OpenAI-ის ტექნოლოგია ახსნილია

OpenAI 2015 წელს არაკომერციულ ორგანიზაციად შეიქმნა, რათა უზრუნველეყო, რომ ზოგადი ხელოვნური ინტელექტი — მოკლედ, AI, რომელიც სულ მცირე ადამიანის დონეზე ჭკვიანია — მთელი კაცობრიობის სასარგებლოდ გამოიყენებოდეს. ჩვენ ვიკვლევთ, ვავითარებთ და ვუშვებთ მოწინავე AI ტექნოლოგიას, ასევე AI-ის უსაფრთხოების, მორგებისა და მართვის ინსტრუმენტებსა და საუკეთესო პრაქტიკებს. OpenAI დღესაც ჩვენი არაკომერციული სტრუქტურის მიერ იმართება: მისიას მოგებაზე წინ ვაყენებთ, თანამშრომლებისა და ინვესტორების ფინანსურ შემოსავალს ვზღუდავთ, და ამ ზღვარს ზემოთ მომავალ მოგებას ჩვენს არაკომერციულ ორგანიზაციას დავუბრუნებთ. ეს უნიკალური კორპორაციული სტრუქტურა გვაძლევს განსხვავებულ სტიმულებს სხვა ტექნოლოგიურ კომპანიებთან შედარებით. ჩვენი მიზანი არ არის ყველაზე მეტის გაყიდვა, არამედ ისეთი სამყაროსკენ მუშაობა, სადაც ყველა სარგებლობს AI-ის სოციალური, ეკონომიკური და ტექნოლოგიური შესაძლებლობებით.
OpenAI-ის მისიის ფარგლებში, ჩვენ ვავითარებთ წამყვან ფუნდამენტურ მოდელებს და მათ შესაძლებლობებს უსაფრთხო და სასარგებლო გზებით ხელმისაწვდომს ვხდით მსოფლიოს გარშემო ადამიანებისთვის(იხსნება ახალ ფანჯარაში). არსებობს ორი მთავარი გზა, რომლითაც ადამიანებს შეუძლიათ ჩვენს მოდელებზე წვდომა:
- ChatGPT არის აპი, რომელიც ადამიანებს საშუალებას აძლევს ჩვენს მოდელებთან სასაუბრო ფორმით იურთიერთონ. მომხმარებლებს შეუძლიათ ჩვენს ენობრივ მოდელებს სთხოვონ ტექსტის ან კოდის ანალიზი ან დაწერა, ან ჩვენს გამოსახულების მოდელებს სთხოვონ ტექსტური აღწერის საფუძველზე სურათების შექმნა. ChatGPT უფასოდ ხელმისაწვდომია ყველა მომხმარებლისთვის მისამართზე chatgpt.com(იხსნება ახალ ფანჯარაში). მომხმარებლებს შეუძლიათ გამოიწერონ ფასიანი თვიური გამოწერა, რომელიც დამატებით ფუნქციებსა და შესაძლებლობებს ხდის ხელმისაწვდომს, ასევე კომპანიებისთვის ვთავაზობთ შესაძენ საწარმოო ვერსიას.
- ჩვენი API (Application Programming Interface) დეველოპერებს საშუალებას აძლევს ჩვენი მოდელების შესაძლებლობები და სარგებელი საკუთარ აპლიკაციებში გააერთიანონ. ათასობით ორგანიზაცია, მათ შორის Duolingo, Spotify და Morgan Stanley, ჩვენს API-ს იყენებს ახალი ფუნქციების, აპლიკაციებისა და ბიზნესების შესაქმნელად. დანიური კომპანია Be My Eyes ჩვენს API-ს იყენებს, რათა უსინათლო და დაბალი მხედველობის მქონე მომხმარებლებს დაეხმაროს სურათების ატვირთვასა და მათ შესახებ კითხვების დასმაში, რითაც მათ ფიზიკურ გარემოში უკეთ ნავიგაციასა და მეტ დამოუკიდებლობას უწყობს ხელს. ჩვენი API ხელმისაწვდომია მისამართზე platform.openai.com(იხსნება ახალ ფანჯარაში) და დეველოპერები API-ზე წვდომისთვის იმის მიხედვით იხდიან, რამდენად ბევრს იყენებენ მას.
ChatGPT‑სა და ჩვენს API-ს ხელმისაწვდომს ვხდით უსაფრთხოების ფართო ზომებთან ერთად, როგორც ქვემოთ უფრო დეტალურადაა აღწერილი. ასევე, პოტენციური რისკების შეფასების შემდეგ, ღია კოდის საფუძველზე ხელმისაწვდომს ვხდით გარკვეულ მოდელებს, მაგალითად ჩვენს მეტყველებიდან ტექსტში გარდამქმნელ მოდელ Whisper-ს და გამოსახულების გაგების მოდელს სახელად CLIP.
ვგეგმავთ, რომ ChatGPT კვლავაც უფასოდ დარჩეს ხელმისაწვდომი და შემოსავალს მივიღებთ იმ მომხმარებლებისა და ბიზნესებისგან, რომლებიც პრემიუმ სერვისებში გადახდას აირჩევენ. დიდი მასშტაბის ფუნდამენტური მოდელების განვითარების და შეთავაზების მაღალი ხარჯების გათვალისწინებით, ჩვენი ორგანიზაცია მომგებიანი არ არის და ახლო მომავალში მომგებიანობასაც არ ელის — ჩვენი მიზანი კვლავ რჩება AI-ის სარგებლის ფართოდ და უსაფრთხოდ ხელმისაწვდომი გახდება მთელი მსოფლიოსთვის.
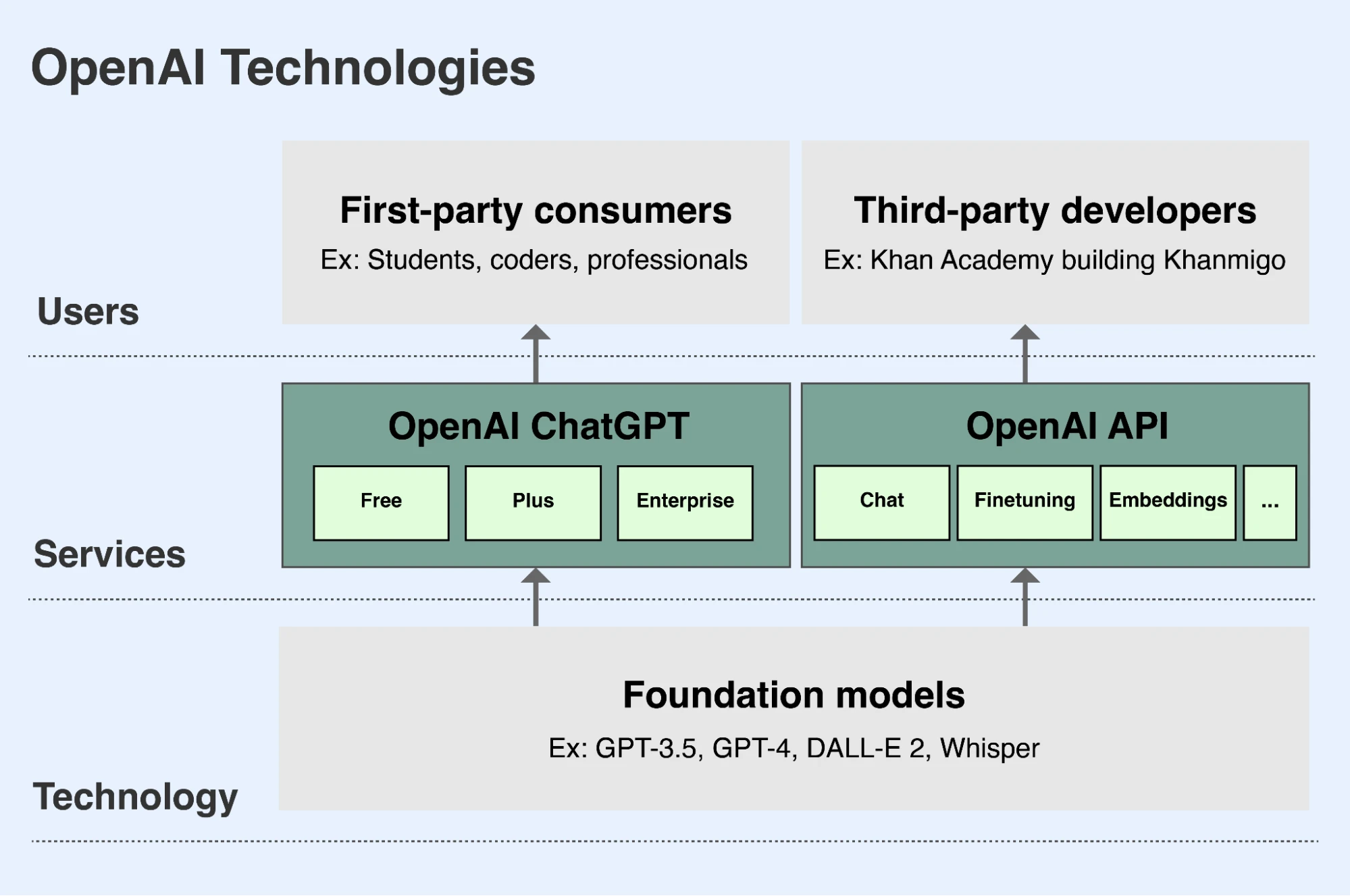
OpenAI ჩვენს წამყვან ფუნდამენტურ მოდელებზე წვდომას ძირითადად ChatGPT‑ისა და ჩვენი API-ის მეშვეობით უზრუნველყოფს.
მოწინავე ენობრივი მოდელის, როგორიცაა GPT‑4, შექმნა მოითხოვს (1) მისთვის ინტელექტის სწავლებას, როგორიცაა წინასწარმეტყველების, მსჯელობისა და პრობლემების გადაჭრის უნარი, ასევე (2) მის მორგებას ადამიანურ ღირებულებებსა და პრეფერენციებზე. პირველი ხორციელდება პროცესში, რომელსაც „წინასწარი სწავლება“ ეწოდება და რომელიც მოიცავს მოდელისთვის თვეების განმავლობაში ადამიანური ცოდნის უზარმაზარი მოცულობის ჩვენებას. შემდეგ, რათა მოდელში ადამიანური არჩევანი ჩავრთოთ, ვიყენებთ მეორე ეტაპს, რომელსაც „post-training“ ეწოდება, სადაც მოდელს უფრო უსაფრთხოსა და უფრო გამოსადეგს ვხდით.
წინასწარი სწავლება მოდელს ენას ასწავლის: მოდელს აჩვენებენ ტექსტების ფართო სპექტრს და სთხოვენ, იწინასწარმეტყველოს, რომელი სიტყვა მოდის შემდეგ ძალიან მრავალფეროვან მიმდევრობებში. ამას უზარმაზარი გამოთვლითი რესურსი სჭირდება, რადგან მოდელები ტრილიონობით სიტყვას ამუშავებენ, აანალიზებენ და მათგან სწავლობენ. ჩვენ ვაშენებთ სუპერკომპიუტერებს ჩვენი საბაზო მოდელების გასაწვრთნელად, და ერთი ახალი საბაზო მოდელის სწავლება შეიძლება თვეების განმავლობაში იკავებდეს სუპერკომპიუტერს. ამ ვრცელი პროცესის განმავლობაში მოდელი არა მხოლოდ სწავლობს, როგორ ეწყობა სიტყვები გრამატიკულად ერთმანეთთან, არამედ იმასაც, როგორ მუშაობენ ისინი ერთად უფრო მაღალი დონის იდეების შესაქმნელად და საბოლოოდ როგორ ქმნიან სიტყვების მიმდევრობები სტრუქტურირებულ აზრებს ან აყალიბებენ თანმიმდევრულ პრობლემებს. მაგალითად, როდესაც ვფიქრობთ სიტყვაზე „ღრუბელი“, შეიძლება გაგვახსენდეს დაკავშირებული სიტყვებიც, როგორიცაა „ცა“ და „წვიმა“; ხოლო წინადადების „ბედნიერების საიდუმლო არის“ ნახვისას შეიძლება სხვადასხვა ფილოსოფიურ იდეაზე ვიფიქროთ. შემდეგი სიტყვის წინასწარმეტყველებაში გამართულობის შეძენით მოდელი ამგვარად სწავლობს ცნებებსა და ინტელექტის საშენ ბლოკებს.
ამ პროცესის შედეგს — საბაზო მოდელს — აქვს გამორჩეული უნარი, გადაჭრას ახალი პრობლემები, რომლებიც მის სასწავლო მონაცემებში არ ყოფილა ნანახი, და ეს მრავალ ენაზეც. თუმცა მხოლოდ საბაზო მოდელი ჯერ მზად არ არის გამოსაყენებლად. საბაზო მოდელები ძლიერიცაა და მოქნილიც. ისინი ინტელექტუალური და გასაოცარია, მაგრამ აუცილებელი არ არის, რომ გამოსადეგი ან უსაფრთხო იყვნენ.
საბაზო მოდელთან საუბარი მარტივი არ არის: მაგალითად, თუ GPT‑4‑ის საბაზო მოდელს სთხოვთ „დაწერე ამბავი პრინცესაზე…“, ის ჩვეულებრივ ამბავს არ დაწერს. ამის ნაცვლად, ის გააგრძელებს თქვენს განცხადებას და იწინასწარმეტყველებს, როგორ გაგრძელდება იგი. მაგალითად, შეიძლება დააბრუნოს: „…პრინცესაზე, რომელსაც ცხენები უყვარს.“ საბაზო მოდელს ასევე არ აქვს დამცავი მექანიზმები, რომლებიც ხელს შეუშლიდა არასასურველი შინაარსის, მაგალითად სიძულვილის ან ძალადობის შემცველი მასალის გენერირებას. მიუხედავად იმისა, რომ ჩვენ წინასწარი სწავლების მონაცემთა ნაკრებს არასასურველ შინაარსზე ვფილტრავთ, ეს შემამსუბუქებელი ზომა ზედმეტად არაზუსტია, რათა მოდელში მიზნობრივი ცვლილებები შევიტანოთ, და შეიძლება უკუშედეგიც კი ჰქონდეს, თუ ხელს შეუშლის მოდელს გაიგოს, რა არ უნდა თქვას ან გააკეთოს. იმისათვის, რომ მოდელებში ადამიანური ღირებულებები, მათ შორის ის, რაც გამოსადეგია და რაც სათქმელად შესაფერისია, ჩავნერგოთ, ჩვენ ვიკვლევთ და ვავითარებთ მორგებისა და უსაფრთხოების ტექნიკებს პროცესისთვის, რომელსაც post-training-ს ვუწოდებთ.
Post-training არის ის გზა, რომლითაც ჩვენს მოდელებში ადამიანურ არჩევანს ვაერთიანებთ და მათ სასარგებლო, ეფექტიან და უფრო უსაფრთხო ინსტრუმენტებად ვაქცევთ. ჩვენ მოდელს ვასწავლით უპასუხოს ისე, როგორც ადამიანებს უფრო გამოსადეგად მიაჩნიათ, და უარი თქვას პასუხზე ისეთი ფორმით, რომელიც, ჩვენი აზრით, საზიანო იქნებოდა. Post-training მოითხოვს მნიშვნელოვან ინვესტიციას კვლევაში, ადამიანურ რესურსებში, დიზაინის არჩევანებსა და მონაცემების შექმნაში. ეს OpenAI-ისთვის კვლევისა და ინვესტირების აქტიური მიმართულებაა. ჩვენ ასევე გვჯერა, რომ ჩვენი კომპანიის გარეთ ბევრი ადამიანიც იქნება ჩართული მონაცემების შექმნასა და დიზაინის გადაწყვეტილებების მიღებაში, რათა ისინი ადამიანურ ღირებულებებს ასახავდეს.
Post-training იწვევს მოდელში მიზნობრივ ცვლილებებს შედარებით მცირე და საგულდაგულოდ შემუშავებული მონაცემთა ნაკრებების გამოყენებით, რომლებიც იდეალურ ქცევას წარმოადგენს. ამას ვაკეთებთ იმით, რომ ადამიანები წერენ პასუხების ნიმუშებს, აფასებენ მოდელის მიერ მოცემულ პასუხებს და შემდეგ ამ ნიმუშებსა და შეფასებებს მოდელს უბრუნებენ შემდგომი სწავლების პროცესებში. სწორედ ჩვენ შევქმენით ეს ტექნიკები, მათ შორის ადამიანის უკუკავშირის საფუძველზე განმამტკიცებელი სწავლება (RLHF), რომელიც ახლა უკვე ინდუსტრიის სტანდარტად იქცა. ჩვენ RLHF-ს ვიყენებთ, რათა მოდელს ინსტრუქციების შესრულება ვასწავლოთ, შევამციროთ არაზუსტი შინაარსის დაბრუნების ალბათობა და დავამატოთ უსაფრთხოების ფუნქციები.
GPT‑4‑ის საჯაროდ გამოშვებამდე, 6 თვე დავხარჯეთ post-training-ის განმეორებით დახვეწაზე. ამ პერიოდში შევიმუშავეთ ტექნიკები, რათა ჩვენს მოდელებს ვასწავლოთ უარი თქვან იმ მოთხოვნებზე პასუხზე, რომლებიც, ჩვენი აზრით, პოტენციურ ზიანს შეიძლება იწვევდეს. მაგალითად, თუ ჰკითხავენ, როგორ ააწყოს ბომბი, მოდელი პასუხზე უარს იტყვის. ჩვენი შიდა შეფასებების მიხედვით, GPT‑4 82%-ით ნაკლებად პასუხობს აკრძალული შინაარსის მოთხოვნებს, წინა თაობის მოდელ GPT‑3.5‑თან შედარებით. ამავე დროს, 40%-ით გავზარდეთ ფაქტობრივი პასუხების გაცემის ალბათობა, ვასწავლეთ მას სასაუბრო ფორმით პასუხი და გავაუმჯობესეთ მისი მუშაობა ნაკლებად უზრუნველყოფილ ენებზე, მაგალითად ისლანდიასთან პარტნიორობით.
ჩვენ კვლავაც ვავითარებთ post-training-ის ტექნიკებს(იხსნება ახალ ფანჯარაში), რათა ჩვენს მოდელებში ადამიანური არჩევანი უკეთ აისახოს. მაგალითად, ზოგიერთი ჩვენი მიდგომა ადამიანებს საშუალებას აძლევს აღწერონ წესები, რომლებსაც სისტემა უნდა მიჰყვეს, იმის ნაცვლად, რომ უკეთესი ან უარესი ქცევის მაგალითები შეაფასონ.
გარდა იმ post-training-ისა, რომელსაც თავად ვატარებთ, მომხმარებლებს ასევე ვთავაზობთ შესაძლებლობას, ჩვენი მოდელები „fine-tune“ გააკეთონ თავიანთი კონკრეტული მიზნების მისაღწევად, მაგალითად მათ საკუთრებაში არსებულ ენებზე პროგრამული კოდის დასაწერად, დარგობრივი ცოდნის სასწავლებლად ან მათი ბრენდის ტონთან მისასწორებლად. მომხმარებლები ამას აკეთებენ იმ მონაცემების მომზადებით, რომლებიც სასურველ ქცევას აჩვენებს, და ჩვენი API-ის საშუალებით დამატებითი post-training-ისთვის მათი გაგზავნით. თუ მონაცემები ჩვენს უსაფრთხოების შემოწმებებს გაივლის, შედეგად მიღებულ fine-tuned მოდელს მხოლოდ იმ კონკრეტული მომხმარებლისთვის ვხდით ხელმისაწვდომს. სხვა API ტრაფიკის მსგავსად, ქვემოთ აღწერილ ჩვენს მონიტორინგისა და გამოვლენის სისტემებს ვიყენებთ, რათა დავეხმაროთ გამოვლენაში, არღვევენ თუ არა fine-tuned მოდელები ჩვენს გამოყენების პოლიტიკებს.
უსაფრთხოების გარდა, რომელსაც post-training-ის მეშვეობით ვაღწევთ, ჩვენ ვატარებთ მკაცრ ტესტირებას, გარე ექსპერტებს ვრთავთ უკუკავშირის მისაღებად, ვქმნით და ვაძლიერებთ უსაფრთხოებისა და მონიტორინგის სისტემებს და ვაწვდით რესურსებს, რათა ადამიანებმა ჩვენი მოდელები პასუხისმგებლობით გამოიყენონ. უსაფრთხოებისადმი ეს ჰოლისტიკური მიდგომა გვაძლევს საშუალებას დავნერგოთ და აღვასრულოთ ჩვენი გამოყენების პოლიტიკა, რომელიც კრძალავს ჩვენი მოდელების ისეთ გამოყენებას, რომელმაც შეიძლება ზიანი გამოიწვიოს, მაგალითად სიძულვილის, შევიწროების ან ძალადობრივი შინაარსის გენერირებისთვის, პოლიტიკური კამპანიებისთვის ან მავნე პროგრამების შექმნისთვის.
Red-teaming და შეფასებები. ჩვენ თითოეულ მთავარ ახალ მოდელს ვაფასებთ უსაფრთხოების რისკებსა და შესაძლო საზოგადოებრივ ზიანზე, როგორიცაა მიკერძოება და დისკრიმინაცია. ვატარებთ შიდა და გარე red-teaming-ს, სადაც მოდელს შიგნით ვამოწმებთ რისკებზე და სხვადასხვა ინდუსტრიის ექსპერტებს ადრეულ წვდომას ვაძლევთ, რათა დაგვეხმარონ სისტემების გამოკვლევაში, რისკების რუკირებასა და შეფასებაში. ამ შეფასებებს ვიყენებთ ჩვენი მოდელებისა და უსაფრთხოების სისტემების შემდგომი განვითარების და დახვეწის წარმართვისთვის და მიღებულ შედეგებს საჯაროდ ვაქვეყნებთ.
უსაფრთხოების მონიტორინგის სისტემები. ჩვენ ვქმნით და ვნერგავთ მონიტორინგის სისტემებს, რომლებიც არასასურველი შინაარსის აღმოჩენაში გვეხმარება და კონკრეტული ინციდენტების ადამიანურ მიმოხილვას ავსებს. როდესაც ეს სისტემები შინაარსის დარღვევას აღმოაჩენს, შეიძლება მივიღოთ სხვადასხვა ზომა, მათ შორის პასუხზე უარის თქმა, ინციდენტის მონიშვნა ადამიანური მიმოხილვისთვის ან, უკიდურეს შემთხვევაში, მომხმარებლის შეჩერება. შინაარსის კლასიფიკატორები fine-tuned ენობრივი მოდელებით მუშაობს და ჩვენ ვაგრძელებთ კვლევას, როგორ გავზარდოთ მათი დაფარვა, ეფექტიანობა და სიზუსტე; უახლესად ვიკვლევთ GPT‑4‑ის გამოყენებას მოდერაციის სისტემების შესაქმნელად.
ინსტრუმენტები მომხმარებლებისთვის. ჩვენ ვქმნით დოკუმენტაციასა და ინსტრუმენტებს ჩვენი მომხმარებლებისა და იმ დეველოპერებისთვის, რომლებიც ჩვენს მოდელებზე დაფუძნებულ აპლიკაციებს ქმნიან, რათა მათ AI უსაფრთხოდ გამოიყენონ. ახალი მოწინავე სისტემების გამოშვებამდე ვაქვეყნებთ ანგარიშს, რომელიც აღწერს მოდელის ან სისტემის შესაძლებლობებს, შეზღუდვებს და სათანადო თუ არასათანადო გამოყენების სფეროებს (მაგალითად, სისტემური ბარათები GPT‑4(იხსნება ახალ ფანჯარაში)-ისთვის და GPT‑4V-ისთვის). ჩვენ ხელმისაწვდომს ვხდით უფასო Moderations API(იხსნება ახალ ფანჯარაში)-ს, რათა მომხმარებლებმა საკუთარი გამოყენების პოლიტიკები აღასრულონ. და ჩვენ ვაქვეყნებთ კვლევას(იხსნება ახალ ფანჯარაში) ჩვენს უსაფრთხოების სისტემებზე.
უკუკავშირიდან სწავლა. გვჯერა, რომ უკუკავშირიდან სწავლა და მასზე რეაგირება დროთა განმავლობაში უსაფრთხო AI სისტემების შექმნისა და ჩვენი მისიის შესრულების კრიტიკული ნაწილია. ჩვენ უწყვეტად ვაუმჯობესებთ ჩვენი მოდელების შედეგებს, მოდერაციის სისტემებსა და გამოყენების პოლიტიკებს მომხმარებლის კომენტარებისა და უკუკავშირის საფუძველზე. ასევე, უწყვეტად ვესაუბრებით დაინტერესებულ მხარეებს AI ტექნოლოგიის ყველაზე სასარგებლო დანერგვასა და ადაპტაციაზე.
ხელოვნური ინტელექტი კომპიუტერული მეცნიერების დარგია, რომლის მიზანია ისეთი გამოთვლითი სისტემების შექმნა, რომლებსაც შეუძლიათ მოიქცნენ ისე, როგორც ჩვეულებრივ ადამიანურ ინტელექტთან ასოცირდება. მაგალითებია პროგრამული უზრუნველყოფა, რომელსაც შეუძლია ითამაშოს ისეთი თამაშები, როგორიცაა ჭადრაკი, მანქანები, რომლებსაც შეუძლიათ თვითმართვა, და ჩატბოტები, რომლებსაც შეუძლიათ ადამიანის მსგავსის საუბრის სიმულაცია.
მანქანური სწავლება არის ხელოვნური ინტელექტის მიმართულება, სადაც კომპიუტერულ სისტემებს შეუძლიათ ისწავლონ ამოცანების შესრულება ინფორმაციის ან ექსპერიმენტის საფუძველზე და არა ნაბიჯ-ნაბიჯ დაპროგრამებით. მაგალითად, მანქანური სწავლების სისტემამ შეიძლება ისწავლოს კატის სურათის დახატვა კატების სხვადასხვა სურათის ნახვით და ამ სურათების მახასიათებლების შესწავლით, იმის ნაცვლად, რომ მიეღოს სტრიქონ-სტრიქონ ინსტრუქციები, თუ როგორ გამოიყურებიან კატები. ან სისტემამ შეიძლება ისწავლოს ვიდეოთამაშის თამაში ექსპერიმენტირებით და წარმატებული მცდელობებისთვის ჯილდოს მიღებით, იმის ნაცვლად, რომ მიეწოდოს თამაშის წესები და ინსტრუქციები, როგორ დაასრულოს თამაში.
მოდელები არის კომპიუტერული პროგრამები, რომლებიც ხელოვნური ინტელექტისა და მანქანური სწავლების ტექნიკების გამოყენებით იქმნება. ყველაზე გავრცელებული მოდელები არის პროგრამები, რომლებიც მონაცემებს აანალიზებენ, რათა ამ მონაცემებზე დაყრდნობით მომავალი პროგნოზები გააკეთონ. მაგალითად, მოდელი შეიძლება შეიქმნას მომხმარებლების ისტორიული შესყიდვების გასაანალიზებლად, რათა მომავალ მყიდველს შესყიდვები ურჩიოს.
ფუნდამენტური მოდელები არის AI მოდელები, რომლებიც დიდი მოცულობის მონაცემებიდან სასწავლად და ამ მონაცემებთან დაკავშირებული ამოცანების ფართო სპექტრის შესასრულებლად დიდი რაოდენობის გამოთვლითი რესურსის გამოყენებით იქმნება. მაგალითად, ენობრივი მოდელი, რომელიც დიდი მოცულობის ტექსტის გამოყენებით ვითარდება, შემდეგ შეიძლება გამოყენებულ იქნას ტექსტის გასაანალიზებლად, დასაწერად და მასზე კითხვებზე პასუხის გასაცემად.
ხელოვნური ინტელექტისა და მანქანური სწავლების სფეროები სწრაფად ვითარდება, ამიტომ ეს განმარტებები დროთა განმავლობაში კვლავაც შეიცვლება.