Mesurar el rendiment dels nostres models en tasques del món real
Presentem GDPval, una nova avaluació que mesura el rendiment del model en tasques reals i de valor econòmic en 44 ocupacions.
La nostra missió és garantir que la intel·ligència artificial general beneficiï tota la humanitat. Com a part de la nostra missió, volem comunicar amb transparència el progrés sobre com els models d'IA poden ajudar les persones en el món real. Per això presentem GDPval: una nova avaluació dissenyada per ajudar-nos a seguir com de bé rendeixen els nostres models i altres en tasques reals i de valor econòmic. Anomenem aquesta avaluació GDPval perquè vam començar amb el concepte de Producte Interior Brut (PIB) com a indicador econòmic clau i vam extreure tasques de les ocupacions clau dels sectors que més contribueixen al PIB.
La gent sovint especula sobre l'impacte més ampli de la IA en la societat, però la manera més clara d'entendre'n el potencial és mirar què són ja capaços de fer els models. La història mostra que les grans tecnologies —des d'internet fins als telèfons intel·ligents— van trigar més d'una dècada a passar de la invenció a l'adopció generalitzada. Avaluacions com GDPval ajuden a basar les converses sobre futures millores de la IA en proves i no en conjectures, i ens poden ajudar a seguir la millora dels models al llarg del temps.
Les avaluacions prèvies d'IA, com ara proves acadèmiques exigents i reptes competitius de programació, han estat essencials per ampliar els límits de les capacitats de raonament del model, però sovint es queden curtes davant del tipus de tasques que moltes persones fan en la seva feina quotidiana.
Per cobrir aquesta bretxa, hem desenvolupat avaluacions que mesuren capacitats cada cop més realistes i econòmicament rellevants. Aquesta progressió ha anat des de referències acadèmiques clàssiques com MMLU (preguntes tipus examen sobre desenes de matèries), fins a avaluacions més aplicades com SWE-Bench (tasques de correcció d'errors d'enginyeria de programari), MLE-Bench (tasques d'enginyeria d'aprenentatge automàtic com l'entrenament i l'anàlisi de models), i Paper-Bench (raonament científic i crítica d'articles de recerca), i més recentment a avaluacions basades en el mercat com SWE-Lancer (projectes freelance d'enginyeria de programari basats en pagaments reals).
GDPval és el pas següent en aquesta progressió. Mesura el rendiment del model en tasques extretes directament del treball cognitiu real de professionals amb experiència en una àmplia varietat d'ocupacions i sectors, i ofereix una imatge més clara de com rendeixen els models en tasques de valor econòmic. Avaluar models en tasques ocupacionals realistes ens ajuda a entendre no només com rendeixen al laboratori, sinó també com poden donar suport a les persones en la feina que fan cada dia.
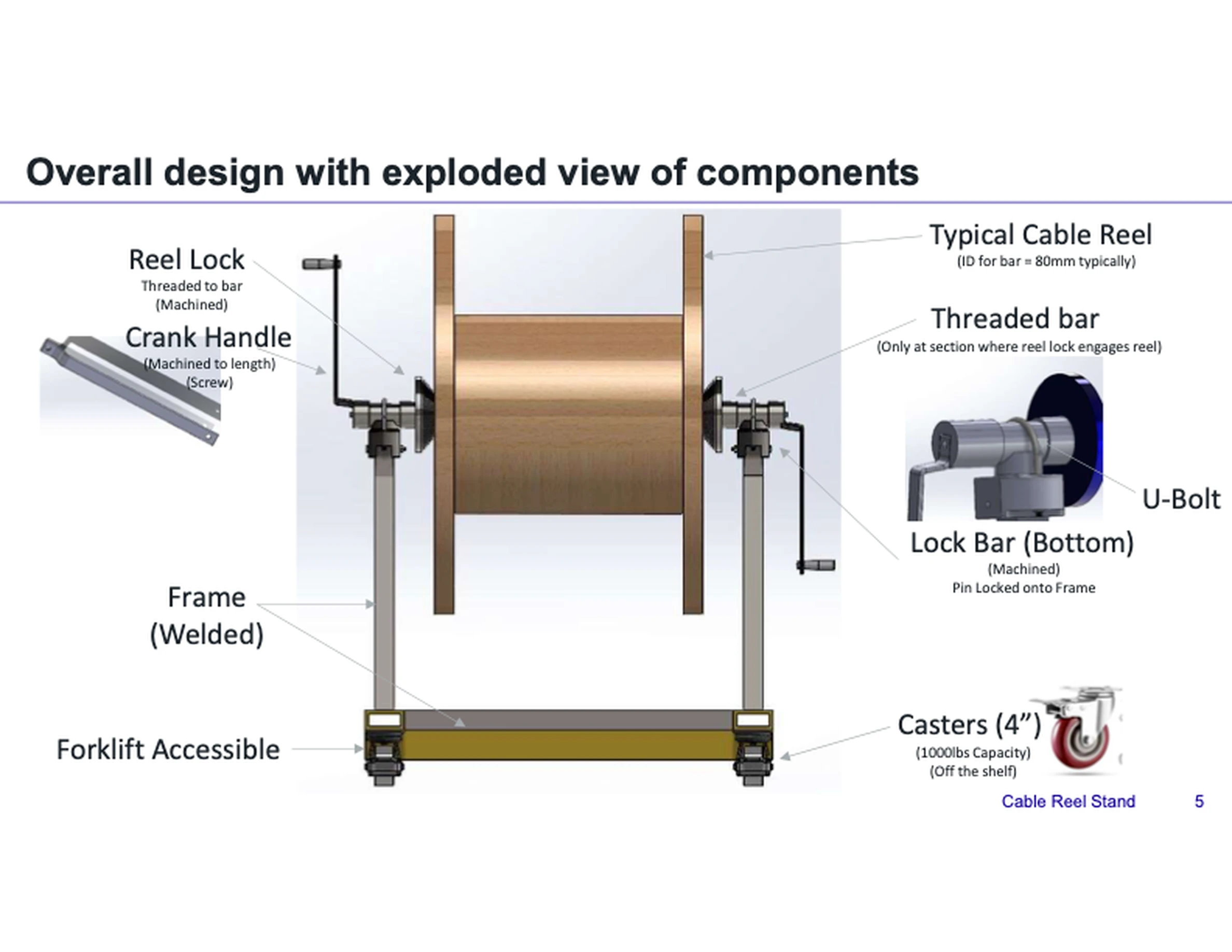
GDPval, la primera versió d'aquesta avaluació, abasta 44 ocupacions seleccionades dels 9 principals sectors que contribueixen al PIB dels EUA. El conjunt complet de GDPval inclou 1.320 tasques especialitzades (220 en el conjunt d'or de codi obert), cadascuna elaborada i revisada meticulosament per professionals amb experiència, amb una mitjana de més de 14 anys d'experiència en aquests camps. Cada tasca es basa en productes de treball reals, com ara un escrit jurídic, un plànol d'enginyeria, una conversa d'atenció al client o un pla d'atenció d'infermeria.
GDPval destaca tant pel realisme com per la diversitat de les tasques avaluades. A diferència d'altres avaluacions vinculades al valor econòmic que es concentren en dominis específics (p. ex., SWE-Lancer), GDPval cobreix moltes tasques i ocupacions. I a diferència de referències que impliquen crear tasques sintèticament a l'estil d'un examen o prova acadèmica (p. ex., Humanity’s Last Exam o MMLU), GDPval se centra en tasques basades en lliurables que són o bé una peça de treball o producte real que existeix avui, o bé una peça de treball construïda de manera similar.
A diferència de les referències tradicionals, les tasques GDPval no són simples indicacions de text. Inclouen fitxers de referència i context, i els lliurables esperats abasten documents, diapositives, diagrames, fulls de càlcul i multimèdia. Aquest realisme fa de GDPval una prova més realista de com els models poden donar suport als professionals.
GDPval és un primer pas que no reflecteix tots els matisos de moltes tasques econòmiques. Tot i que abasta 44 ocupacions i centenars de tasques de treball cognitiu, es limita a avaluacions amb un sol exemple, de manera que no capta els casos en què un model hauria de construir context o millorar a través de diversos esborranys. Les versions futures s'estendran a fluxos de treball més interactius i tasques riques en context per reflectir millor la complexitat del treball cognitiu real (vegeu-ne més a la secció de Limitacions més avall).
GDPval cobreix tasques de 9 sectors i 44 ocupacions, i les versions futures continuaran ampliant la cobertura. Els 9 sectors inicials es van triar entre els que contribueixen amb més del 5% al PIB dels EUA, segons dades del Federal Reserve Bank of St. Louis. Després, vam seleccionar les 5 ocupacions de cada sector que més contribueixen al total de salaris i compensacions i que són predominantment ocupacions de treball cognitiu, utilitzant dades salarials i d'ocupació de l'informe d'ocupació ocupacional de maig de 2024 de l'US Bureau of Labor Statistics (BLS)(s'obre en una finestra nova). Per determinar si les ocupacions eren predominantment de treball cognitiu, vam utilitzar dades de tasques d'O*NET(s'obre en una finestra nova), una base de dades d'informació ocupacional dels EUA patrocinada pel Departament de Treball dels EUA. Vam classificar si cada tasca de cada ocupació a O*NET era treball cognitiu o treball físic/manual (que requereix accions en el món físic). Una ocupació qualificava globalment com a «predominantment de treball cognitiu» si almenys el 60% de les seves tasques components es classificaven com a no implicades en treball físic o manual. Vam triar aquest llindar del 60% com a punt de partida per a la primera versió de GDPval, centrant-nos en ocupacions on la IA podria tenir l'impacte més alt en la productivitat del món real.
Aquest procés va donar com a resultat 44 ocupacions per incloure.
Immobiliari i lloguer i arrendament
Conserges
Gestors de propietats, béns immobles i associacions comunitàries
Agents immobiliaris de vendes
Corredors immobiliaris
Administratius de taulell i de lloguer
Administració pública
Treballadors de lleure
Responsables de compliment normatiu
Supervisors de primera línia de policies i detectius
Directors de serveis administratius
Treballadors socials d'infància, família i escola
Fabricació
Enginyers mecànics
Enginyers industrials
Compradors i agents de compres
Administratius d'enviaments, recepció i inventari
Supervisors de primera línia de treballadors de producció i operacions
Serveis professionals, científics i tècnics
Desenvolupadors de programari
Advocats
Comptables i auditors
Directors de sistemes informàtics i d'informació
Especialistes en gestió de projectes
Assistència sanitària i serveis socials
Infermers titulats
Infermers de pràctica avançada
Directors de serveis mèdics i sanitaris
Supervisors de primera línia de personal d'oficina i suport administratiu
Secretaris mèdics i assistents administratius
Finances i assegurances
Representants d'atenció al client
Analistes financers i d'inversions
Directors financers
Assessors financers personals
Agents de vendes de valors, primeres matèries i serveis financers
Comerç al detall
Farmacèutics
Supervisors de primera línia de treballadors de vendes al detall
Directors generals i d'operacions
Detectius privats i investigadors
Comerç a l'engròs
Directors de vendes
Administratius de comandes
Supervisors de primera línia de treballadors de vendes no minoristes
Representants de vendes, comerç a l'engròs i fabricació, excepte productes tècnics i científics
Representants de vendes, comerç a l'engròs i fabricació, productes tècnics i científics
Informació
Tècnics d'àudio i vídeo
Productors i directors
Analistes de notícies, reporters i periodistes
Editors de cinema i vídeo
Editors
Per a cada ocupació, vam treballar amb professionals amb experiència per crear tasques representatives que reflectissin la seva feina diària. Aquests professionals tenien una mitjana de 14 anys d'experiència, amb sòlids historials de promoció. Vam reclutar deliberadament una àmplia varietat d'experts —com ara advocats de diferents àrees de pràctica i de despatxos de diferents dimensions— per maximitzar la representativitat.
Cada tasca va passar per un procés de revisió de diversos passos per garantir que fos representativa del treball real, factible perquè un altre professional la completés, i clara per a l'avaluació. De mitjana, cada tasca va rebre 5 rondes de revisió experta, incloent-hi comprovacions d'altres redactors de tasques, revisors ocupacionals addicionals i validació basada en models.
El conjunt de dades resultant inclou 30 tasques completament revisades per ocupació (conjunt complet), amb 5 tasques per ocupació en el nostre conjunt d'or de codi obert, i proporciona una base sòlida per avaluar el rendiment del model en treball cognitiu del món real.
Exemples de tasques GDPval
Indicació + context de la tasca
Entregable per humà amb experiència
Per avaluar el rendiment del model en tasques GDPval, ens basem en «avaluadors» experts: un grup de professionals amb experiència de les mateixes ocupacions representades al conjunt de dades. Aquests avaluadors comparen a cegues els lliurables generats pel model amb els produïts pels autors de les tasques (sense saber què és generat per IA i què per humans), i ofereixen crítiques i classificacions. Després, els avaluadors classifiquen els lliurables humans i d'IA i classifiquen cada lliurable d'IA com a «millor», «tan bo com» o «pitjor» que l'altre.
Els autors de les tasques també van crear rúbriques de puntuació detallades per a les seves ocupacions, que aporten coherència i transparència al procés d'avaluació. També vam construir un «avaluador automatitzat», un sistema d'IA entrenat per estimar com jutjarien els experts humans un determinat lliurable. En altres paraules, en lloc de fer una revisió experta completa cada vegada, l'avaluador automatitzat pot predir ràpidament quina sortida probablement preferiria la gent. Publiquem aquesta eina a evals.openai.com com a servei de recerca experimental, però encara no és tan fiable com els avaluadors experts, així que no la fem servir per substituir-los.
Vam trobar que els millors models d'avantguarda actuals ja s'acosten a la qualitat del treball produït per experts del sector. Per posar-ho a prova, vam dur a terme avaluacions a cegues en què experts del sector comparaven lliurables de diversos models líders —GPT‑4o, o4-mini, OpenAI o3, GPT‑5, Claude Opus 4.1, Gemini 2.5 Pro i Grok 4— amb treball produït per humans. En 220 tasques del conjunt d'or de GDPval, vam registrar quan les sortides del model es valoraven com a millors que («victòries») o al nivell («empats») dels lliurables d'experts del sector, tal com es mostra al gràfic de barres següent. Claude Opus 4.1 va ser el model amb millor rendiment del conjunt, especialment en estètica (p. ex., format de documents, disposició de diapositives), i GPT‑5 va destacar especialment en precisió (p. ex., trobar coneixement específic del domini). També observem un progrés clar al llarg del temps en aquestes tasques. El rendiment s'ha més que duplicat de GPT‑4o (publicat la primavera de 2024) a GPT‑5 (publicat l'estiu de 2025), seguint una clara tendència lineal.
A més, vam trobar que els models d'avantguarda poden completar tasques GDPval aproximadament 100 vegades més ràpid i 100 vegades més barat que els experts del sector. Tanmateix, aquestes xifres reflecteixen el temps pur d'inferència del model i les tarifes de facturació de l'API i, per tant, no capten els passos de supervisió humana, iteració i integració necessaris en entorns laborals reals per fer servir els nostres models. Tot i així, especialment en el subconjunt de tasques on els models són particularment forts, esperem que donar una tasca a un model abans de provar-ho amb una persona estalviï temps i diners.
Experts avaluadors van comparar lliurables de models líders amb els d'experts humans. Els models d'avantguarda actuals ja s'acosten a la qualitat del treball produït per experts del sector. Claude Opus 4.1 va produir resultats valorats com a iguals o millors que els humans en poc menys de la meitat de les tasques.
De GPT‑4o a GPT‑5, el rendiment en tasques GDPval es va més que triplicar en un any.
Finalment, vam entrenar incrementalment una versió interna i experimental de GPT‑5 per avaluar si podíem millorar el rendiment a GDPval. Vam veure que aquest procés millorava el rendiment, creant una via per a més millores potencials. Altres experiments controlats ho confirmen: augmentar la mida del model, fomentar més passos de raonament i donar un context de tasca més ric van comportar guanys mesurables.
Podeu llegir els resultats complets al nostre article. També publiquem un subconjunt d'or de tasques GDPval i un servei públic d'avaluació perquè altres investigadors puguin desenvolupar aquest treball.
A mesura que la IA sigui més capaç, probablement provocarà canvis al mercat laboral. Els primers resultats de GDPval mostren que els models ja poden assumir algunes tasques repetitives i ben especificades més ràpidament i amb menys cost que els experts. Tanmateix, la majoria de feines són més que una simple col·lecció de tasques que es poden posar per escrit. GDPval destaca on la IA pot gestionar tasques rutinàries perquè les persones puguin dedicar més temps a les parts creatives i que requereixen judici de la feina. Quan la IA complementa els treballadors d'aquesta manera, això es pot traduir en un creixement econòmic significatiu. El nostre objectiu és mantenir tothom a l'«ascensor cap amunt» de la IA democratitzant l'accés a aquestes eines, donant suport als treballadors durant el canvi i construint sistemes que recompensin una contribució àmplia.
GDPval és un primer pas. Tot i que cobreix 44 ocupacions i centenars de tasques, continuem refinant el nostre enfocament per ampliar l'abast de les nostres proves i fer que els resultats siguin més significatius. La versió actual de l'avaluació també és amb un sol exemple, de manera que no capta els casos en què un model hauria de construir context o millorar a través de diversos esborranys —per exemple, revisar un escrit jurídic després dels comentaris del client o iterar una anàlisi de dades després de detectar una anomalia. A més, en el món real, les tasques no sempre estan clarament definides amb una indicació i fitxers de referència; per exemple, un advocat pot haver de gestionar l'ambigüitat i parlar amb el seu client abans de decidir que crear un escrit jurídic és la millor manera d'ajudar-lo. Tenim previst ampliar GDPval per incloure més ocupacions, sectors i tipus de tasques, amb més interactivitat i més tasques que impliquin gestionar l'ambigüitat, amb l'objectiu a llarg termini de mesurar millor el progrés en treball cognitiu divers.
- Si sou un expert del sector interessat a contribuir a GDPval, mostreu aquí el vostre interès.
- Si sou un client que treballa amb OpenAI i voleu contribuir a una futura ronda de GDPval, expresseu aquí el vostre interès.
La participació de la comunitat és essencial: ens fa il·lusió construir GDPval conjuntament amb investigadors, professionals i organitzacions que comparteixen el nostre objectiu de fer que l'AGI sigui més útil per a les persones a la feina.


