OpenAI ਦੀ ਤਕਨਾਲੋਜੀ ਦੀ ਵਿਆਖਿਆ

OpenAI ਦੀ ਸਥਾਪਨਾ 2015 ਵਿੱਚ ਇੱਕ ਗੈਰ-ਮੁਨਾਫ਼ਾ ਸੰਸਥਾ ਵਜੋਂ ਕੀਤੀ ਗਈ ਸੀ ਤਾਂ ਜੋ ਆਰਟੀਫ਼ਿਸ਼ੀਅਲ ਜਨਰਲ ਇੰਟੈਲੀਜੈਂਸ—ਸੰਖੇਪ ਵਿੱਚ, ਐਸੀ AI ਜੋ ਘੱਟੋ-ਘੱਟ ਇੱਕ ਮਨੁੱਖ ਜਿੰਨੀ ਸਮਾਰਟ ਹੋਵੇ—ਸਾਰੀ ਮਨੁੱਖਤਾ ਦੇ ਹਿਤ ਵਿੱਚ ਕੰਮ ਕਰੇ। ਅਸੀਂ ਅਤਿ-ਆਧੁਨਿਕ AI ਤਕਨਾਲੋਜੀ ਦੇ ਨਾਲ-ਨਾਲ AI ਦੀ ਸੁਰੱਖਿਆ, ਅਲਾਇਨਮੈਂਟ ਅਤੇ ਗਵਰਨੈਂਸ ਲਈ ਟੂਲ ਅਤੇ ਸਭ ਤੋਂ ਵਧੀਆ ਅਭਿਆਸਾਂ ਦੀ ਖੋਜ, ਵਿਕਾਸ ਅਤੇ ਜਾਰੀਕਰਨ ਕਰਦੇ ਹਾਂ। OpenAI ਅੱਜ ਵੀ ਸਾਡੇ ਗੈਰ-ਮੁਨਾਫ਼ਾ ਢਾਂਚੇ ਦੁਆਰਾ ਸ਼ਾਸਿਤ ਹੈ। ਅਸੀਂ ਆਪਣਾ ਮਿਸ਼ਨ ਮੁਨਾਫ਼ੇ ਤੋਂ ਅੱਗੇ ਰੱਖਦੇ ਹਾਂ, ਅਸੀਂ ਕਰਮਚਾਰੀਆਂ ਅਤੇ ਨਿਵੇਸ਼ਕਾਂ ਲਈ ਵਿੱਤੀ ਵਾਪਸੀ 'ਤੇ ਸੀਮਾ ਰੱਖਦੇ ਹਾਂ, ਅਤੇ ਸੀਮਾ ਤੋਂ ਉੱਪਰਲੇ ਭਵਿੱਖੀ ਮੁਨਾਫ਼ੇ ਆਪਣੇ ਗੈਰ-ਮੁਨਾਫ਼ਾ ਨੂੰ ਵਾਪਸ ਕਰਾਂਗੇ। ਇਹ ਵਿਲੱਖਣ ਕਾਰਪੋਰੇਟ ਢਾਂਚਾ ਸਾਨੂੰ ਹੋਰ ਤਕਨਾਲੋਜੀ ਕੰਪਨੀਆਂ ਤੋਂ ਵੱਖਰੇ ਪ੍ਰੇਰਕ ਤੱਤ ਦਿੰਦਾ ਹੈ। ਸਾਡਾ ਮਕਸਦ ਸਭ ਤੋਂ ਵੱਧ ਕੁਝ ਵੀ ਵੇਚਣਾ ਨਹੀਂ, ਸਗੋਂ ਐਸੇ ਸੰਸਾਰ ਵੱਲ ਕੰਮ ਕਰਨਾ ਹੈ ਜਿੱਥੇ ਹਰ ਕੋਈ AI ਦੇ ਸਮਾਜਿਕ, ਆਰਥਿਕ ਅਤੇ ਤਕਨਾਲੋਜੀਕ ਮੌਕਿਆਂ ਤੋਂ ਲਾਭਾਨਵਿਤ ਹੋਵੇ।
OpenAI ਦੇ ਮਿਸ਼ਨ ਦੇ ਹਿੱਸੇ ਵਜੋਂ, ਅਸੀਂ ਅਗੇਤੀ ਫਾਉਂਡੇਸ਼ਨ ਮਾਡਲ ਵਿਕਸਿਤ ਕਰਦੇ ਹਾਂ ਅਤੇ ਉਨ੍ਹਾਂ ਦੀਆਂ ਸਮਰੱਥਾਵਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਅਤੇ ਲਾਭਕਾਰੀ ਢੰਗ ਨਾਲ ਦੁਨੀਆ ਭਰ ਦੇ ਲੋਕਾਂ(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) ਲਈ ਉਪਲਬਧ ਕਰਵਾਉਂਦੇ ਹਾਂ। ਲੋਕ ਸਾਡੇ ਮਾਡਲਾਂ ਤੱਕ ਪਹੁੰਚ ਕਰਨ ਲਈ ਮੁੱਖ ਤੌਰ 'ਤੇ ਦੋ ਤਰੀਕੇ ਵਰਤ ਸਕਦੇ ਹਨ:
- ChatGPT ਇੱਕ ਐਪ ਹੈ ਜੋ ਲੋਕਾਂ ਨੂੰ ਸਾਡੇ ਮਾਡਲਾਂ ਨਾਲ ਗੱਲਬਾਤੀ ਢੰਗ ਵਿੱਚ ਸੰਚਾਰ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ। ਵਰਤੋਂਕਾਰ ਸਾਡੇ ਭਾਸ਼ਾ ਮਾਡਲਾਂ ਨੂੰ ਪਾਠ ਜਾਂ ਕੋਡ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਨ ਜਾਂ ਲਿਖਣ ਲਈ ਕਹਿ ਸਕਦੇ ਹਨ, ਜਾਂ ਸਾਡੇ ਚਿੱਤਰ ਮਾਡਲਾਂ ਨੂੰ ਪਾਠ ਵਰਣਨ ਦੇ ਆਧਾਰ 'ਤੇ ਚਿੱਤਰ ਬਣਾਉਣ ਲਈ ਕਹਿ ਸਕਦੇ ਹਨ। ChatGPT chatgpt.com(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) 'ਤੇ ਸਾਰੇ ਵਰਤੋਂਕਾਰਾਂ ਲਈ ਮੁਫ਼ਤ ਉਪਲਬਧ ਹੈ। ਵਰਤੋਂਕਾਰ ਇੱਕ ਪ੍ਰੀਮੀਅਮ ਮਹੀਨਾਵਾਰ ਸਬਸਕ੍ਰਿਪਸ਼ਨ ਲਈ ਸਾਈਨ ਅੱਪ ਕਰ ਸਕਦੇ ਹਨ ਜੋ ਵਾਧੂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਅਤੇ ਸਮਰੱਥਾਵਾਂ ਉਪਲਬਧ ਕਰਵਾਉਂਦੀ ਹੈ, ਅਤੇ ਅਸੀਂ ਕਾਰੋਬਾਰਾਂ ਲਈ ਖਰੀਦਣ ਵਾਸਤੇ ਇੱਕ ਐਂਟਰਪ੍ਰਾਈਜ਼ ਵਰਜਨ ਵੀ ਦਿੰਦੇ ਹਾਂ।
- ਸਾਡਾ API (ਐਪਲੀਕੇਸ਼ਨ ਪ੍ਰੋਗ੍ਰਾਮਿੰਗ ਇੰਟਰਫੇਸ) ਡਿਵੈਲਪਰਾਂ ਨੂੰ ਸਾਡੇ ਮਾਡਲਾਂ ਦੀਆਂ ਸਮਰੱਥਾਵਾਂ ਅਤੇ ਲਾਭਾਂ ਨੂੰ ਆਪਣੀਆਂ ਐਪਲੀਕੇਸ਼ਨਾਂ ਵਿੱਚ ਏਕੀਕ੍ਰਿਤ ਕਰਨ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ। Duolingo, Spotify ਅਤੇ Morgan Stanley ਸਮੇਤ ਹਜ਼ਾਰਾਂ ਸੰਸਥਾਵਾਂ ਸਾਡੇ API ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਨਵੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ, ਐਪਲੀਕੇਸ਼ਨਾਂ ਅਤੇ ਕਾਰੋਬਾਰ ਤਿਆਰ ਕਰ ਰਹੀਆਂ ਹਨ। Be My Eyes ਨਾਮ ਦੀ ਇੱਕ ਡੈਨਿਸ਼ ਕੰਪਨੀ ਸਾਡੇ API ਦੀ ਵਰਤੋਂ ਅੰਨ੍ਹੇ ਅਤੇ ਘੱਟ ਨਜ਼ਰ ਵਾਲੇ ਵਰਤੋਂਕਾਰਾਂ ਨੂੰ ਚਿੱਤਰ ਅੱਪਲੋਡ ਕਰਨ ਅਤੇ ਉਨ੍ਹਾਂ ਬਾਰੇ ਸਵਾਲ ਪੁੱਛਣ ਵਿੱਚ ਮਦਦ ਲਈ ਕਰਦੀ ਹੈ, ਜਿਸ ਨਾਲ ਉਹਨਾਂ ਨੂੰ ਭੌਤਿਕ ਵਾਤਾਵਰਣ ਵਿੱਚ ਬਿਹਤਰ ਤਰੀਕੇ ਨਾਲ ਰਸਤਾ ਲੱਭਣ ਅਤੇ ਵੱਧ ਸੁਤੰਤਰਤਾ ਪ੍ਰਾਪਤ ਕਰਨ ਵਿੱਚ ਮਦਦ ਮਿਲਦੀ ਹੈ। ਸਾਡਾ API platform.openai.com(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) 'ਤੇ ਉਪਲਬਧ ਹੈ ਅਤੇ ਡਿਵੈਲਪਰ ਇਸਦੀ ਵਰਤੋਂ ਦੇ ਆਧਾਰ 'ਤੇ API ਪਹੁੰਚ ਲਈ ਭੁਗਤਾਨ ਕਰਦੇ ਹਨ।
ਅਸੀਂ ChatGPT ਅਤੇ ਆਪਣੇ API ਨੂੰ ਵਿਸਤ੍ਰਿਤ ਸੁਰੱਖਿਆ ਉਪਾਵਾਂ ਦੇ ਨਾਲ ਉਪਲਬਧ ਕਰਵਾਉਂਦੇ ਹਾਂ, ਜਿਵੇਂ ਹੇਠਾਂ ਹੋਰ ਵੇਰਵਾ ਦਿੱਤਾ ਗਿਆ ਹੈ। ਅਸੀਂ ਕੁਝ ਮਾਡਲ, ਜਿਵੇਂ ਸਾਡਾ ਸਪੀਚ-ਟੂ-ਟੈਕਸਟ ਮਾਡਲ Whisper ਅਤੇ CLIP ਨਾਮਕ ਸਾਡਾ ਇਮੇਜ ਅੰਡਰਸਟੈਂਡਿੰਗ ਮਾਡਲ, ਐਸੀਆਂ ਰਿਲੀਜ਼ਾਂ ਦੇ ਸੰਭਾਵਿਤ ਖਤਰਿਆਂ ਦਾ ਮੁਲਾਂਕਣ ਕਰਨ ਤੋਂ ਬਾਅਦ ਓਪਨ ਸੋਰਸ ਅਧਾਰ 'ਤੇ ਵੀ ਉਪਲਬਧ ਕਰਵਾਉਂਦੇ ਹਾਂ.
ਅਸੀਂ ChatGPT ਨੂੰ ਮੁਫ਼ਤ ਉਪਲਬਧ ਕਰਵਾਉਣਾ ਜਾਰੀ ਰੱਖਣ ਦਾ ਇਰਾਦਾ ਰੱਖਦੇ ਹਾਂ ਅਤੇ ਉਹਨਾਂ ਵਰਤੋਂਕਾਰਾਂ ਅਤੇ ਕਾਰੋਬਾਰਾਂ ਤੋਂ ਆਮਦਨ ਪ੍ਰਾਪਤ ਕਰਾਂਗੇ ਜੋ ਪ੍ਰੀਮੀਅਮ ਸੇਵਾਵਾਂ ਲਈ ਭੁਗਤਾਨ ਕਰਨਾ ਚੁਣਦੇ ਹਨ। ਵੱਡੇ ਪੱਧਰ ਦੇ ਫਾਉਂਡੇਸ਼ਨ ਮਾਡਲ ਵਿਕਸਿਤ ਕਰਨ ਅਤੇ ਉਪਲਬਧ ਕਰਵਾਉਣ ਦੀਆਂ ਉੱਚੀਆਂ ਲਾਗਤਾਂ ਨੂੰ ਦੇਖਦੇ ਹੋਏ, ਸਾਡੀ ਸੰਸਥਾ ਲਾਭਕਾਰੀ ਨਹੀਂ ਹੈ ਅਤੇ ਨਜ਼ਦੀਕੀ ਭਵਿੱਖ ਵਿੱਚ ਲਾਭਕਾਰੀ ਹੋਣ ਦੀ ਉਮੀਦ ਵੀ ਨਹੀਂ ਕਰਦੀ। ਸਾਡਾ ਮਕਸਦ ਅਜੇ ਵੀ AI ਦੇ ਲਾਭਾਂ ਨੂੰ ਵਿਸ਼ਾਲ ਪੱਧਰ 'ਤੇ ਅਤੇ ਸੁਰੱਖਿਅਤ ਤਰੀਕੇ ਨਾਲ ਦੁਨੀਆ ਲਈ ਉਪਲਬਧ ਕਰਵਾਉਣਾ ਹੈ।
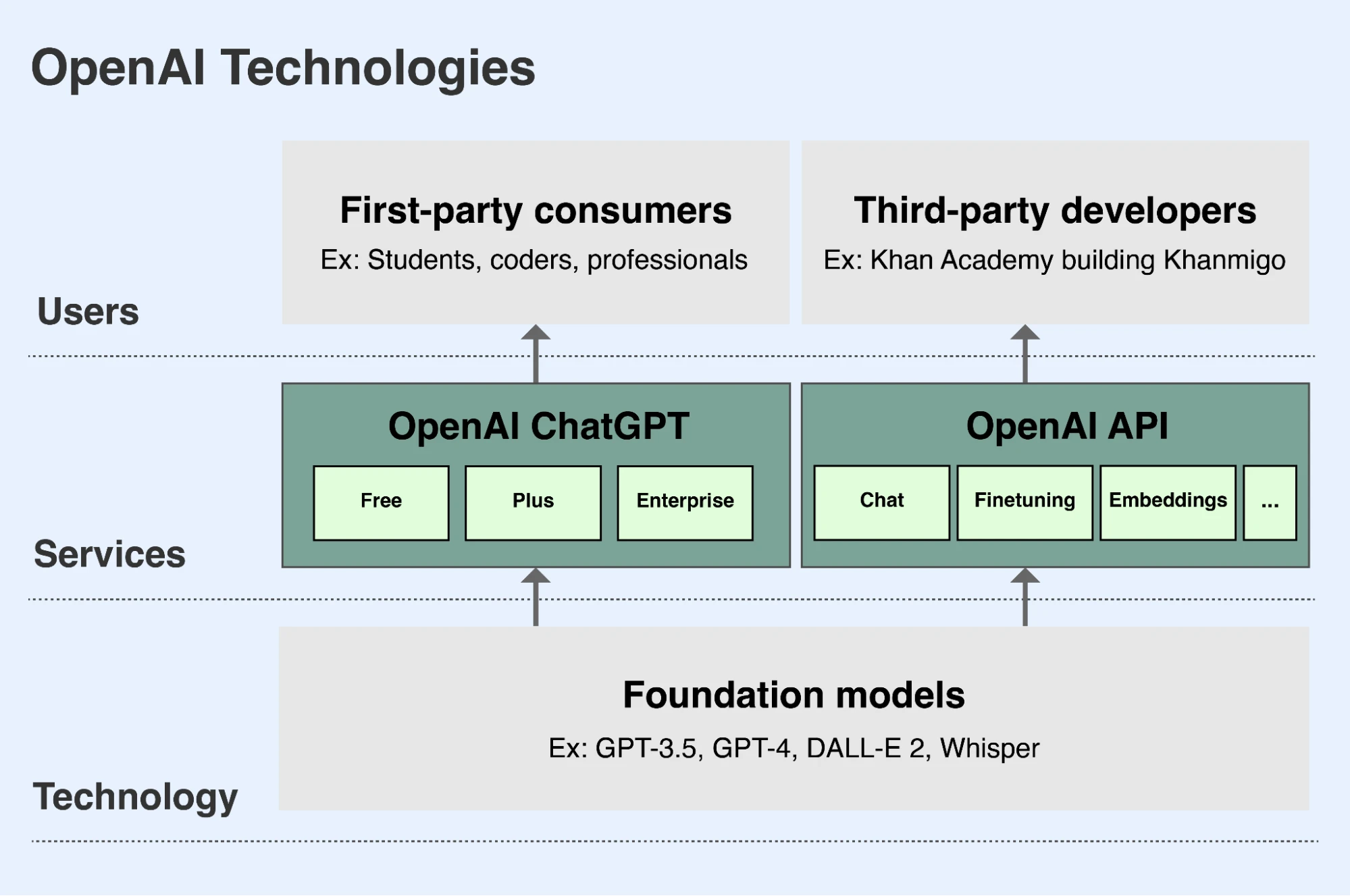
OpenAI ਆਪਣੇ ਅਗੇਤੀ ਫਾਉਂਡੇਸ਼ਨ ਮਾਡਲਾਂ ਤੱਕ ਪਹੁੰਚ ਮੁੱਖ ਤੌਰ 'ਤੇ ChatGPT ਅਤੇ ਆਪਣੇ API ਰਾਹੀਂ ਉਪਲਬਧ ਕਰਵਾਉਂਦਾ ਹੈ।
GPT‑4 ਵਰਗਾ ਇੱਕ ਉੱਨਤ ਭਾਸ਼ਾ ਮਾਡਲ ਵਿਕਸਿਤ ਕਰਨ ਲਈ (1) ਇਸਨੂੰ ਬੁੱਧੀਮਤਾ ਸਿਖਾਉਣੀ ਪੈਂਦੀ ਹੈ, ਜਿਵੇਂ ਅਨੁਮਾਨ ਲਗਾਉਣ, ਤਰਕ ਕਰਨ ਅਤੇ ਸਮੱਸਿਆਵਾਂ ਹੱਲ ਕਰਨ ਦੀ ਸਮਰੱਥਾ, ਅਤੇ ਨਾਲ ਹੀ (2) ਇਸਨੂੰ ਮਨੁੱਖੀ ਮੁੱਲਾਂ ਅਤੇ ਪਸੰਦਾਂ ਨਾਲ ਅਨੁਕੂਲ ਕਰਨਾ ਪੈਂਦਾ ਹੈ। ਪਹਿਲਾ ਕੰਮ “ਪ੍ਰੀ-ਟ੍ਰੇਨਿੰਗ” ਨਾਮਕ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਜਿਸ ਵਿੱਚ ਮਹੀਨਿਆਂ ਤੱਕ ਮਾਡਲ ਨੂੰ ਮਨੁੱਖੀ ਗਿਆਨ ਦੀ ਬਹੁਤ ਵੱਡੀ ਮਾਤਰਾ ਦਿਖਾਈ ਜਾਂਦੀ ਹੈ। ਫਿਰ ਮਾਡਲ ਵਿੱਚ ਮਨੁੱਖੀ ਚੋਣ ਸ਼ਾਮਲ ਕਰਨ ਲਈ, ਅਸੀਂ “ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ” ਨਾਮਕ ਦੂਜਾ ਕਦਮ ਵਰਤਦੇ ਹਾਂ, ਜਿਸ ਵਿੱਚ ਅਸੀਂ ਮਾਡਲ ਨੂੰ ਹੋਰ ਸੁਰੱਖਿਅਤ ਅਤੇ ਵੱਧ ਉਪਯੋਗੀ ਬਣਾਉਂਦੇ ਹਾਂ।
ਪ੍ਰੀ-ਟ੍ਰੇਨਿੰਗ ਮਾਡਲ ਨੂੰ ਭਾਸ਼ਾ ਸਿਖਾਂਦੀ ਹੈ, ਮਾਡਲ ਨੂੰ ਵੱਖ-ਵੱਖ ਕਿਸਮ ਦੇ ਪਾਠ ਦਿਖਾ ਕੇ ਅਤੇ ਇਸ ਤੋਂ ਇਹ ਅਨੁਮਾਨ ਲਗਵਾਕੇ ਕਿ ਬਹੁਤ ਵੱਖਰੀਆਂ ਕ੍ਰਮਬੱਧ ਲੜੀਆਂ ਵਿੱਚ ਅਗਲਾ ਸ਼ਬਦ ਕੀ ਹੋਵੇਗਾ। ਇਸ ਲਈ ਬੇਹੱਦ ਵੱਡੀ ਗਿਣਤੀ ਦੀ ਗਣਨਾ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਕਿਉਂਕਿ ਮਾਡਲ ਖਰਬਾਂ ਸ਼ਬਦਾਂ ਦੀ ਸਮੀਖਿਆ, ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਉਹਨਾਂ ਤੋਂ ਸਿੱਖਦੇ ਹਨ। ਅਸੀਂ ਆਪਣੇ ਬੇਸ ਮਾਡਲਾਂ ਨੂੰ ਟ੍ਰੇਨ ਕਰਨ ਲਈ ਸੁਪਰਕੰਪਿਊਟਰ ਬਣਾਉਂਦੇ ਹਾਂ, ਅਤੇ ਇੱਕ ਨਵੇਂ ਬੇਸ ਮਾਡਲ ਦੀ ਟ੍ਰੇਨਿੰਗ ਇੱਕ ਸੁਪਰਕੰਪਿਊਟਰ ਨੂੰ ਮਹੀਨਿਆਂ ਤੱਕ ਵਿਅਸਤ ਰੱਖ ਸਕਦੀ ਹੈ। ਇਸ ਵਿਸਤ੍ਰਿਤ ਪ੍ਰਕਿਰਿਆ ਰਾਹੀਂ, ਮਾਡਲ ਸਿਰਫ਼ ਇਹ ਨਹੀਂ ਸਿੱਖਦਾ ਕਿ ਸ਼ਬਦ ਵਿਆਕਰਣਕ ਤੌਰ 'ਤੇ ਕਿਵੇਂ ਇਕੱਠੇ ਫਿੱਟ ਹੁੰਦੇ ਹਨ, ਬਲਕਿ ਇਹ ਵੀ ਕਿ ਸ਼ਬਦ ਮਿਲ ਕੇ ਉੱਚ-ਪੱਧਰੀ ਵਿਚਾਰ ਕਿਵੇਂ ਬਣਾਉਂਦੇ ਹਨ, ਅਤੇ ਆਖ਼ਰਕਾਰ ਸ਼ਬਦਾਂ ਦੀਆਂ ਲੜੀਆਂ ਸੰਰਚਿਤ ਵਿਚਾਰ ਕਿਵੇਂ ਬਣਾਉਂਦੀਆਂ ਹਨ ਜਾਂ ਸੰਗਤ ਸਮੱਸਿਆਵਾਂ ਕਿਵੇਂ ਪੇਸ਼ ਕਰਦੀਆਂ ਹਨ। ਉਦਾਹਰਨ ਲਈ, ਜਦੋਂ ਅਸੀਂ “ਬੱਦਲ” ਸ਼ਬਦ ਬਾਰੇ ਸੋਚਦੇ ਹਾਂ, ਤਾਂ ਅਸੀਂ “ਅਸਮਾਨ” ਅਤੇ “ਮੀਹ” ਵਰਗੇ ਸੰਬੰਧਤ ਸ਼ਬਦਾਂ ਬਾਰੇ ਵੀ ਸੋਚ ਸਕਦੇ ਹਾਂ। ਜਦੋਂ ਸਾਨੂੰ “ਖੁਸ਼ੀ ਦਾ ਰਾਜ਼ ਹੈ” ਵਰਗਾ ਵਾਕ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਅਸੀਂ ਵੱਖ-ਵੱਖ ਦਰਸ਼ਨਿਕ ਵਿਚਾਰਾਂ ਬਾਰੇ ਸੋਚ ਸਕਦੇ ਹਾਂ। ਅਗਲੇ ਸ਼ਬਦ ਦਾ ਅਨੁਮਾਨ ਲਗਾਉਣ ਵਿੱਚ ਪ੍ਰਵਾਹਸ਼ੀਲਤਾ ਹਾਸਲ ਕਰਦੇ ਹੋਏ, ਮਾਡਲ ਇਸ ਤਰ੍ਹਾਂ ਧਾਰਣਾਵਾਂ ਅਤੇ ਬੁੱਧੀਮਤਾ ਦੇ ਮੂਲ ਨਿਰਮਾਣ-ਖੰਡ ਸਿੱਖਦਾ ਹੈ.
ਇਸ ਪ੍ਰਕਿਰਿਆ ਦਾ ਨਤੀਜਾ—ਇੱਕ ਬੇਸ ਮਾਡਲ—ਆਪਣੇ ਟ੍ਰੇਨਿੰਗ ਡਾਟਾ ਵਿੱਚ ਨਾ ਵੇਖੀਆਂ ਗਈਆਂ ਨਵੀਆਂ ਸਮੱਸਿਆਵਾਂ ਨੂੰ, ਇੱਥੋਂ ਤੱਕ ਕਿ ਕਈ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਵੀ, ਹੱਲ ਕਰਨ ਦੀ ਸ਼ਾਨਦਾਰ ਸਮਰੱਥਾ ਰੱਖਦਾ ਹੈ। ਹਾਲਾਂਕਿ, ਕੇਵਲ ਬੇਸ ਮਾਡਲ ਹੀ ਵਰਤੋਂ ਲਈ ਤਿਆਰ ਨਹੀਂ ਹੁੰਦਾ। ਬੇਸ ਮਾਡਲ ਸ਼ਕਤੀਸ਼ਾਲੀ ਅਤੇ ਲਚਕੀਲੇ ਹੁੰਦੇ ਹਨ। ਉਹ ਬੁੱਧੀਮਾਨ ਅਤੇ ਹੈਰਾਨ ਕਰਨ ਵਾਲੇ ਹੋ ਸਕਦੇ ਹਨ, ਪਰ ਲਾਜ਼ਮੀ ਨਹੀਂ ਕਿ ਉਹ ਉਪਯੋਗੀ ਜਾਂ ਸੁਰੱਖਿਅਤ ਵੀ ਹੋਣ।
ਬੇਸ ਮਾਡਲ ਨਾਲ ਗੱਲ ਕਰਨਾ ਆਸਾਨ ਨਹੀਂ ਹੁੰਦਾ। ਉਦਾਹਰਨ ਲਈ, ਜੇ ਤੁਸੀਂ GPT‑4 ਬੇਸ ਮਾਡਲ ਨੂੰ ਕਹੋ ਕਿ “ਇੱਕ ਰਾਜਕੁਮਾਰੀ ਬਾਰੇ ਕਹਾਣੀ ਲਿਖੋ…”, ਤਾਂ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਕਹਾਣੀ ਨਹੀਂ ਲਿਖੇਗਾ। ਇਸ ਦੀ ਬਜਾਇ, ਇਹ ਤੁਹਾਡੇ ਵਾਕ ਨੂੰ ਅੱਗੇ ਵਧਾਏਗਾ ਅਤੇ ਅਨੁਮਾਨ ਲਗਾਏਗਾ ਕਿ ਇਹ ਕਿਵੇਂ ਜਾਰੀ ਰਹਿੰਦਾ ਹੈ। ਉਦਾਹਰਨ ਵਜੋਂ, ਇਹ ਇਸ ਤਰ੍ਹਾਂ ਆਉਟਪੁੱਟ ਦੇ ਸਕਦਾ ਹੈ: “…ਇੱਕ ਰਾਜਕੁਮਾਰੀ ਬਾਰੇ ਜੋ ਘੋੜਿਆਂ ਨੂੰ ਪਿਆਰ ਕਰਦੀ ਹੈ।” ਬੇਸ ਮਾਡਲ ਵਿੱਚ ਐਸੀਆਂ ਸੁਰੱਖਿਆ-ਵਿਉਂਤਾਂ ਵੀ ਨਹੀਂ ਹੁੰਦੀਆਂ ਜੋ ਇਸਨੂੰ ਨਫ਼ਰਤਭਰੇ ਜਾਂ ਹਿੰਸਕ ਸਮੱਗਰੀ ਵਰਗਾ ਅਣਚਾਹਾ ਸਮੱਗਰੀ ਤਿਆਰ ਕਰਨ ਤੋਂ ਰੋਕ ਸਕਣ। ਹਾਲਾਂਕਿ ਅਸੀਂ ਅਣਚਾਹੀ ਸਮੱਗਰੀ ਲਈ ਆਪਣੇ ਪ੍ਰੀ-ਟ੍ਰੇਨਿੰਗ ਡਾਟਾਸੈਟ ਨੂੰ ਫਿਲਟਰ ਕਰਦੇ ਹਾਂ, ਇਹ ਰੋਕਥਾਮ ਮਾਡਲ ਵਿੱਚ ਨਿਸ਼ਾਨੇਬੱਧ ਬਦਲਾਅ ਕਰਨ ਲਈ ਬਹੁਤ ਅਣਸਟੀਕ ਹੈ, ਅਤੇ ਇਹ ਉਲਟਾ ਪ੍ਰਭਾਵ ਵੀ ਪਾ ਸਕਦੀ ਹੈ ਜੇ ਇਹ ਮਾਡਲ ਨੂੰ ਇਹ ਸਮਝਣ ਤੋਂ ਰੋਕੇ ਕਿ ਕੀ ਨਹੀਂ ਕਹਿਣਾ ਜਾਂ ਕਰਨਾ ਚਾਹੀਦਾ। ਮਾਡਲਾਂ ਵਿੱਚ ਮਨੁੱਖੀ ਮੁੱਲ ਰੋਪਣ ਲਈ, ਜਿਸ ਵਿੱਚ ਕੀ ਉਪਯੋਗੀ ਹੈ ਅਤੇ ਕੀ ਕਹਿਣਾ ਉਚਿਤ ਹੈ, ਸ਼ਾਮਲ ਹੈ, ਅਸੀਂ ਉਸ ਪ੍ਰਕਿਰਿਆ ਲਈ ਅਲਾਇਨਮੈਂਟ ਅਤੇ ਸੁਰੱਖਿਆ ਤਕਨੀਕਾਂ ਦੀ ਖੋਜ ਅਤੇ ਵਿਕਾਸ ਕਰਦੇ ਹਾਂ ਜਿਸਨੂੰ ਅਸੀਂ ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਕਹਿੰਦੇ ਹਾਂ.
ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਉਹ ਤਰੀਕਾ ਹੈ ਜਿਸ ਰਾਹੀਂ ਅਸੀਂ ਆਪਣੇ ਮਾਡਲਾਂ ਵਿੱਚ ਮਨੁੱਖੀ ਚੋਣ ਨੂੰ ਸ਼ਾਮਲ ਕਰਦੇ ਹਾਂ ਅਤੇ ਉਨ੍ਹਾਂ ਨੂੰ ਉਪਯੋਗੀ, ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਅਤੇ ਹੋਰ ਸੁਰੱਖਿਅਤ ਸਾਧਨਾਂ ਵਿੱਚ ਬਦਲਦੇ ਹਾਂ। ਅਸੀਂ ਮਾਡਲ ਨੂੰ ਇਸ ਤਰ੍ਹਾਂ ਜਵਾਬ ਦੇਣਾ ਸਿਖਾਉਂਦੇ ਹਾਂ ਜੋ ਲੋਕਾਂ ਨੂੰ ਵੱਧ ਉਪਯੋਗੀ ਲੱਗੇ, ਅਤੇ ਉਹਨਾਂ ਤਰੀਕਿਆਂ ਨਾਲ ਜਵਾਬ ਦੇਣ ਤੋਂ ਇਨਕਾਰ ਕਰਨਾ ਵੀ ਸਿਖਾਉਂਦੇ ਹਾਂ ਜਿਨ੍ਹਾਂ ਨੂੰ ਅਸੀਂ ਨੁਕਸਾਨਦਾਇਕ ਮੰਨਦੇ ਹਾਂ। ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਲਈ ਖੋਜ, ਕਰਮਚਾਰੀਆਂ, ਡਿਜ਼ਾਇਨ ਚੋਣਾਂ ਅਤੇ ਡਾਟਾ ਤਿਆਰ ਕਰਨ ਵਿੱਚ ਵੱਡੇ ਨਿਵੇਸ਼ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਇਹ OpenAI ਲਈ ਖੋਜ ਅਤੇ ਨਿਵੇਸ਼ ਦਾ ਇੱਕ ਸਰਗਰਮ ਖੇਤਰ ਹੈ। ਅਸੀਂ ਇਹ ਵੀ ਮੰਨਦੇ ਹਾਂ ਕਿ ਸਾਡੀ ਕੰਪਨੀ ਤੋਂ ਬਾਹਰ ਦੇ ਬਹੁਤ ਸਾਰੇ ਲੋਕ ਵੀ ਮਨੁੱਖੀ ਮੁੱਲਾਂ ਨੂੰ ਦਰਸਾਉਣ ਲਈ ਡਾਟਾ ਬਣਾਉਣ ਅਤੇ ਡਿਜ਼ਾਇਨ ਫੈਸਲੇ ਕਰਨ ਦੇ ਕੰਮ ਦਾ ਹਿੱਸਾ ਹੋਣਗੇ।
ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਮਾਡਲ ਵਿੱਚ ਨਿਸ਼ਾਨੇਬੱਧ ਬਦਲਾਅ ਲਿਆਉਂਦੀ ਹੈ, ਇਸ ਲਈ ਤੁਲਨਾਤਮਕ ਤੌਰ 'ਤੇ ਛੋਟੇ ਅਤੇ ਧਿਆਨ ਨਾਲ ਤਿਆਰ ਕੀਤੇ ਡਾਟਾਸੈਟ ਵਰਤੇ ਜਾਂਦੇ ਹਨ ਜੋ ਆਦਰਸ਼ ਵਿਹਾਰ ਨੂੰ ਦਰਸਾਉਂਦੇ ਹਨ। ਅਸੀਂ ਇਹ ਕੰਮ ਲੋਕਾਂ ਤੋਂ ਨਮੂਨਾ ਜਵਾਬ ਲਿਖਵਾਕੇ ਅਤੇ ਮਾਡਲ ਦੁਆਰਾ ਦਿੱਤੇ ਜਵਾਬਾਂ ਨੂੰ ਦਰਜਾ ਦਿਵਾਕੇ ਕਰਦੇ ਹਾਂ, ਅਤੇ ਫਿਰ ਉਹ ਨਮੂਨੇ ਅਤੇ ਦਰਜੇ ਅਗਲੇ ਟ੍ਰੇਨਿੰਗ ਪ੍ਰਕਿਰਿਆਵਾਂ ਵਿੱਚ ਮਾਡਲ ਨੂੰ ਵਾਪਸ ਦਿੰਦੇ ਹਾਂ। ਅਸੀਂ ਇਹ ਤਕਨੀਕਾਂ ਅਗਵਾਈ ਨਾਲ ਵਿਕਸਿਤ ਕੀਤੀਆਂ, ਜਿਨ੍ਹਾਂ ਵਿੱਚ ਹਿਊਮਨ ਫੀਡਬੈਕ ਤੋਂ ਰੀਇਨਫੋਰਸਮੈਂਟ ਲਰਨਿੰਗ (RLHF) ਵੀ ਸ਼ਾਮਲ ਹੈ, ਜੋ ਹੁਣ ਉਦਯੋਗਕ ਮਿਆਰ ਬਣ ਚੁੱਕੀ ਹੈ। ਅਸੀਂ RLHF ਦੀ ਵਰਤੋਂ ਮਾਡਲ ਨੂੰ ਹਦਾਇਤਾਂ ਦੀ ਪਾਲਣਾ ਸਿਖਾਉਣ, ਗਲਤ ਸਮੱਗਰੀ ਦੇਣ ਦੀ ਸੰਭਾਵਨਾ ਘਟਾਉਣ ਅਤੇ ਸੁਰੱਖਿਆ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਸ਼ਾਮਲ ਕਰਨ ਲਈ ਕਰਦੇ ਹਾਂ।
GPT‑4 ਨੂੰ ਜਨਤਕ ਤੌਰ 'ਤੇ ਜਾਰੀ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਅਸੀਂ ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ 'ਤੇ 6 ਮਹੀਨੇ ਤੱਕ ਦੁਹਰਾਈ ਕਰਦੇ ਰਹੇ। ਇਸ ਸਮੇਂ ਦੌਰਾਨ, ਅਸੀਂ ਆਪਣੇ ਮਾਡਲਾਂ ਨੂੰ ਉਹਨਾਂ ਬੇਨਤੀਆਂ ਦਾ ਜਵਾਬ ਦੇਣ ਤੋਂ ਇਨਕਾਰ ਕਰਨਾ ਸਿਖਾਉਣ ਲਈ ਤਕਨੀਕਾਂ ਵਿਕਸਿਤ ਕੀਤੀਆਂ ਜਿਨ੍ਹਾਂ ਤੋਂ ਸੰਭਾਵਿਤ ਨੁਕਸਾਨ ਹੋ ਸਕਦਾ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਜੇ ਬੰਬ ਬਣਾਉਣ ਦੀਆਂ ਹਦਾਇਤਾਂ ਪੁੱਛੀਆਂ ਜਾਣ, ਤਾਂ ਮਾਡਲ ਜਵਾਬ ਦੇਣ ਤੋਂ ਇਨਕਾਰ ਕਰੇਗਾ। ਅਸੀਂ ਆਪਣੇ ਅੰਦਰੂਨੀ ਮੁਲਾਂਕਣਾਂ ਦੇ ਆਧਾਰ 'ਤੇ GPT‑4 ਨੂੰ ਮਨਾਹੀਸ਼ੁਦਾ ਸਮੱਗਰੀ ਲਈ ਬੇਨਤੀਆਂ ਦਾ ਜਵਾਬ ਦੇਣ ਵਿੱਚ ਪਿਛਲੀ ਪੀੜ੍ਹੀ ਦੇ ਮਾਡਲ GPT‑3.5 ਨਾਲ ਤੁਲਨਾ ਵਿੱਚ 82% ਘੱਟ ਸੰਭਾਵਨਾ ਵਾਲਾ ਬਣਾਇਆ। ਅਸੀਂ ਇਸ ਸਮੇਂ ਦਾ ਵਰਤੋਂ ਇਹ ਸੰਭਾਵਨਾ 40% ਵਧਾਉਣ ਲਈ ਵੀ ਕੀਤਾ ਕਿ ਇਹ ਤੱਥਾਤਮਕ ਜਵਾਬ ਦੇਵੇ, ਇਸਨੂੰ ਗੱਲਬਾਤੀ ਢੰਗ ਨਾਲ ਜਵਾਬ ਦੇਣਾ ਸਿਖਾਉਣ ਲਈ, ਅਤੇ ਘੱਟ-ਸਰੋਤ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਇਸਦੀ ਕਾਰਗੁਜ਼ਾਰੀ ਸੁਧਾਰਨ ਲਈ, ਉਦਾਹਰਨ ਵਜੋਂ ਆਇਸਲੈਂਡ ਨਾਲ ਭਾਗੀਦਾਰੀ ਵਿੱਚ.
ਅਸੀਂ ਆਪਣੇ ਮਾਡਲਾਂ ਵਿੱਚ ਮਨੁੱਖੀ ਚੋਣ ਨੂੰ ਹੋਰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਦਰਸਾਉਣ ਲਈ ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਤਕਨੀਕਾਂ ਦਾ ਵਿਕਾਸ(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) ਜਾਰੀ ਰੱਖਦੇ ਹਾਂ। ਉਦਾਹਰਨ ਲਈ, ਸਾਡੇ ਕੁਝ ਤਰੀਕੇ ਲੋਕਾਂ ਨੂੰ ਇਹ ਵਰਣਨ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ ਕਿ ਸਿਸਟਮ ਨੂੰ ਕਿਹੜੇ ਨਿਯਮ ਮੰਨਣੇ ਚਾਹੀਦੇ ਹਨ, ਬਜਾਇ ਇਸਦੇ ਕਿ ਉਨ੍ਹਾਂ ਨੂੰ ਵਧੀਆ ਜਾਂ ਘੱਟ ਵਧੀਆ ਵਿਹਾਰ ਦੇ ਉਦਾਹਰਨਾਂ ਨੂੰ ਦਰਜਾ ਦੇਣਾ ਪਵੇ।
ਜੋ ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਅਸੀਂ ਖੁਦ ਕਰਦੇ ਹਾਂ, ਉਸ ਤੋਂ ਇਲਾਵਾ, ਅਸੀਂ ਗਾਹਕਾਂ ਨੂੰ ਆਪਣੇ ਮਾਡਲਾਂ ਨੂੰ ਆਪਣੇ ਖ਼ਾਸ ਲੱਖਿਆਂ ਲਈ “ਫਾਈਨ-ਟਿਊਨ” ਕਰਨ ਦੀ ਸਮਰੱਥਾ ਵੀ ਦਿੰਦੇ ਹਾਂ, ਜਿਵੇਂ ਉਨ੍ਹਾਂ ਦੀਆਂ ਮਲਕੀਅਤ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਸਾਫਟਵੇਅਰ ਕੋਡ ਲਿਖਣਾ, ਇਸਨੂੰ ਉਦਯੋਗ-ਵਿਸ਼ੇਸ਼ ਗਿਆਨ ਸਿਖਾਉਣਾ, ਜਾਂ ਇਸਦੀ ਸ਼ੈਲੀ ਨੂੰ ਉਨ੍ਹਾਂ ਦੇ ਬ੍ਰਾਂਡ ਦੇ ਅਨੁਕੂਲ ਕਰਨਾ। ਗਾਹਕ ਇਹ ਕੰਮ ਉਸ ਵਿਹਾਰ ਨੂੰ ਦਰਸਾਉਣ ਵਾਲਾ ਡਾਟਾ ਤਿਆਰ ਕਰਕੇ ਕਰਦੇ ਹਨ ਜਿਸਨੂੰ ਉਹ ਪ੍ਰਾਪਤ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹਨ ਅਤੇ ਸਾਡੇ API ਰਾਹੀਂ ਵਾਧੂ ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਲਈ ਭੇਜਦੇ ਹਨ। ਜੇ ਡਾਟਾ ਸਾਡੀਆਂ ਸੁਰੱਖਿਆ ਜਾਂਚਾਂ ਪਾਰ ਕਰ ਲੈਂਦਾ ਹੈ, ਤਾਂ ਅਸੀਂ ਨਤੀਜੇ ਵਜੋਂ ਬਣਿਆ ਫਾਈਨ-ਟਿਊਨ ਕੀਤਾ ਮਾਡਲ ਕੇਵਲ ਉਸੇ ਗਾਹਕ ਲਈ ਉਪਲਬਧ ਕਰਵਾਉਂਦੇ ਹਾਂ। ਹੋਰ API ਟ੍ਰੈਫਿਕ ਦੀ ਤਰ੍ਹਾਂ, ਅਸੀਂ ਹੇਠਾਂ ਵਰਣਿਤ ਆਪਣੇ ਮਾਨੀਟਰਿੰਗ ਅਤੇ ਡਿਟੈਕਸ਼ਨ ਸਿਸਟਮਾਂ ਦੀ ਵਰਤੋਂ ਇਹ ਪਤਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਲਈ ਕਰਦੇ ਹਾਂ ਕਿ ਫਾਈਨ-ਟਿਊਨ ਕੀਤੇ ਮਾਡਲ ਸਾਡੀਆਂ ਵਰਤੋਂ ਨੀਤੀਆਂ ਦੀ ਉਲੰਘਣਾ ਤਾਂ ਨਹੀਂ ਕਰਦੇ।
ਪੋਸਟ-ਟ੍ਰੇਨਿੰਗ ਰਾਹੀਂ ਸੁਰੱਖਿਆ ਦੇ ਇਲਾਵਾ, ਅਸੀਂ ਕੜੀ ਜਾਂਚ ਕਰਦੇ ਹਾਂ, ਬਾਹਰੀ ਮਾਹਿਰਾਂ ਤੋਂ ਫੀਡਬੈਕ ਲੈਂਦੇ ਹਾਂ, ਸੁਰੱਖਿਆ ਅਤੇ ਮਾਨੀਟਰਿੰਗ ਸਿਸਟਮ ਬਣਾਉਂਦੇ ਅਤੇ ਮਜ਼ਬੂਤ ਕਰਦੇ ਹਾਂ, ਅਤੇ ਲੋਕਾਂ ਨੂੰ ਸਾਡੇ ਮਾਡਲ ਜ਼ਿੰਮੇਵਾਰੀ ਨਾਲ ਵਰਤਣ ਵਿੱਚ ਮਦਦ ਲਈ ਸਰੋਤ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਾਂ। ਸੁਰੱਖਿਆ ਪ੍ਰਤੀ ਇਹ ਸਮੂਹਿਕ ਦ੍ਰਿਸ਼ਟੀਕੋਣ ਹੀ ਸਾਨੂੰ ਵਰਤੋਂ ਨੀਤੀ ਲਾਗੂ ਕਰਨ ਅਤੇ ਇਸਦੀ ਪਾਲਣਾ ਕਰਵਾਉਣ ਦੀ ਸਮਰੱਥਾ ਦਿੰਦਾ ਹੈ, ਜੋ ਸਾਡੇ ਮਾਡਲਾਂ ਨੂੰ ਉਹਨਾਂ ਤਰੀਕਿਆਂ ਨਾਲ ਵਰਤਣ ਤੋਂ ਰੋਕਦੀ ਹੈ ਜਿਨ੍ਹਾਂ ਨਾਲ ਨੁਕਸਾਨ ਹੋ ਸਕਦਾ ਹੈ, ਜਿਵੇਂ ਨਫ਼ਰਤਪੂਰਨ, ਤੰਗ ਕਰਨ ਵਾਲੀ ਜਾਂ ਹਿੰਸਕ ਸਮੱਗਰੀ ਬਣਾਉਣ ਲਈ, ਰਾਜਨੀਤਿਕ ਪ੍ਰਚਾਰ ਲਈ, ਜਾਂ ਮਾਲਵੇਅਰ ਬਣਾਉਣ ਲਈ।
ਰੈੱਡ-ਟੀਮਿੰਗ ਅਤੇ ਮੁਲਾਂਕਣ. ਅਸੀਂ ਹਰ ਮਹੱਤਵਪੂਰਨ ਨਵੇਂ ਮਾਡਲ ਦਾ ਸੁਰੱਖਿਆ ਖਤਰਿਆਂ ਅਤੇ ਪੱਖਪਾਤ ਅਤੇ ਭੇਦਭਾਵ ਵਰਗੇ ਸੰਭਾਵਿਤ ਸਮਾਜਿਕ ਨੁਕਸਾਨਾਂ ਲਈ ਮੁਲਾਂਕਣ ਕਰਦੇ ਹਾਂ। ਅਸੀਂ ਅੰਦਰੂਨੀ ਅਤੇ ਬਾਹਰੀ ਰੈੱਡ-ਟੀਮਿੰਗ ਕਰਦੇ ਹਾਂ, ਜਿਸ ਵਿੱਚ ਅਸੀਂ ਮਾਡਲ ਨੂੰ ਅੰਦਰੂਨੀ ਤੌਰ 'ਤੇ ਖਤਰਿਆਂ ਲਈ ਜਾਂਚਦੇ ਹਾਂ ਅਤੇ ਵੱਖ-ਵੱਖ ਉਦਯੋਗਾਂ ਦੇ ਮਾਹਿਰਾਂ ਨੂੰ ਸ਼ੁਰੂਆਤੀ ਪਹੁੰਚ ਦਿੰਦੇ ਹਾਂ ਤਾਂ ਜੋ ਉਹ ਸਿਸਟਮਾਂ ਦੀ ਜਾਂਚ ਕਰਕੇ ਖਤਰਿਆਂ ਦਾ ਨਕਸ਼ਾ ਤਿਆਰ ਕਰਨ ਅਤੇ ਉਨ੍ਹਾਂ ਦਾ ਮੁਲਾਂਕਣ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਣ। ਅਸੀਂ ਇਨ੍ਹਾਂ ਮੁਲਾਂਕਣਾਂ ਦੀ ਵਰਤੋਂ ਆਪਣੇ ਮਾਡਲਾਂ ਅਤੇ ਸੁਰੱਖਿਆ ਸਿਸਟਮਾਂ ਦੇ ਹੋਰ ਵਿਕਾਸ ਅਤੇ ਸੁਧਾਰ ਲਈ ਰਹਿਨੁਮਾਈ ਵਜੋਂ ਕਰਦੇ ਹਾਂ, ਅਤੇ ਆਪਣੀਆਂ ਖੋਜਾਂ ਜਨਤਕ ਤੌਰ 'ਤੇ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹਾਂ।
ਸੁਰੱਖਿਆ ਮਾਨੀਟਰਿੰਗ ਸਿਸਟਮ. ਅਸੀਂ ਐਸੇ ਮਾਨੀਟਰਿੰਗ ਸਿਸਟਮ ਬਣਾਉਂਦੇ ਅਤੇ ਲਾਗੂ ਕਰਦੇ ਹਾਂ ਜੋ ਅਣਚਾਹੀ ਸਮੱਗਰੀ ਦਾ ਪਤਾ ਲਗਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ ਅਤੇ ਖਾਸ ਘਟਨਾਵਾਂ ਦੀ ਮਨੁੱਖੀ ਸਮੀਖਿਆ ਨੂੰ ਪੂਰਾ ਕਰਦੇ ਹਨ। ਜਦੋਂ ਇਹ ਸਿਸਟਮ ਕਿਸੇ ਸਮੱਗਰੀ ਉਲੰਘਣਾ ਦਾ ਪਤਾ ਲਗਾਉਂਦੇ ਹਨ, ਤਾਂ ਅਸੀਂ ਵੱਖ-ਵੱਖ ਕਾਰਵਾਈਆਂ ਕਰ ਸਕਦੇ ਹਾਂ, ਜਿਵੇਂ ਜਵਾਬ ਦੇਣ ਤੋਂ ਇਨਕਾਰ ਕਰਨਾ, ਘਟਨਾ ਨੂੰ ਮਨੁੱਖੀ ਸਮੀਖਿਆ ਲਈ ਫਲੈਗ ਕਰਨਾ, ਜਾਂ ਗੰਭੀਰ ਮਾਮਲਿਆਂ ਵਿੱਚ ਕਿਸੇ ਵਰਤੋਂਕਾਰ ਨੂੰ ਮੁਅੱਤਲ ਕਰਨਾ। ਸਮੱਗਰੀ ਕਲਾਸੀਫਾਇਰ ਫਾਈਨ-ਟਿਊਨ ਕੀਤੇ ਭਾਸ਼ਾ ਮਾਡਲਾਂ ਦੁਆਰਾ ਚਲਾਏ ਜਾਂਦੇ ਹਨ ਅਤੇ ਅਸੀਂ ਉਨ੍ਹਾਂ ਦੀ ਕਵਰੇਜ, ਦੱਖਲਪਣ ਅਤੇ ਸਹੀਪਣ ਵਧਾਉਣ ਬਾਰੇ ਖੋਜ ਜਾਰੀ ਰੱਖਦੇ ਹਾਂ, ਹਾਲ ਹੀ ਵਿੱਚ ਮਾਡਰੇਸ਼ਨ ਸਿਸਟਮ ਵਿਕਸਿਤ ਕਰਨ ਲਈ GPT‑4 ਦੀ ਵਰਤੋਂ ਦੀ ਖੋਜ ਕਰਦੇ ਹੋਏ.
ਵਰਤੋਂਕਾਰਾਂ ਲਈ ਟੂਲ. ਅਸੀਂ ਆਪਣੇ ਵਰਤੋਂਕਾਰਾਂ ਅਤੇ ਉਹਨਾਂ ਡਿਵੈਲਪਰਾਂ ਲਈ ਦਸਤਾਵੇਜ਼ੀਕਰਨ ਅਤੇ ਟੂਲ ਤਿਆਰ ਕਰਦੇ ਹਾਂ ਜੋ ਸਾਡੇ ਮਾਡਲਾਂ ਦੇ ਉੱਪਰ ਐਪਲੀਕੇਸ਼ਨ ਬਣਾਉਂਦੇ ਹਨ, ਤਾਂ ਜੋ ਉਹ AI ਨੂੰ ਸੁਰੱਖਿਅਤ ਢੰਗ ਨਾਲ ਵਰਤ ਸਕਣ। ਨਵੇਂ ਅਤਿ-ਆਧੁਨਿਕ ਸਿਸਟਮ ਜਾਰੀ ਕਰਨ ਤੋਂ ਪਹਿਲਾਂ, ਅਸੀਂ ਇੱਕ ਰਿਪੋਰਟ ਪ੍ਰਕਾਸ਼ਿਤ ਕਰਦੇ ਹਾਂ ਜੋ ਮਾਡਲ ਜਾਂ ਸਿਸਟਮ ਦੀਆਂ ਸਮਰੱਥਾਵਾਂ, ਸੀਮਾਵਾਂ, ਅਤੇ ਉਚਿਤ ਅਤੇ ਅਣਉਚਿਤ ਵਰਤੋਂ ਦੇ ਖੇਤਰਾਂ ਦਾ ਵੇਰਵਾ ਦਿੰਦੀ ਹੈ, ਉਦਾਹਰਨ ਲਈ GPT‑4(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) ਅਤੇ GPT‑4V ਲਈ ਸਿਸਟਮ ਕਾਰਡ। ਅਸੀਂ ਇੱਕ ਮੁਫ਼ਤ Moderations API(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) ਉਪਲਬਧ ਕਰਵਾਉਂਦੇ ਹਾਂ ਤਾਂ ਜੋ ਵਰਤੋਂਕਾਰ ਆਪਣੀਆਂ ਵਰਤੋਂ ਨੀਤੀਆਂ ਲਾਗੂ ਕਰ ਸਕਣ। ਅਤੇ ਅਸੀਂ ਆਪਣੇ ਸੁਰੱਖਿਆ ਸਿਸਟਮਾਂ ਬਾਰੇ ਖੋਜ ਪ੍ਰਕਾਸ਼ਿਤ(ਨਵੀਂ ਵਿੰਡੋ ਵਿੱਚ ਖੁੱਲ੍ਹਦਾ ਹੈ) ਕਰਦੇ ਹਾਂ।
ਫੀਡਬੈਕ ਤੋਂ ਸਿੱਖਣਾ. ਅਸੀਂ ਮੰਨਦੇ ਹਾਂ ਕਿ ਫੀਡਬੈਕ ਤੋਂ ਸਿੱਖਣਾ ਅਤੇ ਇਸਦਾ ਜਵਾਬ ਦੇਣਾ ਸਮੇਂ ਦੇ ਨਾਲ ਸੁਰੱਖਿਅਤ AI ਸਿਸਟਮ ਬਣਾਉਣ ਅਤੇ ਆਪਣੇ ਮਿਸ਼ਨ ਨੂੰ ਪੂਰਾ ਕਰਨ ਦਾ ਇਕ ਅਤਿ ਮਹੱਤਵਪੂਰਨ ਹਿੱਸਾ ਹੈ। ਅਸੀਂ ਵਰਤੋਂਕਾਰਾਂ ਦੇ ਇਨਪੁੱਟ ਅਤੇ ਫੀਡਬੈਕ ਦੇ ਆਧਾਰ 'ਤੇ ਆਪਣੇ ਮਾਡਲ ਆਉਟਪੁੱਟ, ਮਾਡਰੇਸ਼ਨ ਸਿਸਟਮ ਅਤੇ ਵਰਤੋਂ ਨੀਤੀਆਂ ਵਿੱਚ ਲਗਾਤਾਰ ਸੁਧਾਰ ਕਰਦੇ ਹਾਂ। ਅਸੀਂ AI ਤਕਨਾਲੋਜੀ ਦੀ ਸਭ ਤੋਂ ਲਾਭਕਾਰੀ ਅਪਣਾਉਣ ਅਤੇ ਇਸਦੇ ਅਨੁਕੂਲਨ ਬਾਰੇ ਹਿੱਸੇਦਾਰਾਂ ਨਾਲ ਲਗਾਤਾਰ ਗੱਲਬਾਤ ਵੀ ਕਰਦੇ ਹਾਂ।
ਆਰਟੀਫ਼ਿਸ਼ੀਅਲ ਇੰਟੈਲੀਜੈਂਸ ਕੰਪਿਊਟਰ ਵਿਗਿਆਨ ਦੀ ਇੱਕ ਸ਼ਾਖਾ ਹੈ ਜਿਸਦਾ ਲੱਖ ਐਸੇ ਕੰਪਿਊਟਿੰਗ ਸਿਸਟਮ ਬਣਾਉਣਾ ਹੈ ਜੋ ਮਨੁੱਖੀ ਬੁੱਧੀ ਨਾਲ ਆਮ ਤੌਰ 'ਤੇ ਜੋੜੇ ਜਾਣ ਵਾਲੇ ਢੰਗ ਨਾਲ ਵਿਹਾਰ ਕਰ ਸਕਣ। ਉਦਾਹਰਨਾਂ ਵਿੱਚ ਐਸਾ ਸੌਫਟਵੇਅਰ ਸ਼ਾਮਲ ਹੈ ਜੋ ਸ਼ਤਰੰਜ ਵਰਗੀਆਂ ਖੇਡਾਂ ਖੇਡ ਸਕਦਾ ਹੈ, ਐਸੀਆਂ ਕਾਰਾਂ ਜੋ ਆਪ ਚੱਲ ਸਕਦੀਆਂ ਹਨ, ਅਤੇ ਚੈਟਬਾਟ ਜੋ ਮਨੁੱਖ ਵਰਗੀ ਗੱਲਬਾਤ ਦਾ ਅਨੁਕਰਣ ਕਰ ਸਕਦੇ ਹਨ।
ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਆਰਟੀਫ਼ਿਸ਼ੀਅਲ ਇੰਟੈਲੀਜੈਂਸ ਲਈ ਇੱਕ ਐਸਾ ਤਰੀਕਾ ਹੈ ਜਿਸ ਵਿੱਚ ਕੰਪਿਊਟਰ ਸਿਸਟਮ ਕਦਮ-ਦਰ-ਕਦਮ ਪ੍ਰੋਗਰਾਮ ਕੀਤੇ ਜਾਣ ਦੀ ਬਜਾਇ ਜਾਣਕਾਰੀ ਜਾਂ ਪ੍ਰਯੋਗ ਦੇ ਆਧਾਰ 'ਤੇ ਕੰਮ ਕਰਨਾ ਸਿੱਖ ਸਕਦੇ ਹਨ। ਉਦਾਹਰਨ ਲਈ, ਇੱਕ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਸਿਸਟਮ ਬਿੱਲੀਆਂ ਦੀਆਂ ਵੱਖ-ਵੱਖ ਤਸਵੀਰਾਂ ਵੇਖ ਕੇ ਅਤੇ ਉਹਨਾਂ ਤਸਵੀਰਾਂ ਦੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਸਿੱਖ ਕੇ ਬਿੱਲੀ ਦੀ ਤਸਵੀਰ ਬਣਾਉਣਾ ਸਿੱਖ ਸਕਦਾ ਹੈ, ਇਸ ਦੀ ਥਾਂ ਕਿ ਉਸਨੂੰ ਲਾਈਨ ਦਰ ਲਾਈਨ ਹਦਾਇਤਾਂ ਦਿੱਤੀਆਂ ਜਾਣ ਕਿ ਬਿੱਲੀਆਂ ਕਿਵੇਂ ਦਿਖਦੀਆਂ ਹਨ। ਜਾਂ, ਕੋਈ ਸਿਸਟਮ ਪ੍ਰਯੋਗ ਕਰਕੇ ਅਤੇ ਸਫਲ ਕੋਸ਼ਿਸ਼ਾਂ ਲਈ ਇਨਾਮ ਪਾਕੇ ਵੀਡੀਓ ਗੇਮ ਖੇਡਣਾ ਸਿੱਖ ਸਕਦਾ ਹੈ, ਇਸ ਦੀ ਥਾਂ ਕਿ ਉਸਨੂੰ ਗੇਮ ਦੇ ਨਿਯਮ ਅਤੇ ਗੇਮ ਪੂਰੀ ਕਰਨ ਦੀਆਂ ਹਦਾਇਤਾਂ ਦਿੱਤੀਆਂ ਜਾਣ।
ਮਾਡਲ ਉਹ ਕੰਪਿਊਟਰ ਪ੍ਰੋਗਰਾਮ ਹਨ ਜੋ ਆਰਟੀਫ਼ਿਸ਼ੀਅਲ ਇੰਟੈਲੀਜੈਂਸ ਅਤੇ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਤਕਨੀਕਾਂ ਦੀ ਵਰਤੋਂ ਨਾਲ ਵਿਕਸਿਤ ਕੀਤੇ ਜਾਂਦੇ ਹਨ। ਸਭ ਤੋਂ ਆਮ ਮਾਡਲ ਉਹ ਪ੍ਰੋਗਰਾਮ ਹਨ ਜੋ ਡਾਟਾ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਦੇ ਹਨ ਤਾਂ ਜੋ ਉਸ ਡਾਟਾ ਦੇ ਆਧਾਰ 'ਤੇ ਭਵਿੱਖੀ ਅਨੁਮਾਨ ਲਗਾ ਸਕਣ। ਉਦਾਹਰਨ ਲਈ, ਇੱਕ ਮਾਡਲ ਖਰੀਦਦਾਰਾਂ ਦੁਆਰਾ ਕੀਤੀਆਂ ਇਤਿਹਾਸਕ ਖਰੀਦਾਂ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਨ ਲਈ ਵਿਕਸਿਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਤਾਂ ਜੋ ਭਵਿੱਖ ਦੇ ਕਿਸੇ ਖਰੀਦਦਾਰ ਨੂੰ ਖਰੀਦਾਂ ਦੀ ਸਿਫ਼ਾਰਸ਼ ਕੀਤੀ ਜਾ ਸਕੇ।
ਫਾਉਂਡੇਸ਼ਨ ਮਾਡਲ ਉਹ AI ਮਾਡਲ ਹਨ ਜੋ ਵੱਡੀ ਮਾਤਰਾ ਦੇ ਡਾਟਾ ਤੋਂ ਸਿੱਖਣ ਲਈ ਬਹੁਤ ਵੱਧ ਗਣਨਾਤਮਕ ਸ਼ਕਤੀ ਦੀ ਵਰਤੋਂ ਨਾਲ ਵਿਕਸਿਤ ਕੀਤੇ ਜਾਂਦੇ ਹਨ, ਤਾਂ ਜੋ ਉਸ ਡਾਟਾ ਨਾਲ ਸੰਬੰਧਿਤ ਵਿਸ਼ਾਲ ਸ਼੍ਰੇਣੀ ਦੇ ਕੰਮ ਕੀਤੇ ਜਾ ਸਕਣ। ਉਦਾਹਰਨ ਲਈ, ਵੱਡੀ ਮਾਤਰਾ ਦੇ ਪਾਠ ਨਾਲ ਵਿਕਸਿਤ ਕੀਤਾ ਗਿਆ ਇੱਕ ਭਾਸ਼ਾ ਮਾਡਲ ਫਿਰ ਪਾਠ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਨ, ਲਿਖਣ ਅਤੇ ਇਸ ਬਾਰੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣ ਲਈ ਵਰਤਿਆ ਜਾ ਸਕਦਾ ਹੈ।
ਆਰਟੀਫ਼ਿਸ਼ੀਅਲ ਇੰਟੈਲੀਜੈਂਸ ਅਤੇ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਦੇ ਖੇਤਰ ਤੇਜ਼ੀ ਨਾਲ ਅੱਗੇ ਵੱਧ ਰਹੇ ਹਨ, ਇਸ ਲਈ ਇਹ ਪਰਿਭਾਸ਼ਾਵਾਂ ਸਮੇਂ ਦੇ ਨਾਲ ਬਦਲਦੀਆਂ ਰਹਿਣਗੀਆਂ।