Retro Contest
We’re launching a transfer learning contest that measures a reinforcement learning algorithm’s ability to generalize from previous experience.

Illustration: Timothy J. Reynolds
Why it matters
In typical RL research, algorithms are tested in the same environment where they were trained, which favors algorithms which are good at memorization and have many hyperparameters. Instead, our contest tests an algorithm on previously unseen video game levels. This contest uses Gym Retro, a new platform integrating classic games into Gym, starting with 30 SEGA Genesis games.
Update: The results are in!
The OpenAI Retro Contest(opens in a new window) gives you a training set of levels from the Sonic The Hedgehog™ series of games, and we evaluate your algorithm on a test set of custom levels that we have created for this contest. The contest will run from April 5 to June 5. To get people started we’re releasing retro-baselines(opens in a new window), which shows how to run several RL algorithms on the contest tasks.
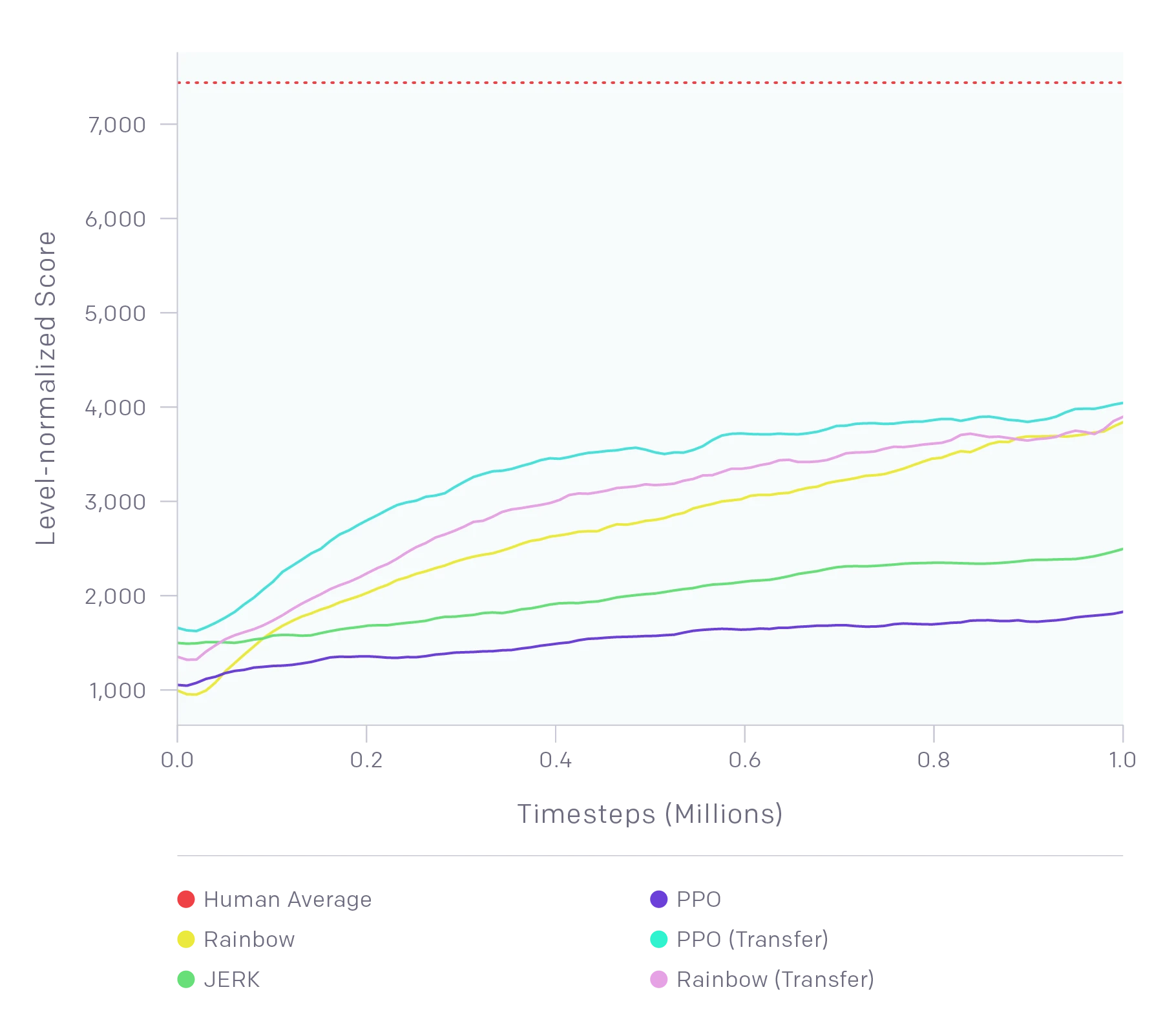
Baseline results on the Retro Contest (test set) show that RL algorithms fall far below human performance, even when using transfer learning. Human performance is shown as a dashed horizontal line. The humans only played for one hour, versus eighteen for the algorithms.
You can use any environments or datasets you want at training time, but at test time you only get about 18 hours (1 million timesteps) on each never-before-seen level. 18 hours may sound like a long time to play a single game level, but existing RL algorithms perform far worse than humans given this training budget.
To describe the benchmark in detail, as well as provide some baseline results, we are releasing a technical report: Gotta Learn Fast: A New Benchmark for Generalization in RL(opens in a new window). This report contains details about the benchmark as well as results from running Rainbow DQN(opens in a new window), PPO, and a simple random guessing algorithm called JERK. JERK samples random action sequences in a way that is optimized for Sonic, and as training progresses it replays the top-scoring sequence of actions more frequently.
We found that we could significantly boost PPO’s performance on the test levels by leveraging experience from the training levels. When the network was pre-trained on the training levels and fine-tuned on the test levels, its performance nearly doubled, making it better than the strongest alternative baselines. While this is not the first reported instance of successful transfer learning in RL, it is exciting because it shows that transfer learning can have a large and reliable effect.
But we have a long way to go before our algorithms can rival human performance. As shown above, after two hours of practice on the training levels and one hour of play on each test level, humans are able to attain scores that are significantly higher than those attained by RL algorithms, including ones that perform transfer learning.
We’ve created a dataset of recordings of humans(opens in a new window) beating the Sonic levels used in the Retro Contest. These recordings can be used to have the agent start playing from random points sampled from the course of each level, exposing the agent to a lot of areas it may not have seen if it only started from the beginning of the level. Researchers can also use these recordings to try to train agents that learn from demonstrations.
We are releasing Gym Retro, a system for wrapping classic video games as RL environments. This preliminary release includes 30 SEGA Genesis games from the SEGA Mega Drive and Genesis Classics Steam Bundle(opens in a new window) as well as 62 of the Atari 2600 games from the Arcade Learning Environment.
The Arcade Learning Environment(opens in a new window), a collection of Atari 2600 games with interfaces for reinforcement learning, has been a major driver of RL research for the last five years. These Atari games were more varied and complex than previous RL benchmarks, having been designed to challenge the motor skills and problem solving abilities of human players.
The Gym Retro Beta(opens in a new window) utilizes a more modern console than Atari—SEGA Genesis—expanding the quantity and complexity of games that are available for RL research. Games made on the Genesis tend to have lots of levels that are similar in some dimensions (physics, object appearances) and different in others (layout, items), which makes them good testbeds for transfer learning. They also tend to be more complex than Atari games since they exploit the better hardware of the Genesis (for example, it has more than 500 times as much RAM as the Atari, a greater range of possible control inputs, and support for better graphics).
Gym Retro was inspired by the Retro Learning Environment(opens in a new window) but written to be more flexible than RLE; for instance, in Gym Retro you can specify the environment definition through JSON files rather than C++ code, making it easier to integrate new games.
Gym Retro is our second generation attempt to build a large dataset of reinforcement learning environments. It builds on some of the same ideas as Universe from late 2016, but we weren’t able to get good results from that implementation because Universe environments ran asynchronously, could only run in real time, and were often unreliable due to screen-based detection of game state. Gym Retro extends the model of the Arcade Learning Environment to a much larger set of potential games.
To get started with Gym Retro check out the Getting Started section on GitHub.
Sometimes, algorithms can find exploits within the game. Here, a PPO-trained policy discovers it can slip through the walls of a level to move right and attain a higher score—another example of how particular reward functions can lead to AI agents manifesting odd behaviors.
Authors
Other contributions
Thanks to Jonathan Gray and Tom Brown for their contributions to early versions of gym-retro.
Thanks to Philipp Moritz, Robert Nishihara, Adam Stelmaszczyk, Aravind Srinivas, Qin Yongliang, Julian Togelius, and Emilio Parisotto for helpful feedback.
Cover artwork
Timothy J. Reynolds


