Cómo funciona la tecnología de OpenAI

En 2015, fundamos OpenAI como organización sin ánimo de lucro a los efectos de garantizar que la humanidad pudiera sacarle provecho a la inteligencia artificial general; es decir una IA con una capacidad no menor a la de las personas. Nuestra misión es investigar, desarrollar y lanzar tecnología de IA de vanguardia, así como herramientas y prácticas recomendadas para su seguridad, cumplimiento y gobernanza. OpenAI sigue rigiéndose en la actualidad por nuestra organización sin ánimo de lucro: Anteponemos nuestra misión a los beneficios, limitamos la rentabilidad financiera a empleados e inversores, y devolveremos los beneficios futuros por encima del límite a nuestra organización sin ánimo de lucro. Esta estructura corporativa única nos proporciona incentivos diferentes a los de otras empresas tecnológicas. Nuestro objetivo no es vender lo máximo de nada, sino trabajar por un mundo en el que todos se beneficien de las oportunidades sociales, económicas y tecnológicas de la IA.
Como parte de la misión de OpenAI, desarrollamos modelos base líderes y ponemos sus capacidades a disposición de personas de todo el mundo(se abre en una nueva ventana) de forma segura y beneficiosa. Hay dos maneras principales de acceder a nuestros modelos:
- ChatGPT es una aplicación que le permite a la gente interactuar con nuestros modelos de una manera conversacional. Los usuarios pueden pedirle a los modelos de lenguaje que analicen o escriban texto o código, o pedir a nuestros modelos de imagen que dibujen imágenes a partir de una descripción textual. ChatGPT está disponible de forma gratuita para los usuarios en chatgpt.com(se abre en una nueva ventana). Los usuarios pueden suscribirse con una cuenta mensual prémium que pone a su disposición funciones y capacidades adicionales. También ofrecemos una versión para empresas.
- Nuestra API (interfaz de programación de aplicaciones) permite a los desarrolladores integrar las capacidades y los beneficios de nuestros modelos en sus propias aplicaciones. Miles de organizaciones, incluidas Duolingo, Spotify y Morgan Stanley, están creando nuevas funciones, aplicaciones y negocios con nuestra API. Una empresa danesa llamada Be My Eyes utiliza nuestra API para ayudar a los usuarios ciegos y con problemas de visión a cargar imágenes y hacer preguntas sobre ellas con el fin de que puedan desenvolverse mejor en espacios físicos y ser más independientes. Nuestra API está disponible en platform.openai.com(se abre en una nueva ventana) y los desarrolladores pagan por acceder a ella en función de su uso.
Ponemos a su disposición ChatGPT y nuestra API en relación con amplias medidas de seguridad, como se detalla más adelante. También hemos puesto a disposición ciertos modelos de código abierto como Whisper, nuestro modelo de conversión de voz a texto, o CLIP, nuestro modelo de comprensión de imágenes, tras haber evaluado los posibles riesgos de su lanzamiento.
Pretendemos seguir ofreciendo ChatGPT de forma gratuita y obtener ingresos de los usuarios y empresas que decidan pagar por servicios prémium. Dado los altos costos para desarrollar y ofrecer modelos base a gran escala, nuestra organización no es rentable y no espera serlo en un futuro próximo: nuestro objetivo sigue siendo que la IA esté disponible de forma generalizada y segura para todo el mundo.
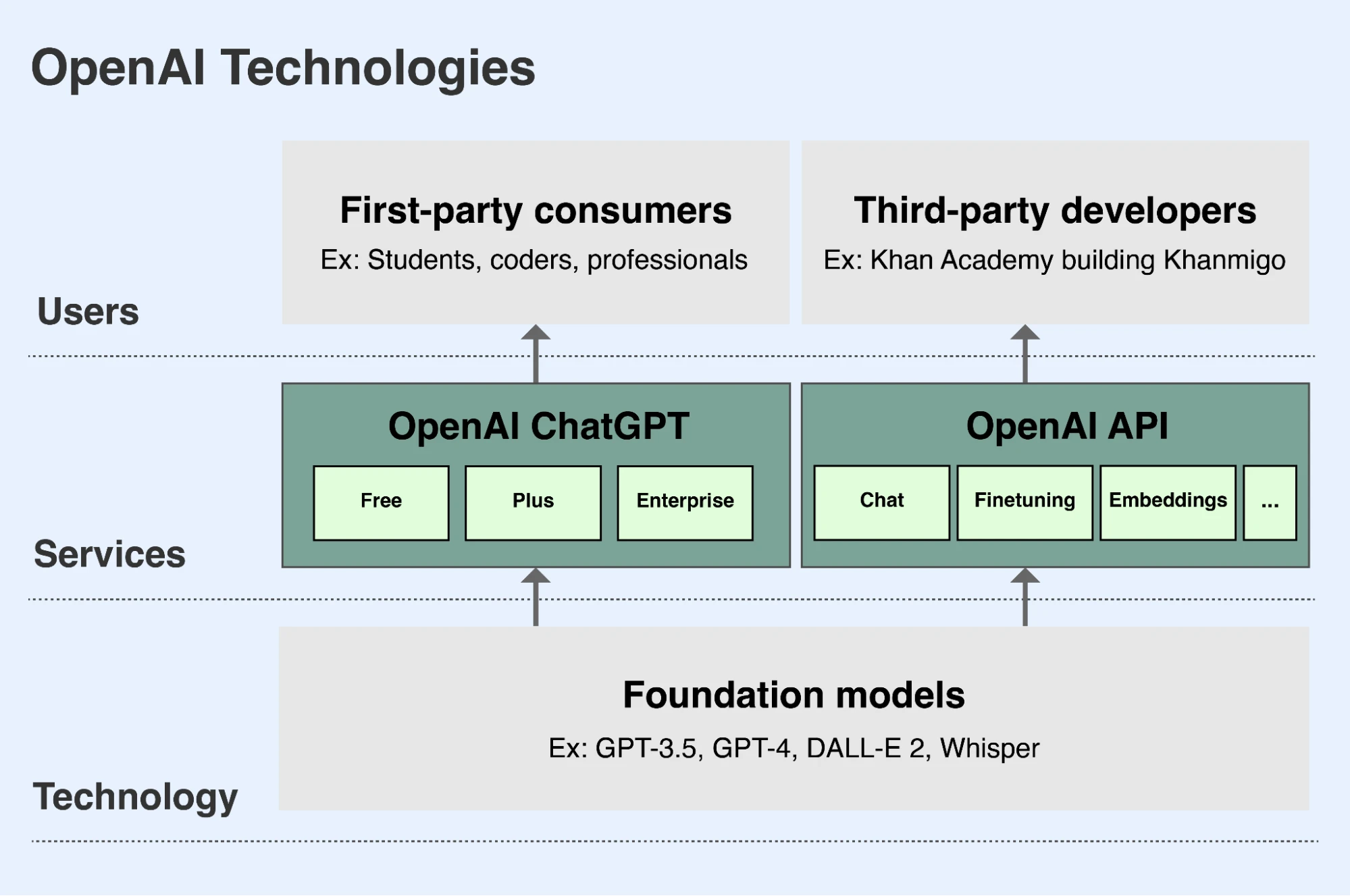
OpenAI facilita el acceso a nuestros principales modelos fundacionales principalmente a través de ChatGPT y nuestra API.
Para desarrollar un modelo de lenguaje avanzado como GPT‑4 se requiere: (1) aportarle inteligencia, como la habilidad para predecir, razonar y resolver problemas, así como (2) alinearlo con los valores y las preferencias humanas. El primer punto se realiza en un proceso denominado “entrenamiento previo”, que consiste en mostrar al modelo durante meses una gran cantidad de conocimientos humanos. A continuación, para incorporar la elección humana al modelo, utilizamos un segundo paso denominado “entrenamiento posterior” en el que hacemos que el modelo sea más seguro y manejable.
El entrenamiento previo enseña lenguaje a un modelo, mostrándole una amplia variedad de textos y haciéndole que intente predecir la palabra que viene a continuación en cada una de una enorme variedad de secuencias. Para ello se necesita una enorme cantidad de cómputo, puesto que los modelos revisan, analizan y aprenden a partir de billones de palabras. Construimos supercomputadoras para entrenar nuestros modelos base y el entrenamiento de un solo modelo base nuevo puede ocupar una supercomputadora durante meses. A través de este amplio proceso, el modelo no solo aprende cómo encajan gramaticalmente las palabras, sino también cómo funcionan juntas para formar ideas de nivel superior y, en última instancia, cómo las secuencias de palabras forman pensamientos estructurados o plantean problemas coherentes. Por ejemplo, cuando pensamos en la palabra “nube”, también podríamos pensar en palabras relacionadas como “cielo” y “lluvia”. En la frase “el secreto de la felicidad es...”, podemos pensar en varias ideas filosóficas. Al adquirir fluidez en la predicción de la palabra siguiente, el modelo aprende conceptos y los componentes básicos de la inteligencia.
El resultado de este proceso es un modelo base, que tiene la capacidad de resolver nuevos problemas que no aparecían en sus datos de entrenamiento, incluso en varios idiomas. Sin embargo, el modelo base por sí solo no está listo para utilizarse. Los modelos base son potentes y flexibles. Son inteligentes y sorprendentes, pero no son necesariamente útiles o seguros.
No es fácil hablar a un modelo base: Por ejemplo, si le pides al modelo base de GPT‑4 que “escriba un cuento sobre una princesa...”, por lo general, no escribirá un cuento. En lugar de eso, ampliará su enunciado, prediciendo cómo continúa. Por ejemplo, podría arrojar resultados como: “...sobre una princesa a la que le encantan los caballos”. Un modelo base tampoco cuenta con medidas de seguridad para evitar que produzca contenido no deseado, como material violento o que incite al odio. Aunque filtramos nuestro conjunto de datos entrenados previamente para detectar contenido no deseado, esta medida de mitigación es demasiado imprecisa para realizar cambios específicos en el modelo, e incluso puede ser contraproducente si impide que el modelo comprenda lo que no debe decir o hacer. Con el fin de introducir valores humanos en los modelos, incluido lo que es útil y lo que es adecuado decir, investigamos y desarrollamos técnicas de alineación y seguridad para un proceso denominado entrenamiento posterior.
El entrenamiento posterior se trata de cómo incorporamos la elección humana en nuestros modelos para transformarlos en herramientas útiles, eficaces y más seguras. Le enseñamos al modelo a responder de forma útil a las personas, así como negarse a responder de forma que cause perjuicios. El entrenamiento posterior requiere una inversión considerable en investigación, personal, opciones de diseño y creación de datos. Es una área activa de investigación e inversión para OpenAI. También creemos que mucha gente ajena a nuestra empresa participará en la labor de crear datos y adoptar decisiones de diseño que reflejen valores humanos.
Los resultados del entrenamiento posterior impulsan a realizar cambios selectivos en el modelo mediante conjuntos de datos relativamente pequeños y cuidadosamente diseñados que representan el comportamiento ideal. Para ello, pedimos a los usuarios que escriban ejemplos de respuestas y califiquen las respuestas proporcionadas por el modelo, y que devuelvan esos ejemplos y calificaciones al modelo en los procesos de formación de seguimiento. Fuimos pioneros en estas técnicas, incluido el aprendizaje por refuerzo a partir de feedback humano (RLHF), que ahora se ha convertido en la norma del sector. Utilizamos RLHF para enseñarle al modelo a seguir instrucciones, a disminuir la probabilidad de que arroja contenidos inexactos y a añadir funciones de seguridad.
Antes de lanzar públicamente GPT‑4, pasamos seis meses iterando sobre el entrenamiento posterior. Durante esta temporada, desarrollamos técnicas para enseñarles a nuestros modelos a negarse a responder a solicitudes que creemos pueden ocasionar daños potenciales. Por ejemplo, si le piden instrucciones sobre cómo construir una bomba, el modelo se negará a responder. Según nuestras evaluaciones internas, hemos conseguido que GPT‑4 tenga un 82 % menos de probabilidades de responder a solicitudes de contenidos no permitidos que el modelo GPT‑3.5 de la generación anterior. También aprovechamos esta temporada para aumentar la probabilidad de que produzca respuestas objetivas en un 40 %, enseñarle a responder de manera conversacional y mejorar su rendimiento en idiomas con pocos recursos, por ejemplo, en colaboración con Islandia.
Continuamos desarrollando técnicas de entrenamiento posterior(se abre en una nueva ventana) para reflejar mejor la elección humana en nuestros modelos. Por ejemplo, algunos de nuestros enfoques permiten a las personas describir las reglas que debe seguir un sistema, en lugar de tener que calificar ejemplos de mejor o peor comportamiento.
Además del entrenamiento posterior que desarrollamos, también ofrecemos a los clientes la capacidad de “optimizar” nuestros modelos a fin de que cumplan sus objetivos específicos, como escribir código de software en sus lenguajes patentados, enseñarle conocimientos específicos del sector o alinear su tono con su marca. Los clientes preparan datos que demuestren el comportamiento que desean conseguir y los envían a través de nuestra API para seguir con el entrenamiento posterior. Al suponer que los datos pasen nuestros controles de seguridad, pondremos el modelo optimizado definitivo a disposición exclusiva del cliente. Al igual que con el resto del tráfico de la API, utilizamos los sistemas de supervisión y detección que describimos más adelante para determinar si los modelos optimizados infringen nuestras políticas de uso.
Además de la seguridad a través del entrenamiento posterior, realizamos pruebas rigurosas, recabamos la opinión de expertos externos, creamos y reforzamos sistemas de seguridad y control, y proporcionamos recursos para ayudar a las personas a utilizar nuestros modelos de forma responsable. Este enfoque integral de la seguridad nos permite aplicar y hacer cumplir nuestra política de uso que prohíbe el uso de nuestros modelos de formas que puedan causar daños, como la generación de contenidos que inciten al odio, el acoso o la violencia, la realización de campañas políticas o la generación de programas maliciosos.
La labor del equipo rojo y las evaluaciones. Evaluamos los riesgos de seguridad y los posibles daños sociales, como los prejuicios y la discriminación, de cada uno de los principales modelos nuevos. Llevamos a cabo pruebas internas y externas con equipos rojos, donde probamos internamente el modelo de riesgos y facilitamos el acceso temprano a expertos externos de diversos sectores para que nos ayudaran a analizar los sistemas con el fin de detectar y evaluar los riesgos. Utilizamos estas evaluaciones para orientar el desarrollo y perfeccionamiento de nuestros modelos y sistemas de seguridad, y publicamos nuestros resultados.
Sistemas de supervisión de la seguridad. Desarrollamos y aplicamos sistemas de supervisión que ayudan a detectar contenidos no deseados y complementan la revisión humana de incidentes concretos. Cuando estos sistemas detectan una infracción de contenidos, podemos tomar diversas medidas, como negarnos a responder, marcar el incidente para que lo revise una persona o, en casos extremos, suspender al usuario. Los clasificadores de contenidos se basan en modelos de lenguaje optimizados y seguimos investigando cómo aumentar su cobertura, eficacia y precisión. Recientemente hemos explorado el uso de GPT‑4 para desarrollar sistemas de moderación.
Herramientas para usuarios. Creamos documentación y herramientas para nuestros usuarios y para los desarrolladores que crean aplicaciones a partir de nuestros modelos con el fin de que puedan utilizar la IA de forma segura. Antes de lanzar nuevos sistemas fronterizos, publicamos un informe en el que se describen las capacidades del modelo o sistema, sus limitaciones y los ámbitos de uso adecuado e inadecuado (por ejemplo, las tarjetas del sistema para GPT‑4(se abre en una nueva ventana) y GPT‑4V). Ponemos a disposición la API de Moderation(se abre en una nueva ventana), gratuita para que puedan aplicar sus propias políticas de uso. Además,publicamos investigaciones(se abre en una nueva ventana) sobre nuestros sistemas de seguridad.
Aprendemos de los comentarios. Creemos que aprender a partir de los comentarios y responder a estos es un componente clave para desarrollar sistemas de IA seguros y para cumplir nuestra misión. Mejoramos de forma continua los resultados de nuestros modelos, los sistemas de moderación y las políticas de uso al basarnos en las opiniones y comentarios de los usuarios. También participamos en conversaciones continuas con las partes interesadas sobre la adopción y adaptación más beneficiosas para la tecnología de IA.
La inteligencia artificial es una rama de la ciencia de la computación cuyo objetivo es crear sistemas informáticos capaces de comportarse de un modo típicamente asociado a la inteligencia humana. Los ejemplos incluyen los programas que pueden jugar ajedrez, carros que pueden conducirse por sí solos y chatbots capaces de simular conversaciones humanas.
El aprendizaje automático es un enfoque de la inteligencia artificial en el que los sistemas informáticos pueden aprender a realizar tareas basándose en la información o la experimentación, en lugar de ser programados paso a paso. Por ejemplo, un sistema de aprendizaje automático podría aprender a dibujar un gato viendo distintas imágenes de gatos y extrayendo sus características, en lugar de recibir instrucciones línea por línea sobre cómo son los gatos. O bien, un sistema podría aprender a jugar a un videojuego experimentando y siendo recompensado por los intentos exitosos, en lugar de recibir las reglas del juego y las instrucciones para completarlo.
Los modelos son programas informáticos que se desarrollan con inteligencia artificial y técnicas de aprendizaje automático. Los modelos más frecuentes son programas que analizan los datos para hacer futuras predicciones basadas en los datos. Por ejemplo, podría desarrollarse un modelo para analizar las compras históricas realizadas por consumidores con el fin de recomendar compras a un futuro comprador.
Los modelos base son modelos de IA que se desarrollaron con grandes cantidades de capacidad de cómputo para aprender a partir de una gran cantidad de datos, con el fin de realizar una amplia variedad de tareas relacionadas con esos datos. Por ejemplo, un modelo de lenguaje desarrollado a partir de una gran cantidad de texto puede utilizarse para analizar, escribir y responder preguntas sobre el texto.
Los campos de la inteligencia artificial y el aprendizaje automático están avanzando con rapidez, por lo que estas definiciones evolucionarán a lo largo del tiempo.