Cómo funciona la tecnología de OpenAI

OpenAI se creó en 2015 como entidad sin ánimo de lucro para asegurar que la inteligencia artificial general (es decir, un tipo de IA que es tan inteligente como una persona o más) beneficie a toda la humanidad. Investigamos, desarrollamos y lanzamos tecnología de IA puntera, así como herramientas y buenas prácticas para asegurar su seguridad, alineación y gobernanza. OpenAI sigue estando dirigida actualmente por nuestra organización sin ánimo de lucro: ponemos nuestra misión por delante de los beneficios, limitamos las ganancias de nuestros empleados e inversores y devolveremos los beneficios por encima de cierto umbral a nuestra organización sin ánimo de lucro. Esta estructura corporativa única nos ofrece incentivos diferentes a los de otras empresas tecnológicas. Nuestro objetivo no es vender cuanto más mejor, sino trabajar por un mundo donde todas las personas se beneficien de las oportunidades sociales, económicas y tecnológicas que ofrece la IA.
Como parte de la misión de OpenAI, desarrollamos modelos fundacionales líderes y ponemos sus capacidades a disposición de personas de todo el mundo(se abre en una ventana nueva) de forma segura y beneficiosa. Se puede acceder a nuestros modelos principalmente de dos formas:
- ChatGPT es una aplicación que permite a los usuarios interactuar con nuestros modelos de forma conversacional. Los usuarios pueden pedir a nuestros modelos lingüísticos que analicen o redacten texto o código, o bien solicitar a nuestros modelos de imagen que creen imágenes a partir de una descripción textual. ChatGPT está disponible de forma gratuita para todos los usuarios en chatgpt.com(se abre en una ventana nueva). Los usuarios también pueden suscribirse a un plan mensual premium que pone a su disposición diversas funciones y capacidades adicionales, mientras que los profesionales tienen la posibilidad de comprar una versión para empresas.
- Nuestra API (interfaz de programación de aplicaciones) permite a los desarrolladores integrar en sus propias aplicaciones las capacidades y ventajas de nuestros modelos. Miles de organizaciones, entre las que se incluyen Duolingo, Spotify y Morgan Stanley, están desarrollando nuevas funciones, aplicaciones y negocios a partir de nuestra API. Una empresa danesa llamada Be My Eyes utiliza nuestra API para ayudar a usuarios ciegos y con problemas de visión a cargar imágenes y hacer preguntas sobre ellas con el fin de que puedan desenvolverse mejor en espacios físicos y ser más independientes. Nuestra API está disponible en platform.openai.com(se abre en una ventana nueva) y los desarrolladores pagan por acceder a ella en función de su uso.
ChatGPT y nuestra API incluyen amplias medidas de seguridad, tal y como se describen a continuación. También hemos puesto a disposición de los usuarios algunos modelos de código abierto, como Whisper, que convierte voz a texto, o CLIP, que procesa y comprende imágenes, tras haber evaluado los posibles riesgos de su lanzamiento.
Nuestra intención es que ChatGPT siga estando disponible de forma gratuita. Nuestros beneficios provendrán de aquellos usuarios y empresas que decidan pagar por nuestros servicios premium. Debido a los elevados costes de desarrollar y ofrecer modelos fundacionales a gran escala, nuestra organización no es rentable y no espera serlo en un futuro próximo: nuestro objetivo sigue siendo que la IA esté disponible de forma generalizada y que sea segura para todo el mundo.
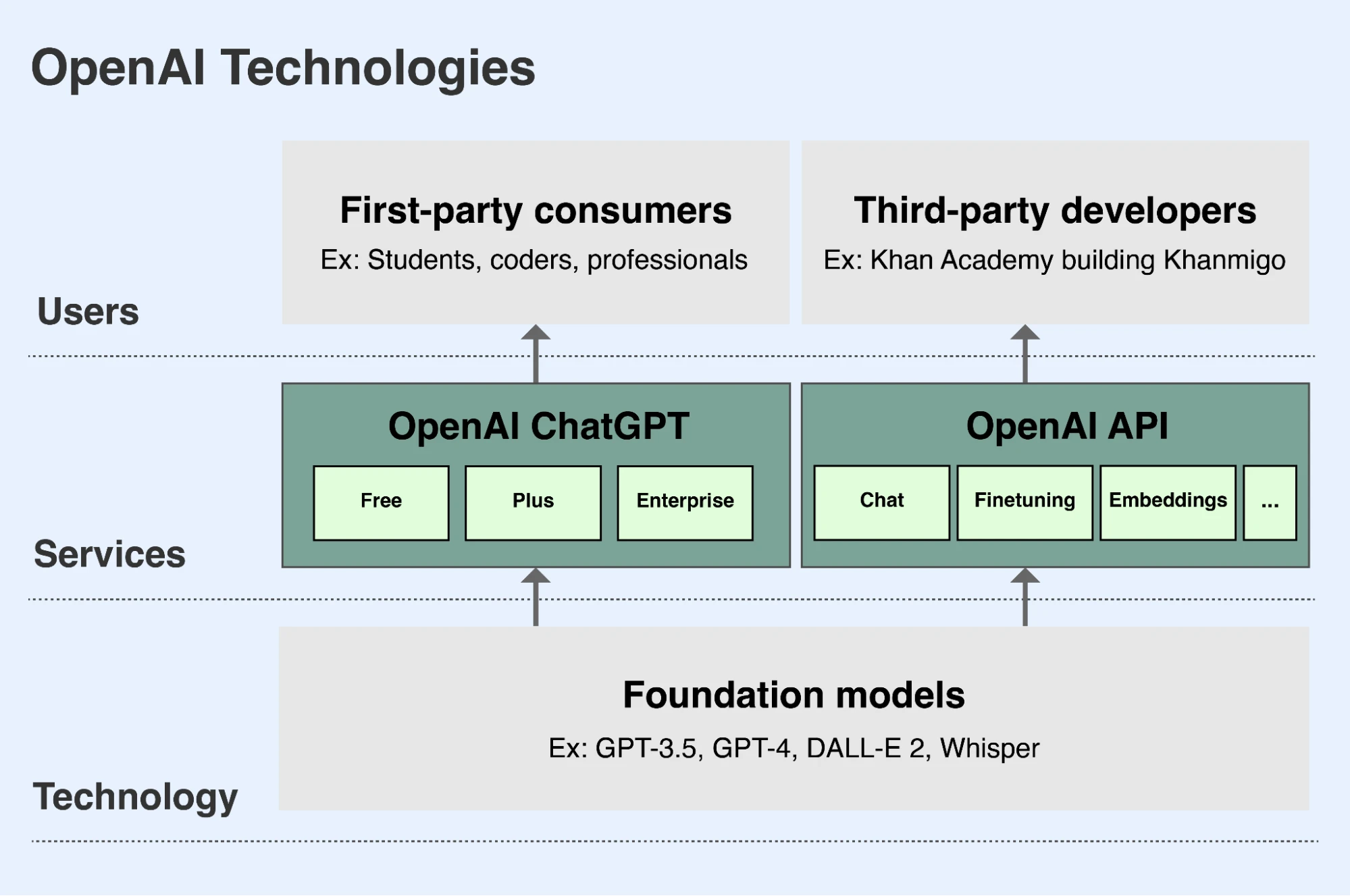
OpenAI facilita el acceso a nuestros modelos fundacionales líderes a través de ChatGPT y nuestra API, principalmente.
Para desarrollar un modelo lingüístico avanzado como GPT‑4 se necesita: 1) enseñarle inteligencia, es decir, la capacidad de predecir, razonar y resolver problemas, y 2) alinearlo con los valores y preferencias humanos. Lo primero se realiza mediante un proceso denominado «preentrenamiento», que consiste en mostrar al modelo durante meses una gran cantidad de conocimientos humanos. A continuación, para incorporar la elección humana en el modelo, utilizamos un segundo paso denominado «posentrenamiento» en el que hacemos que el modelo sea más seguro y manejable.
Durante el preentrenamiento se enseña al modelo el lenguaje mostrándole una amplia gama de textos y pidiéndole que prediga la palabra que viene a continuación en una gran variedad de secuencias. Para ello, es necesaria una cantidad ingente de computación, ya que los modelos revisan, analizan y aprenden de billones de palabras. Construimos superordenadores para entrenar a nuestros modelos base. Un superordenador puede tardar meses en entrenar tan solo un modelo base nuevo. A través de este largo proceso, el modelo no solo aprende cómo se relacionan las palabras gramaticalmente, sino también cómo funcionan juntas para formar ideas a un nivel superior y, en última instancia, cómo las secuencias de palabras forman pensamientos estructurados o plantean problemas coherentes. Por ejemplo, cuando pensamos en la palabra «nube», es posible que también pensemos en términos relacionados, como «cielo» y «lluvia». Si escuchamos «El secreto de la felicidad es», podemos pensar en diferentes ideas filosóficas. A medida que gana fluidez al predecir la palabra que viene a continuación, el modelo aprende diferentes conceptos y los componentes básicos de la inteligencia.
El resultado de este proceso, un modelo base, tiene la capacidad de resolver nuevos problemas que no aparecían en sus datos de entrenamiento, incluso en varios idiomas. Sin embargo, todavía no está listo para ser utilizado por sí solo. Los modelos base son potentes, flexibles, inteligentes y sorprendentes, pero no necesariamente útiles ni seguros.
No es fácil comunicarse con un modelo base: por ejemplo, si pides al modelo base de GPT‑4 que escriba «un cuento sobre una princesa...», normalmente no escribirá un cuento. En su lugar, completará tu enunciado prediciendo cómo continúa. El resultado podría ser el siguiente: «... sobre una princesa a la que le encantan los caballos». Un modelo base tampoco tiene medidas de seguridad para evitar que produzca contenido no deseado, como material violento o que incite al odio. Aunque filtramos nuestros datos de preentrenamiento para detectar el contenido no deseado, esta medida de mitigación es demasiado imprecisa para hacer cambios específicos en el modelo, e incluso puede ser contraproducente si impide que el modelo comprenda lo que no debe decir o hacer. Para introducir valores humanos en los modelos, por ejemplo, lo que es útil y lo que es adecuado decir, investigamos y desarrollamos técnicas de alineación y seguridad para un proceso denominado posentrenamiento.
El posentrenamiento consiste en incorporar la elección humana en nuestros modelos para transformarlos en instrumentos útiles, eficaces y más seguros. Enseñamos al modelo a responder de forma útil para las personas, así como a negarse a hacerlo si puede causar daño. El posentrenamiento requiere grandes inversiones en investigación, personal, diseño y creación de datos. Se trata de un área activa de investigación e inversión para OpenAI. Sabemos que es importante que muchos usuarios ajenos a nuestra empresa participen en la labor de crear datos y adoptar decisiones de diseño que reflejen valores humanos.
El posentrenamiento ayuda a hacer cambios selectivos en el modelo mediante conjuntos de datos relativamente pequeños y cuidadosamente diseñados que representan el comportamiento ideal. Para ello, pedimos a los usuarios que escriban ejemplos de respuestas y que califiquen las respuestas que produce el modelo, y devolvemos esos ejemplos y calificaciones al modelo mediante procesos de entrenamiento de seguimiento. Fuimos los primeros en utilizar técnicas como el aprendizaje por refuerzo con feedback humano (RLHF), que se ha convertido en la norma del sector. Utilizamos el RLHF para enseñar al modelo a seguir instrucciones, reducir las probabilidades de que devuelva contenido inadecuado, y añadir funciones de seguridad.
Antes de lanzar GPT‑4 al público, dedicamos más de seis meses a perfeccionar el posentrenamiento. Durante ese período, desarrollamos técnicas para enseñar a nuestros modelos a negarse a responder a solicitudes que creemos que podrían causar daños. Por ejemplo, si le piden instrucciones sobre cómo construir una bomba, el modelo se negará a responder. Según nuestras evaluaciones internas, hemos conseguido que GPT‑4 tenga un 82 % menos de probabilidades de responder a solicitudes de contenidos no permitidos que el modelo GPT‑3.5 de la generación anterior. También aprovechamos este tiempo para aumentar en un 40 % la probabilidad de que produzca respuestas objetivas, enseñarle a responder de forma conversacional y mejorar su rendimiento en idiomas con pocos recursos, por ejemplo, en colaboración con Islandia.
Seguimos desarrollando técnicas de posentrenamiento(se abre en una ventana nueva) con el fin de reflejar mejor la elección humana en nuestros modelos. Por ejemplo, algunos de nuestros enfoques permiten a los usuarios describir las normas que debe seguir un sistema en lugar de calificar ejemplos en función de un mejor o peor comportamiento.
Además del posentrenamiento que realizamos nosotros mismos, también ofrecemos a los clientes la posibilidad de «optimizar» nuestros modelos para que cumplan sus objetivos específicos, como escribir código de software en sus propios lenguajes, enseñarle conocimientos específicos de su sector o alinear su tono con la marca. Para ello, los clientes preparan datos que demuestren el comportamiento que desean conseguir y los envían a través de nuestra API para seguir con el posentrenamiento. Si los datos pasan nuestros controles de seguridad, ponemos el modelo optimizado definitivo a disposición exclusiva del cliente. Al igual que con el resto de tráfico de la API, utilizamos los sistemas de supervisión y detección que describimos más adelante para determinar si los modelos optimizados infringen nuestras políticas de uso.
Además de la seguridad a través del posentrenamiento, llevamos a cabo pruebas rigurosas, solicitamos la opinión de expertos externos, creamos y reforzamos sistemas de seguridad y supervisión, y proporcionamos recursos para ayudar a los usuarios a utilizar nuestros modelos de forma responsable. Este enfoque integral de la seguridad nos permite aplicar y hacer cumplir nuestra política de uso, que prohíbe utilizar nuestros modelos de modo que se puedan causar daños, por ejemplo, para generar contenido que promueva el odio, el acoso o la violencia, realizar campañas políticas o generar malware.
La labor del equipo rojo y las evaluaciones. Evaluamos los riesgos de seguridad y los posibles perjuicios sociales, como los sesgos y la discriminación, para cada uno de los grandes modelos que desarrollamos. Nuestro equipo rojo realiza pruebas internas y externas en las que comprobamos internamente los riesgos del modelo y facilitamos a expertos de diversos sectores acceso anticipado al sistema para que nos ayuden a analizarlo con el fin de detectar y evaluar los riesgos. Estas evaluaciones nos ayudan a seguir desarrollando y perfeccionando nuestros modelos y sistemas de seguridad, y publicamos nuestras conclusiones.
Sistemas de supervisión de la seguridad. Creamos y aplicamos sistemas de supervisión que ayudan a detectar contenidos no deseados y complementan la revisión humana de incidentes concretos. Cuando estos sistemas detectan una vulneración del contenido, pueden adoptar diversas medidas, como negarse a responder, marcar el incidente para que lo revise una persona o, en casos extremos, suspender al usuario. Los clasificadores de contenidos se basan en modelos lingüísticos optimizados y seguimos investigando cómo aumentar su cobertura, eficacia y precisión. Recientemente, hemos estudiado cómo utilizar GPT‑4 para desarrollar sistemas de moderación.
Herramientas para usuarios. Creamos documentación y herramientas para nuestros usuarios y para los desarrolladores que crean aplicaciones a partir de nuestros modelos con el fin de que puedan utilizar la IA de forma segura. Antes de lanzar nuevos sistemas de frontera, publicamos un informe en el que describimos las capacidades del modelo o sistema, sus limitaciones y los ámbitos de uso adecuado e inadecuado (por ejemplo, las tarjetas de sistema para GPT‑4(se abre en una ventana nueva) y GPT‑4V). Ponemos a disposición de los usuarios una Moderations API(se abre en una ventana nueva) gratuita para que puedan aplicar sus propias políticas de uso. Además, publicamos estudios(se abre en una ventana nueva) sobre nuestros sistemas de seguridad.
Aprender del feedback. Creemos que aprender del feedback y responder a este es un componente esencial para construir sistemas de IA seguros y cumplir nuestra misión. Mejoramos continuamente los resultados de nuestros modelos, los sistemas de moderación y las políticas de uso basándonos en las opiniones y comentarios de los usuarios. También deliberamos continuamente con las partes interesadas sobre cómo adoptar y adaptar mejor la tecnología de la IA.
La inteligencia artificial es una rama de la informática cuyo objetivo es crear sistemas de computación capaces de comportarse de forma similar a la inteligencia humana. Entre los ejemplos están los programas que pueden jugar al ajedrez, coches que se conducen solos y chatbots capaces de simular conversaciones humanas.
El aprendizaje automático (ML, por sus siglas en inglés) es un enfoque de la inteligencia artificial en el que los sistemas informáticos pueden aprender a realizar tareas basándose en información o experimentando, en lugar de programarse paso a paso. Por ejemplo, un sistema de aprendizaje automático podría aprender a dibujar un gato viendo distintas imágenes de gatos y extrayendo sus características, en lugar de recibir instrucciones línea por línea sobre cómo son. Otro ejemplo: un sistema podría aprender a jugar a un videojuego experimentando y recibiendo recompensas cuando lo haga bien, en lugar de recibir las normas del juego e instrucciones sobre cómo completarlo.
Los modelos son programas informáticos que se desarrollan utilizando inteligencia artificial y técnicas de aprendizaje automático. Los modelos más comunes son los programas que analizan datos para realizar predicciones futuras basándose en ellos. Por ejemplo, se podría desarrollar un modelo para analizar las compras previas realizadas por los usuarios para recomendar qué comprar en el futuro.
Son modelos de IA que se desarrollan utilizando una enorme potencia computacional para aprender de una gran cantidad de datos con el fin de realizar diversas tareas relacionadas con esos datos. Por ejemplo, un modelo lingüístico desarrollado a partir de una gran cantidad de texto puede utilizarse para analizar, escribir y responder preguntas sobre el texto.
Los campos de la inteligencia artificial y el aprendizaje automático están avanzando con rapidez, por lo que estas definiciones evolucionarán a lo largo del tiempo.