Understanding the source of what we see and hear online
We’re introducing new tools to help researchers study content authenticity and are joining the Coalition for Content Provenance and Authenticity Steering Committee.

Update on August 4, 2024
Sharing a few updates on our ongoing content provenance work since we published this blog post in May:
Researching text solutions
- Our teams have prioritized launching audiovisual content provenance solutions, which are widely considered to present higher levels of risk at this stage of capabilities of our models.
- We have also done extensive research on the area of text provenance and have explored a range of solutions, including classifiers, watermarking and metadata. You can read more on these efforts in this case study we did with the Partnership on AI(opens in a new window).
- A few updates on some of the approaches we’re currently researching and considering:
- Text watermarking
- Our teams have developed a text watermarking method that we continue to consider as we research alternatives.
- While it has been highly accurate and even effective against localized tampering, such as paraphrasing, it is less robust against globalized tampering; like using translation systems, rewording with another generative model, or asking the model to insert a special character in between every word and then deleting that character - making it trivial to circumvention by bad actors.
- Another important risk we are weighing is that our research suggests the text watermarking method has the potential to disproportionately impact some groups. For example, it could stigmatize use of AI as a useful writing tool for non-native English speakers.
- Text metadata
- Our teams are also researching how metadata could be used as a text provenance method.
- We are still in the early stages of exploration, so it is too early to gauge how effective the approach will be, but there are characteristics of metadata that would make this approach particularly promising.
- For example, unlike watermarking, metadata is cryptographically signed, which means that there are no false positives. We expect this will be increasingly important as the volume of generated text increases. While text watermarking has a low false positive rate, applying it to large volumes of text would lead to a large number of total false positives.
- Text watermarking
Expanding our image detection tools as we build new features
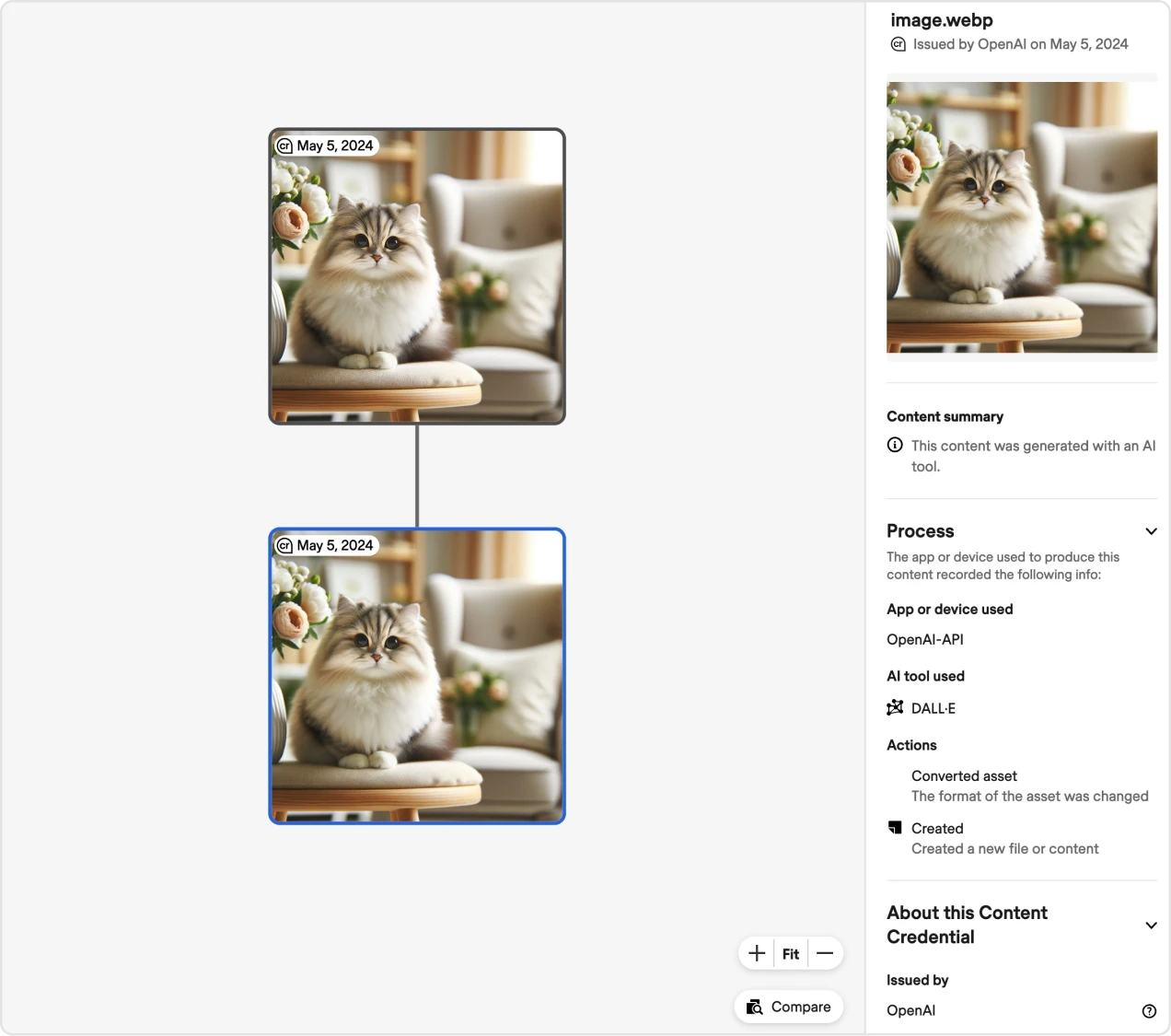
- As part of our continued efforts on content provenance, we’ve been working to include C2PA(opens in a new window) metadata – a widely used standard for digital content – as we update features in our products. As users can now edit DALL-E 3 generated images in ChatGPT, we wanted to ensure that provenance information continues to be demonstrated along with those edits. If a user edits an image, we’ve built in a means for our C2PA credential to show that the image was edited and how.
- In the example image, you can see the original AI-generated picture of a caterpillar, then edited to have the caterpillar wearing a Santa hat. When a user edits this image, the C2PA credentials update to reflect these changes, ensuring transparency. The C2PA credential includes details like the app and tool used (OpenAI’s DALL-E), the actions taken (like format conversion and edits), and other modifications. This way, the entire history of the image is tracked and displayed.

People around the world are embracing generative AI to create and edit images, videos, and audio in ways that turbocharge creativity, productivity, and learning. As generated audiovisual content becomes more common, we believe it will be increasingly important for society as a whole to embrace new technology and standards that help people understand the tools used to create the content they find online.
At OpenAI, we’re addressing this challenge in two ways: first, by joining with others to adopt, develop and promote an open standard that can help people verify the tools used for creating or editing many kinds of digital content, and second, by creating new technology that specifically helps people identify content created by our own tools.
The world needs common ways of sharing information about how digital content was created. Standards can help clarify how content was made and provide other information about its origins in a way that’s easy to recognize across many situations — whether that content is the raw output from a camera, or an artistic creation from a tool like DALL·E 3.
Today, OpenAI is joining the Steering Committee of C2PA – the Coalition for Content Provenance and Authenticity. C2PA is a widely used standard for digital content certification, developed and adopted by a wide range of actors including software companies, camera manufacturers, and online platforms. C2PA can be used to prove the content comes a particular source.1 We look forward to contributing to the development of the standard, and we regard it as an important aspect of our approach.
Earlier this year we began adding C2PA metadata to all images created and edited by DALL·E 3, our latest image model, in ChatGPT and the OpenAI API. We will be integrating C2PA metadata for Sora, our video generation model, when the model is launched broadly as well.
People can still create deceptive content without this information (or can remove it), but they cannot easily fake or alter this information, making it an important resource to build trust. As adoption of the standard increases, this information can accompany content through its lifecycle of sharing, modification, and reuse. Over time, we believe this kind of metadata will be something people come to expect, filling a crucial gap in digital content authenticity practices.
To drive adoption and understanding of provenance standards - including C2PA - we are joining Microsoft in launching a societal resilience fund(opens in a new window). This $2 million fund will support AI education and understanding, including through organizations like Older Adults Technology Services from AARP(opens in a new window), International IDEA(opens in a new window), and Partnership on AI(opens in a new window).
In addition to our investments in C2PA, OpenAI is also developing new provenance methods to enhance the integrity of digital content. This includes implementing tamper-resistant watermarking – marking digital content like audio with an invisible signal that aims to be hard to remove – as well as detection classifiers – tools that use artificial intelligence to assess the likelihood that content originated from generative models. These tools aim to be more resistant to attempts at removing signals about the origin of content.
Starting today, we are opening applications for access to OpenAI's image detection classifier to our first group of testers - including research labs and research-oriented journalism nonprofits - for feedback through our Researcher Access Program(opens in a new window). This tool predicts the likelihood that an image was generated by OpenAI’s DALL·E 3. Our goal is to enable independent research that assesses the classifier's effectiveness, analyzes its real-world application, surfaces relevant considerations for such use, and explores the characteristics of AI-generated content. Applications for access can be submitted here(opens in a new window).
Understanding when and where a classifier may underperform is critical for those making decisions based on its results. Internal testing on an early version of our classifier has shown high accuracy for distinguishing between non-AI generated images and those created by DALL·E 3 products. The classifier correctly identifies images generated by DALL·E 3 and does not trigger for non-AI generated images. It correctly identified ~98% of DALL·E 3 images and less than ~0.5% of non-AI generated images were incorrectly tagged as being from DALL·E 3. The classifier handles common modifications like compression, cropping, and saturation changes with minimal impact on its performance. Other modifications, however, can reduce performance. We also find that the performance of the classifier for distinguishing between images generated by DALL·E 3 and other AI models is lower and the classifier currently flags ~5-10% of images generated by other AI models on our internal dataset.

In addition, we’ve also incorporated audio watermarking into Voice Engine, our custom voice model, which is currently in a limited research preview. We are committed to continuing our research in these areas to ensure that our advancements in audio technologies are equally transparent and secure.
While technical solutions like the above give us active tools for our defenses, effectively enabling content authenticity in practice will require collective action. For example, platforms, content creators, and intermediate handlers need to facilitate retaining metadata in order to enable transparency for the ultimate content consumer about the source of the content.
Our efforts around provenance are just one part of a broader industry effort – many of our peer research labs and generative AI companies are also advancing research in this area. We commend these endeavors—the industry must collaborate and share insights to enhance our understanding and continue to promote transparency online.
Authors
Footnotes
- 1
This is done by attaching an encrypted attestation that the content comes from its tool of origin.