OpenAIની ટેક્નોલોજી સમજાવેલી

OpenAIની સ્થાપના 2015માં એક નોનપ્રોફિટ તરીકે કરવામાં આવી હતી જેથી આર્ટિફિશિયલ જનરલ ઇન્ટેલિજન્સ—ટૂંકમાં, એવી AI જે ઓછામાં ઓછી માનવી જેટલી સમજદાર હોય—સમગ્ર માનવજાતને લાભ આપે. અમે અદ્યતન AI ટેક્નોલોજીનું સંશોધન, વિકાસ અને પ્રકાશન કરીએ છીએ, તેમજ AIની સુરક્ષા, એલાઇન્મેન્ટ અને ગવર્નન્સ માટેના સાધનો અને શ્રેષ્ઠ પ્રથાઓ પણ વિકસાવીએ છીએ. OpenAI આજે પણ અમારી નોનપ્રોફિટ દ્વારા શાસિત છે. અમે નફા કરતાં અમારા મિશનને આગળ રાખીએ છીએ, કર્મચારીઓ અને રોકાણકારો માટેના આર્થિક વળતર મર્યાદિત રાખીએ છીએ, અને મર્યાદા કરતાં ઉપરના ભવિષ્યના નફા અમારી નોનપ્રોફિટને પરત આપીએ છીએ. આ અનન્ય કોર્પોરેટ માળખું અમને અન્ય ટેક્નોલોજી કંપનીઓથી ભિન્ન પ્રેરણાઓ આપે છે. અમારો હેતુ સૌથી વધુ કંઈક વેચવાનો નથી, પરંતુ એવા વિશ્વ તરફ કામ કરવાનો છે જ્યાં દરેકને AIની સામાજિક, આર્થિક અને તકનિકી તકોનો લાભ મળે.
OpenAIના મિશનના ભાગરૂપે, અમે અગ્રણી ફાઉન્ડેશન મોડલો વિકસાવીએ છીએ અને તેમની ક્ષમતાઓને સુરક્ષિત અને લાભદાયી રીતે વિશ્વભરના લોકો(નવી વિન્ડોમાં ખૂલે છે) માટે ઉપલબ્ધ બનાવીએ છીએ. લોકો અમારી મોડલો સુધી પહોંચે તે માટે બે મુખ્ય માર્ગો છે.
- ChatGPT એક એપ છે જે લોકોને અમારી મોડલો સાથે વાતચીતના અંદાજમાં પરસ્પર ક્રિયા કરવાની સગવડ આપે છે. વપરાશકર્તાઓ અમારા ભાષા મોડલોને ટેક્સ્ટ અથવા કોડનું વિશ્લેષણ કરવા અથવા લખવા કહી શકે છે, અથવા અમારા ઇમેજ મોડલોને લખાણના વર્ણનના આધારે ચિત્રો બનાવવા કહી શકે છે. ChatGPT બધા વપરાશકર્તાઓ માટે chatgpt.com(નવી વિન્ડોમાં ખૂલે છે) પર મફતમાં ઉપલબ્ધ છે. વપરાશકર્તાઓ વધારાની સુવિધાઓ અને ક્ષમતાઓ માટે પ્રીમિયમ માસિક સબ્સ્ક્રિપ્શન લઈ શકે છે, અને અમે વ્યવસાયો માટે ખરીદી શકાય એવી એન્ટરપ્રાઇઝ આવૃત્તિ પણ ઓફર કરીએ છીએ.
- અમારી API (Application Programming Interface) ડેવલપરને અમારી મોડલોની ક્ષમતાઓ અને લાભોને તેમની પોતાની એપ્લિકેશનોમાં સંકલિત કરવાની સગવડ આપે છે. Duolingo, Spotify અને Morgan Stanley સહિતની હજારો સંસ્થાઓ અમારી APIનો ઉપયોગ કરીને નવી સુવિધાઓ, એપ્લિકેશનો અને વ્યવસાયો બનાવી રહી છે. Be My Eyes નામની એક ડેનિશ કંપની અમારી APIનો ઉપયોગ અંધ અને ઓછી દૃષ્ટિવાળા વપરાશકર્તાઓને છબીઓ અપલોડ કરવા અને તેના વિશે પ્રશ્નો પૂછવામાં મદદ માટે કરે છે, જેથી તેઓ ભૌતિક પરિસ્થિતિઓમાં વધુ સારી રીતે માર્ગ શોધી શકે અને વધુ સ્વતંત્રતા મેળવી શકે. અમારી API platform.openai.com(નવી વિન્ડોમાં ખૂલે છે) પર ઉપલબ્ધ છે અને ડેવલપર તેનો જેટલો ઉપયોગ કરે તેના આધારે API ઍક્સેસ માટે ચૂકવણી કરે છે.
અમે ChatGPT અને અમારી APIને વ્યાપક સેફ્ટી પગલાંઓ સાથે ઉપલબ્ધ બનાવીએ છીએ, જેમનું વધુ વિગતવાર વર્ણન નીચે આપવામાં આવ્યું છે. અમે ચોક્કસ મોડલો, જેમ કે અમારી speech-to-text મોડલ Whisper અને CLIP નામની અમારી ઇમેજ સમજૂતી મોડલ, આવી રજૂઆતોના સંભવિત જોખમોનું મૂલ્યાંકન કર્યા પછી ઓપન સોર્સ આધાર પર પણ ઉપલબ્ધ બનાવીએ છીએ.
અમે ChatGPTને મફતમાં ઉપલબ્ધ રાખવાનું ચાલુ રાખવા ઇચ્છીએ છીએ અને પ્રીમિયમ સેવાઓ માટે ચૂકવણી કરવાનું પસંદ કરતા વપરાશકર્તાઓ અને વ્યવસાયોમાંથી આવક મેળવશું. વિશાળ-પાયાના ફાઉન્ડેશન મોડલો વિકસાવવાના અને ઓફર કરવાના ઊંચા ખર્ચને ધ્યાનમાં લેતા, અમારી સંસ્થા નફાકારક નથી અને નજીકના ભવિષ્યમાં નફાકારક બનવાની અપેક્ષા પણ રાખતી નથી. અમારો હેતુ સતત એવો જ છે કે AIના લાભો વિશ્વને વ્યાપક અને સુરક્ષિત રીતે ઉપલબ્ધ કરાવવા.
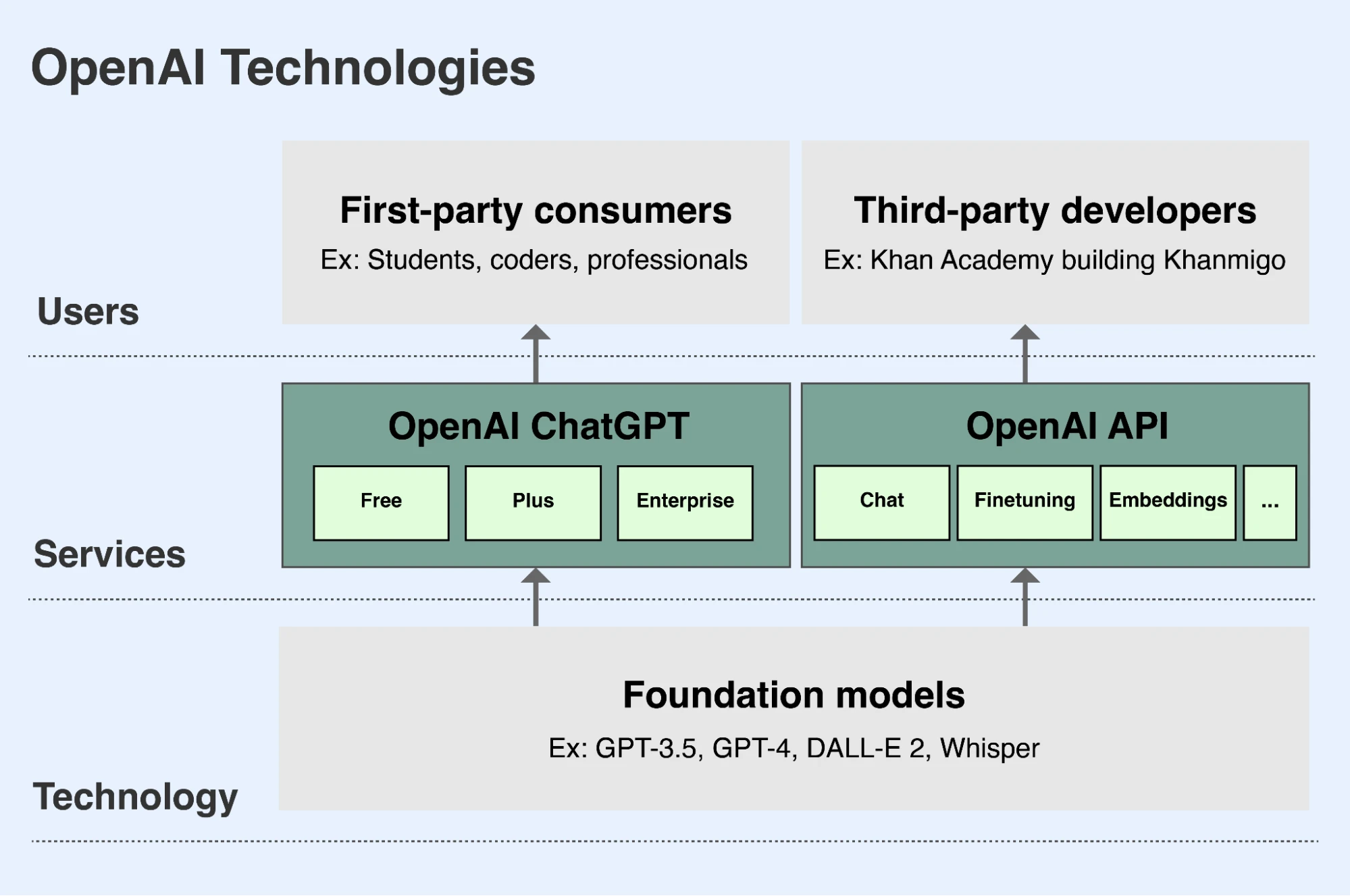
OpenAI અમારા અગ્રણી ફાઉન્ડેશન મોડલો સુધીનો ઍક્સેસ મુખ્યત્વે ChatGPT અને અમારી API દ્વારા ઉપલબ્ધ બનાવે છે.
GPT‑4 જેવા અદ્યતન ભાષા મોડલ વિકસાવવા માટે (1) તેને બુદ્ધિમત્તા શીખવવી પડે છે, જેમ કે અનુમાન કરવાની, તર્ક કરવાની અને સમસ્યાઓ ઉકેલવાની ક્ષમતા, તેમજ (2) તેને માનવીય મૂલ્યો અને પસંદગીઓ સાથે સુસંગત બનાવવું પડે છે. પહેલું કામ “પ્રી-ટ્રેનિંગ” નામની પ્રક્રિયામાં થાય છે, જેમાં મહિનાઓ સુધી મોડલને માનવીય જ્ઞાનનો વિશાળ જથ્થો બતાવવામાં આવે છે. પછી માનવીય પસંદગી મોડલમાં સામેલ કરવા માટે, અમે “પોસ્ટ-ટ્રેનિંગ” નામનું બીજું પગલું વાપરીએ છીએ, જ્યાં અમે મોડલને વધુ સુરક્ષિત અને વધુ ઉપયોગી બનાવીએ છીએ.
પ્રી-ટ્રેનિંગ મોડલને ભાષા શીખવે છે, માટે મોડલને વિવિધ પ્રકારનો વિશાળ ટેક્સ્ટ બતાવવામાં આવે છે અને તેને અતિ વિશાળ શ્રેણીની દરેક અનુક્રમણિકામાં આગળ કયો શબ્દ આવશે તેનો અંદાજ લગાવવાનો પ્રયત્ન કરાવવામાં આવે છે. આ માટે અત્યંત મોટા પ્રમાણમાં કમ્પ્યુટેશન જરૂરી છે, કારણ કે મોડલો લાખો કરોડ શબ્દોની સમીક્ષા કરે છે, વિશ્લેષણ કરે છે અને તેમાંથી શીખે છે. અમે અમારા બેઝ મોડલને ટ્રેન કરવા માટે સુપરકમ્પ્યુટરો બનાવીએ છીએ, અને એક નવું બેઝ મોડલ ટ્રેન કરવું એટલે મહીનાઓ સુધી એક સુપરકમ્પ્યુટર વ્યસ્ત રહી શકે. આ વિસ્તૃત પ્રક્રિયા દ્વારા, મોડલ માત્ર શબ્દો વ્યાકરણ પ્રમાણે કેવી રીતે જોડાય છે તે જ નથી શીખતું, પરંતુ શબ્દો સાથે મળીને ઉચ્ચ સ્તરની કલ્પનાઓ કેવી રીતે બનાવે છે અને અંતે શબ્દોની અનુક્રમણિકા કેવી રીતે ગોઠવાયેલા વિચારો રચે છે અથવા સુસંગત સમસ્યાઓ રજૂ કરે છે તે પણ શીખે છે. ઉદાહરણ તરીકે, જ્યારે આપણે “cloud” શબ્દ વિશે વિચારીએ છીએ, ત્યારે “sky” અને “rain” જેવા સંબંધિત શબ્દો પણ મનમાં આવી શકે. “The secret to happiness is” જેવી વાક્યરચના આપવામાં આવે ત્યારે, આપણે વિવિધ દાર્શનિક વિચારો વિશે વિચારી શકીએ. આગળનો શબ્દ અનુમાન કરવાની પ્રવાહિતા મેળવતાં, મોડલ આ રીતે કલ્પનાઓ અને બુદ્ધિમત્તાના મૂળ ઘટકો શીખે છે.
આ પ્રક્રિયાનું આઉટપુટ—એક બેઝ મોડલ—તેના ટ્રેનિંગ ડેટામાં ન દેખાયેલી નવી સમસ્યાઓ ઉકેલવાની નોંધપાત્ર ક્ષમતા ધરાવે છે, અને તે પણ અનેક ભાષાઓમાં. જોકે, માત્ર બેઝ મોડલ ઉપયોગ માટે તૈયાર નથી. બેઝ મોડલો શક્તિશાળી અને લવચીક હોય છે. તેઓ બુદ્ધિશાળી અને આશ્ચર્યજનક હોય છે, પરંતુ જરૂરી નથી કે ઉપયોગી અથવા સુરક્ષિત પણ હોય.
બેઝ મોડલ સાથે વાતચીત કરવી સહેલી નથી. ઉદાહરણ તરીકે, જો તમે GPT‑4 બેઝ મોડલને “રાજકુમારી વિશે એક વાર્તા લખો…” કહો, તો તે સામાન્ય રીતે વાર્તા નહીં લખે. તેના બદલે, તે તમારું નિવેદન આગળ વધારશે અને તે કેવી રીતે ચાલુ રહે છે તેનો અંદાજ લગાવશે. તે ઉદાહરણ તરીકે આમ આઉટપુટ આપી શકે: “…about a princess who loves horses.” બેઝ મોડલ પાસે અનિચ્છનીય સામગ્રી, જેમ કે દ્વેષપૂર્ણ અથવા હિંસક સામગ્રી, આઉટપુટ ન થાય તે માટેની સુરક્ષા વ્યવસ્થાઓ પણ નથી. અમે અનિચ્છનીય સામગ્રી માટે અમારા પ્રી-ટ્રેનિંગ ડેટાસેટને ફિલ્ટર કરીએ છીએ, છતાં આ નિવારક પગલું મોડલમાં નિશ્ચિત ફેરફાર કરવા માટે પૂરતું સચોટ નથી, અને જો તે મોડલને શું ન કહેવું અથવા કરવું તે સમજવામાં અટકાવે તો ઉલટો પ્રભાવ પણ પેદા કરી શકે. શું ઉપયોગી છે અને શું કહેવું યોગ્ય છે તે સહિત માનવીય મૂલ્યો મોડલોમાં સ્થાપિત કરવા માટે, અમે પોસ્ટ-ટ્રેનિંગ કહેવાતી પ્રક્રિયા માટે એલાઇન્મેન્ટ અને સેફ્ટી તકનીકોનું સંશોધન અને વિકાસ કરીએ છીએ.
પોસ્ટ-ટ્રેનિંગ એ રીતે અમે અમારા મોડલોમાં માનવીય પસંદગી સામેલ કરીએ છીએ અને તેમને ઉપયોગી, અસરકારક અને વધુ સુરક્ષિત સાધનોમાં રૂપાંતરિત કરીએ છીએ. અમે મોડલને એવી રીતે પ્રતિસાદ આપવાનું શીખવીએ છીએ જે લોકોને વધુ ઉપયોગી લાગે, અને એવી રીતે જવાબ આપવાનો ઇનકાર કરવાનું પણ શીખવીએ છીએ જે અમને નુકસાનકારક લાગે. પોસ્ટ-ટ્રેનિંગ માટે સંશોધન, કર્મચારીઓ, ડિઝાઇન પસંદગીઓ અને ડેટા સર્જનમાં નોંધપાત્ર રોકાણ જરૂરી છે. OpenAI માટે આ સંશોધન અને રોકાણનું સક્રિય ક્ષેત્ર છે. અમે એવું પણ માનીએ છીએ કે અમારી કંપનીની બહારના ઘણા લોકો પણ માનવીય મૂલ્યો પ્રતિબિંબિત કરવા માટે ડેટા બનાવવાના અને ડિઝાઇન સંબંધિત નિર્ણયોના કાર્યનો ભાગ બનશે.
પોસ્ટ-ટ્રેનિંગના પરિણામે મોડલમાં લક્ષિત ફેરફારો થાય છે, માટે તુલનાત્મક રીતે નાના અને કાળજીપૂર્વક એન્જિનિયર કરાયેલા ડેટાસેટનો ઉપયોગ થાય છે જે આદર્શ વર્તન દર્શાવે છે. અમે આ માટે લોકોને નમૂનાત્મક જવાબો લખાવીએ છીએ, મોડલ દ્વારા આપવામાં આવેલા જવાબોને રેટ કરાવીએ છીએ, અને પછી તે નમૂનાઓ અને રેટિંગ્સને અનુગામી ટ્રેનિંગ પ્રક્રિયામાં પાછા મોડલને આપીએ છીએ. અમે હ્યુમન ફીડબેકથી રીઇન્ફોર્સમેન્ટ લર્નિંગ (RLHF) સહિત આ તકનીકોમાં આગેવાની લીધી હતી, જે હવે ઉદ્યોગનું ધોરણ બની ગઈ છે. અમે RLHFનો ઉપયોગ મોડલને સૂચનાઓનું પાલન કરવાનું શીખવવા, તે ખોટી સામગ્રી પરત કરે તેની સંભાવના ઘટાડવા અને સેફ્ટી સુવિધાઓ ઉમેરવા માટે કરીએ છીએ.
GPT‑4ને જાહેર રીતે રજૂ કરતાં પહેલાં, અમે પોસ્ટ-ટ્રેનિંગ પર 6 મહિના સુધી પુનરાવર્તન કર્યું. આ સમય દરમિયાન, અમે અમારા મોડલોને એવા અનુરોધોનો જવાબ આપવાથી ઇનકાર કરવાનું શીખવવા માટે તકનીકો વિકસાવી કે જે અમને સંભવિત નુકસાન તરફ દોરી શકે એવું લાગે. ઉદાહરણ તરીકે, જો બોમ્બ કેવી રીતે બનાવવો તેની સૂચનાઓ માંગવામાં આવે, તો મોડલ જવાબ આપવાનો ઇનકાર કરશે. અગાઉની પેઢીના મોડલ GPT‑3.5ની સરખામણીએ, અમારી આંતરિક મૂલ્યાંકનોના આધારે અમે GPT‑4ને પ્રતિબંધિત સામગ્રી માટેના અનુરોધોનો જવાબ આપે તેવી સંભાવના 82% ઓછી બનાવી. અમે આ સમયનો ઉપયોગ તે તથ્યાત્મક પ્રતિસાદ આપે તેવી સંભાવના 40% વધારવા, તેને વાતચીતના અંદાજમાં જવાબ આપવાનું શીખવવા, અને ઓછી સંસાધનવાળી ભાષાઓમાં તેની કામગીરી સુધારવા માટે પણ કર્યો, ઉદાહરણ તરીકે આઇસલેન્ડ સાથેની ભાગીદારીમાં.
અમારા મોડલોમાં માનવીય પસંદગીને વધુ સારી રીતે પ્રતિબિંબિત કરવા માટે અમે પોસ્ટ-ટ્રેનિંગ તકનીકો વિકસાવવાનું(નવી વિન્ડોમાં ખૂલે છે) ચાલુ રાખીએ છીએ. ઉદાહરણ તરીકે, અમારા કેટલાક અભિગમ લોકો માટે સિસ્ટમએ કયા નિયમોનું પાલન કરવું જોઈએ તે વર્ણવવાની શક્તિ આપે છે, વધુ સારું કે નબળું વર્તન ધરાવતા ઉદાહરણોને ગ્રેડ આપવાની જરૂર રહે તેના બદલે.
અમે જાતે જે પોસ્ટ-ટ્રેનિંગ કરીએ છીએ તે ઉપરાંત, અમે ગ્રાહકોને તેમના વિશિષ્ટ હેતુઓ હાંસલ કરવા માટે અમારા મોડલોને “ફાઇન-ટ્યુન” કરવાની ક્ષમતા પણ આપીએ છીએ, જેમ કે તેમની માલિકીની ભાષાઓમાં સોફ્ટવેર કોડ લખાવવું, તેને ઉદ્યોગ-વિશિષ્ટ જ્ઞાન શીખવવું, અથવા તેની શૈલીને તેમની બ્રાન્ડ સાથે સુસંગત બનાવવી. ગ્રાહકો તેઓ હાંસલ કરવા માંગે છે તે વર્તન દર્શાવતા ડેટા તૈયાર કરીને અને અમારી API મારફતે વધારાના પોસ્ટ-ટ્રેનિંગ માટે તેને સબમિટ કરીને એવું કરે છે. જો ડેટા અમારી સેફ્ટી ચકાસણીઓ પસાર કરે, તો પછી અમે તૈયાર થયેલ ફાઇન-ટ્યુન મોડલ માત્ર તે ગ્રાહકને જ ઉપલબ્ધ કરાવીએ છીએ. અન્ય API ટ્રાફિકની જેમ જ, અમે નીચે વર્ણવેલ અમારી મોનિટરિંગ અને ડિટેક્શન સિસ્ટમોનો ઉપયોગ ફાઇન-ટ્યુન મોડલો અમારી ઉપયોગ નીતિઓનું ઉલ્લંઘન કરે છે કે નહીં તે શોધવામાં મદદ માટે કરીએ છીએ.
પોસ્ટ-ટ્રેનિંગ દ્વારા સુરક્ષા ઉપરાંત, અમે કડક પરીક્ષણ કરીએ છીએ, પ્રતિસાદ માટે બાહ્ય નિષ્ણાતોને જોડીએ છીએ, સેફ્ટી અને મોનિટરિંગ સિસ્ટમો બનાવીએ છીએ અને મજબૂત બનાવીએ છીએ, અને લોકોને અમારા મોડલોનો જવાબદારીપૂર્વક ઉપયોગ કરવામાં મદદરૂપ થવા માટે સંસાધનો પ્રદાન કરીએ છીએ. સુરક્ષા પ્રત્યેનો આ સર્વગ્રાહી અભિગમ જ અમને અમારી ઉપયોગ નীতি અમલમાં મૂકવા અને લાગુ કરવાની મંજૂરી આપે છે, જે અમારા મોડલોનો એવો ઉપયોગ પ્રતિબંધિત કરે છે જે નુકસાન પેદા કરી શકે, જેમ કે દ્વેષપૂર્ણ, હેરાનગતિજનક અથવા હિંસક સામગ્રીનું સર્જન, રાજકીય પ્રચાર માટેનો ઉપયોગ, અથવા માલવેર બનાવવાનું.
રેડ-ટીમિંગ અને મૂલ્યાંકન. અમે દરેક મુખ્ય નવા મોડલનું સેફ્ટી જોખમો અને પૂર્વાગ્રહ તથા ભેદભાવ જેવી સંભવિત સામાજિક હાનિ માટે મૂલ્યાંકન કરીએ છીએ. અમે આંતરિક અને બાહ્ય રેડ-ટીમિંગ કરીએ છીએ, જેમાં અમે અંદરથી મોડલનું જોખમો માટે પરીક્ષણ કરીએ છીએ અને વિવિધ ઉદ્યોગોના નિષ્ણાતોને વહેલી ઍક્સેસ આપીએ છીએ જેથી તેઓ સિસ્ટમોની તપાસ કરીને જોખમોની ઓળખ અને મૂલ્યાંકન કરવામાં મદદ કરી શકે. અમે આ મૂલ્યાંકનોનો ઉપયોગ અમારા મોડલો અને સેફ્ટી સિસ્ટમોના વિકાસ અને સુધારાને વધુ માર્ગદર્શન આપવા માટે કરીએ છીએ, અને અમારા નિષ્કર્ષો જાહેર રીતે પ્રકાશિત કરીએ છીએ.
સેફ્ટી મોનિટરિંગ સિસ્ટમો. અમે એવી મોનિટરિંગ સિસ્ટમો બનાવીએ છીએ અને અમલમાં મૂકીએ છીએ જે અનિચ્છનીય સામગ્રી શોધવામાં મદદ કરે અને ચોક્કસ ઘટનાઓની માનવીય સમીક્ષાને પૂરક બને. જ્યારે આ સિસ્ટમો દ્વારા સામગ્રી ઉલ્લંઘન શોધાય છે, ત્યારે અમે વિવિધ પ્રકારની કાર્યવાહી કરી શકીએ છીએ, જેમાં જવાબ આપવાનો ઇનકાર કરવો, ઘટનાને માનવીય સમીક્ષા માટે ફ્લેગ કરવી, અથવા ગંભીર સ્થિતિમાં વપરાશકર્તાને સસ્પેન્ડ કરવો પણ સામેલ છે. કન્ટેન્ટ ક્લાસિફાયર ફાઇન-ટ્યુન કરાયેલા ભાષા મોડલો દ્વારા સંચાલિત છે અને તેમની આવરી લેવાની ક્ષમતા, કાર્યક્ષમતા અને ચોકસાઈ કેવી રીતે વધારવી તે અંગે અમે સંશોધન ચાલુ રાખીએ છીએ, જેમાં તાજેતરમાં મોડરેશન સિસ્ટમો વિકસાવવા માટે GPT‑4 નો ઉપયોગ તપાસ્યો છે.
વપરાશકર્તાઓ માટેના સાધનો. અમે અમારા વપરાશકર્તાઓ અને અમારા મોડલો પર આધારિત એપ્લિકેશનો બનાવતા ડેવલપરો માટે દસ્તાવેજીકરણ અને સાધનો વિકસાવીએ છીએ જેથી તેઓ AIનો સુરક્ષિત રીતે ઉપયોગ કરી શકે. નવા અત્યાધુનિક સિસ્ટમો રજૂ કરતાં પહેલાં, અમે મોડલ અથવા સિસ્ટમની ક્ષમતાઓ, મર્યાદાઓ અને યોગ્ય તથા અયોગ્ય ઉપયોગના ક્ષેત્રો વર્ણવતો અહેવાલ પ્રકાશિત કરીએ છીએ, જેમ કે GPT‑4(નવી વિન્ડોમાં ખૂલે છે) અને GPT‑4V માટેના સિસ્ટમ કાર્ડ. અમે મફત Moderations API(નવી વિન્ડોમાં ખૂલે છે) ઉપલબ્ધ બનાવીએ છીએ જેથી વપરાશકર્તાઓ પોતાની ઉપયોગ નીતિઓ લાગુ કરી શકે. અને અમે અમારી સેફ્ટી સિસ્ટમો પર સંશોધન પ્રકાશિત(નવી વિન્ડોમાં ખૂલે છે) કરીએ છીએ.
પ્રતિસાદમાંથી શીખવું. અમે માનીએ છીએ કે સમય સાથે સુરક્ષિત AI સિસ્ટમો બનાવવામાં અને અમારા મિશનને સાકાર કરવામાં પ્રતિસાદમાંથી શીખવું અને તેના પ્રતિસાદરૂપે કાર્ય કરવું અગત્યનો ભાગ છે. અમે વપરાશકર્તાઓના ઇનપુટ અને પ્રતિસાદના આધારે સતત અમારા મોડલ આઉટપુટ, મોડરેશન સિસ્ટમો અને ઉપયોગ નીતિઓમાં સુધારો કરીએ છીએ. AI ટેક્નોલોજીની સૌથી લાભદાયી અપનાવટ અને અનુકૂલન વિશે અમે હિતધારકો સાથે સતત સંવાદ પણ રાખીએ છીએ.
આર્ટિફિશિયલ ઇન્ટેલિજન્સ કમ્પ્યુટર વિજ્ઞાનની એક શાખા છે, જેનો હેતુ એવી કમ્પ્યુટિંગ સિસ્ટમો બનાવવાનો છે જે સામાન્ય રીતે માનવીય બુદ્ધિમત્તા સાથે જોડાતી રીતે વર્તી શકે. ઉદાહરણોમાં ચેસ જેવી રમતો રમી શકે એવું સોફ્ટવેર, પોતે ચાલતી કારો, અને માનવસમાન વાતચીતનું અનુસરણ કરી શકે એવા ચેટબોટ્સનો સમાવેશ થાય છે.
મશીન લર્નિંગ એ આર્ટિફિશિયલ ઇન્ટેલિજન્સ માટેનો એક અભિગમ છે જેમાં કમ્પ્યુટર સિસ્ટમો માહિતીને આધારે અથવા પ્રયોગ દ્વારા કામ પૂર્ણ કરવાનું શીખી શકે છે, પગલુંદર પગલું પ્રોગ્રામ કરવાને બદલે. ઉદાહરણ તરીકે, મશીન લર્નિંગ સિસ્ટમ બિલાડીનાં વિવિધ ચિત્રો જોઈને અને તે ચિત્રોની લાક્ષણિકતાઓ શીખીને બિલાડીનું ચિત્ર દોરવાનું શીખી શકે, બિલાડી કેવી દેખાય છે તેની લીટીદર લીટી સૂચનાઓ આપવાને બદલે. અથવા, કોઈ સિસ્ટમ વિડિયો ગેમ રમવાની રીત પ્રયોગ કરીને અને સફળ પ્રયત્નો માટે ઇનામ મેળવીને શીખી શકે, ગેમના નિયમો અને ગેમ કેવી રીતે પૂર્ણ કરવી તેની સૂચનાઓ આપવામાં આવે તેના બદલે.
મોડલો કમ્પ્યુટર પ્રોગ્રામ્સ છે જે આર્ટિફિશિયલ ઇન્ટેલિજન્સ અને મશીન લર્નિંગ તકનીકોનો ઉપયોગ કરીને વિકસાવવામાં આવે છે. સૌથી સામાન્ય મોડલો એવા પ્રોગ્રામ્સ છે જે ડેટાનું વિશ્લેષણ કરીને તે ડેટાના આધારે ભવિષ્યવાણી કરે છે. ઉદાહરણ તરીકે, કોઈ મોડલ ખરીદદારો દ્વારા કરવામાં આવેલી ભૂતકાળની ખરીદીઓનું વિશ્લેષણ કરવા માટે વિકસાવવામાં આવી શકે, જેથી ભવિષ્યના ખરીદદારોને ખરીદી માટે ભલામણો કરી શકાય.
ફાઉન્ડેશન મોડલો એવા AI મોડલો છે જે વિશાળ પ્રમાણના ડેટામાંથી શીખવા માટે મોટા પ્રમાણમાં કમ્પ્યુટેશનલ શક્તિનો ઉપયોગ કરીને વિકસાવવામાં આવે છે, જેથી તે ડેટા સંબંધિત અનેક પ્રકારના કાર્યો કરી શકે. ઉદાહરણ તરીકે, મોટા પ્રમાણમાં ટેક્સ્ટનો ઉપયોગ કરીને વિકસાવવામાં આવેલ ભાષા મોડલનો પછી ટેક્સ્ટનું વિશ્લેષણ કરવા, લખવા અને તેના વિશેના પ્રશ્નોના જવાબ આપવા માટે ઉપયોગ કરી શકાય.
આર્ટિફિશિયલ ઇન્ટેલિજન્સ અને મશીન લર્નિંગના ક્ષેત્રો ઝડપથી આગળ વધી રહ્યા છે, તેથી આ વ્યાખ્યાઓ સમય સાથે બદલાતી રહેશે.