საფასურის გარეშე, რათა შეძლოთ Codex-ის შესაძლებლობების შესწავლა, რის შემდეგაც დავნერგავთ სიჩქარის ლიმიტებით შეზღუდულ წვდომასა და მოქნილ საფასო ვარიანტებს, რომლებიც მოგცემთ საჭიროებისამებრ დამატებითი გამოყენების შეძენის საშუალებას. ასევე ვგეგმავთ წვდომის გაფართოებას Plus და Edu მომხმარებლებზე უახლოეს მომავალში.
დეველოპერებისთვის, რომლებიც codex-mini-latest-ით ქმნიან, მოდელი ხელმისაწვდომია Responses API-ზე და ფასდება $1.50-ად 1M input token-ზე და $6-ად 1M output token-ზე, 75%-იანი prompt caching ფასდაკლებით.
Codex ჯერ კიდევ განვითარების ადრეულ ეტაპზეა. როგორც კვლევით წინასწარ ვერსიას, მას ამჟამად აკლია ისეთი ფუნქციები, როგორიცაა frontend სამუშაოსთვის სურათის შეყვანები და აგენტის კურსის შესწორების შესაძლებლობა მუშაობის პროცესში. დამატებით, დისტანციურ აგენტზე დელეგირებას ინტერაქტიულ რედაქტირებაზე მეტი დრო სჭირდება, რასაც შეიძლება შეჩვევა დასჭირდეს. დროთა განმავლობაში Codex აგენტებთან ურთიერთობა სულ უფრო დაემსგავსება კოლეგებთან ასინქრონულ თანამშრომლობას. მოდელების შესაძლებლობების წინსვლასთან ერთად, ველით, რომ აგენტები უფრო რთულ დავალებებს უფრო ხანგრძლივ პერიოდში აიღებენ საკუთარ თავზე.
ჩვენ წარმოგვიდგენია მომავალი, სადაც დეველოპერები თავად წარმართავენ იმ სამუშაოს, რომლის ფლობაც სურთ, დანარჩენს კი აგენტებს აბარებენ — AI-ს დახმარებით უფრო სწრაფად მოძრაობენ და უფრო პროდუქტიულები არიან. ამის მისაღწევად ვქმნით Codex-ის ინსტრუმენტების ნაკრებს, რომელიც მხარს უჭერს როგორც რეალურ დროში თანამშრომლობას, ისე ასინქრონულ დელეგირებას.
AI ინსტრუმენტებთან, როგორიცაა Codex CLI და სხვები, დაწყვილება სწრაფად იქცა ინდუსტრიის ნორმად და ეხმარება დეველოპერებს კოდის წერისას უფრო სწრაფად იმოძრაონ. მაგრამ გვჯერა, რომ ChatGPT‑ში Codex-ის მიერ დანერგილი ასინქრონული, მრავალაგენტიანი სამუშაო პროცესი გახდება დე ფაქტო გზა, რომლითაც ინჟინრები მაღალი ხარისხის კოდს შექმნიან.
საბოლოოდ, ჩვენ ამ ურთიერთქმედების ორ რეჟიმს — რეალურ დროში დაწყვილებასა და დავალებების დელეგირებას — დაახლოებულს ვხედავთ. დეველოპერები ითანამშრომლებენ AI აგენტებთან თავიანთ IDE-ებში და ყოველდღიურ ინსტრუმენტებში, რათა დასვან კითხვები, მიიღონ შეთავაზებები და გადაიბარონ გრძელი დავალებები, ყველაფერი ერთიან სამუშაო პროცესში.
მომავლისკენ ვიყურებით და ვგეგმავთ უფრო ინტერაქტიული და მოქნილი აგენტური სამუშაო პროცესების დანერგვას. დეველოპერებს მალე შეეძლებათ დავალების მიმდინარეობისას მისცენ მითითებები, ითანამშრომლონ იმპლემენტაციის სტრატეგიებზე და მიიღონ პროაქტიული პროგრესის განახლებები. ასევე წარმოგვიდგენია უფრო ღრმა ინტეგრაციები იმ ინსტრუმენტებში, რომლებსაც უკვე იყენებთ: დღეს Codex GitHub-ს უკავშირდება, ხოლო მალე დავალებების მინიჭებას Codex CLI-დან, ChatGPT Desktop-იდან ან თუნდაც ისეთი ინსტრუმენტებიდანაც შეძლებთ, როგორიცაა თქვენი issue tracker ან CI სისტემა.
პროგრამული ინჟინერია ერთ-ერთი პირველი ინდუსტრიაა, რომელიც AI-ით მართული პროდუქტიულობის მნიშვნელოვან ზრდას განიცდის, რაც ახალ შესაძლებლობებს ხსნის ინდივიდებისა და მცირე გუნდებისთვის. მიუხედავად იმისა, რომ ამ სარგებლის მიმართ ოპტიმისტურად ვართ განწყობილი, პარტნიორებთანაც ვთანამშრომლობთ, რათა უკეთ გავიგოთ აგენტების ფართო დანერგვის გავლენა დეველოპერების სამუშაო პროცესებზე, უნარების განვითარებაზე სხვადასხვა ადამიანში, კვალიფიკაციის დონესა და გეოგრაფიულ რეგიონებში.
ეს მხოლოდ დასაწყისია — და მოუთმენლად ველით, რას შექმნით Codex-ით.
სისტემური შეტყობინება
ჩვენ ვაზიარებთ codex-1-ის სისტემურ შეტყობინებას, რათა დავეხმაროთ დეველოპერებს გაიგონ მოდელის ნაგულისხმევი ქცევა და მოარგონ Codex ისე, რომ ეფექტურად იმუშაოს მორგებულ სამუშაო პროცესებში. მაგალითად, codex-1-ის სისტემური შეტყობინება Codex-ს უბიძგებს გაუშვას ყველა ტესტი, რომელიც AGENTS.md ფაილშია ნახსენები, მაგრამ თუ დრო არ გყოფნით, შეგიძლიათ Codex-ს სთხოვოთ ამ ტესტების გამოტოვება.