La tecnologia d’OpenAI, explicada

OpenAI es va crear com a entitat sense ànim de lucre el 2015 per garantir que la intel·ligència artificial general —en resum, IA tan intel·ligent com una persona com a mínim— beneficiï tota la humanitat. Investiguem, desenvolupem i publiquem tecnologia d'IA capdavantera, així com eines i bones pràctiques per a la seguretat, l'alineació i la governança de la IA. OpenAI continua governada avui per la nostra entitat sense ànim de lucre: prioritzem la nostra missió per davant dels beneficis, limitem els rendiments financers dels empleats i inversors, i retornarem a la nostra entitat sense ànim de lucre els beneficis futurs que superin aquest límit. Aquesta estructura corporativa única ens dona incentius diferents dels d'altres empreses tecnològiques. El nostre objectiu no és vendre el màxim de res, sinó treballar cap a un món on tothom es beneficiï de les oportunitats socials, econòmiques i tecnològiques de la IA.
Com a part de la missió d'OpenAI, desenvolupem models fundacionals líders i en fem disponibles les capacitats de manera segura i beneficiosa a persones d'arreu del món(s'obre en una finestra nova). Hi ha dues maneres principals d'accedir als nostres models:
- ChatGPT és una aplicació que permet a les persones interactuar amb els nostres models de manera conversacional. Els usuaris poden demanar als nostres models de llenguatge que analitzin o escriguin text o codi, o demanar als nostres models d'imatge que dibuixin imatges a partir d'una descripció en text. ChatGPT està disponible gratuïtament per a tots els usuaris a chatgpt.com(s'obre en una finestra nova). Els usuaris poden subscriure's a una subscripció mensual premium que dona accés a funcions i capacitats addicionals, i oferim una versió empresarial perquè les empreses la puguin adquirir.
- La nostra API (interfície de programació d'aplicacions) permet als desenvolupadors integrar les capacitats i els avantatges dels nostres models a les seves pròpies aplicacions. Milers d'organitzacions, incloses Duolingo, Spotify i Morgan Stanley, estan creant noves funcions, aplicacions i negocis amb la nostra API. Una empresa danesa anomenada Be My Eyes utilitza la nostra API per ajudar usuaris cecs i amb baixa visió a pujar imatges i fer-hi preguntes, ajudant-los a orientar-se millor en entorns físics i a guanyar més independència. La nostra API està disponible a platform.openai.com(s'obre en una finestra nova) i els desenvolupadors paguen per l'accés a l'API segons l'ús que en facin.
Posem ChatGPT i la nostra API a disposició juntament amb àmplies mesures de seguretat, tal com es detalla més avall. També oferim en règim de codi obert determinats models, com ara el nostre model de veu a text Whisper i el nostre model de comprensió d'imatges anomenat CLIP, després d'avaluar els riscos potencials d'aquestes publicacions.
Tenim la intenció de continuar oferint ChatGPT de manera gratuïta i obtindrem ingressos dels usuaris i empreses que triïn pagar per serveis premium. Atès l'alt cost de desenvolupar i oferir models fundacionals a gran escala, la nostra organització no és rendible i no espera ser-ho en un futur pròxim; el nostre objectiu continua sent posar els beneficis de la IA a disposició del món de manera àmplia i segura.
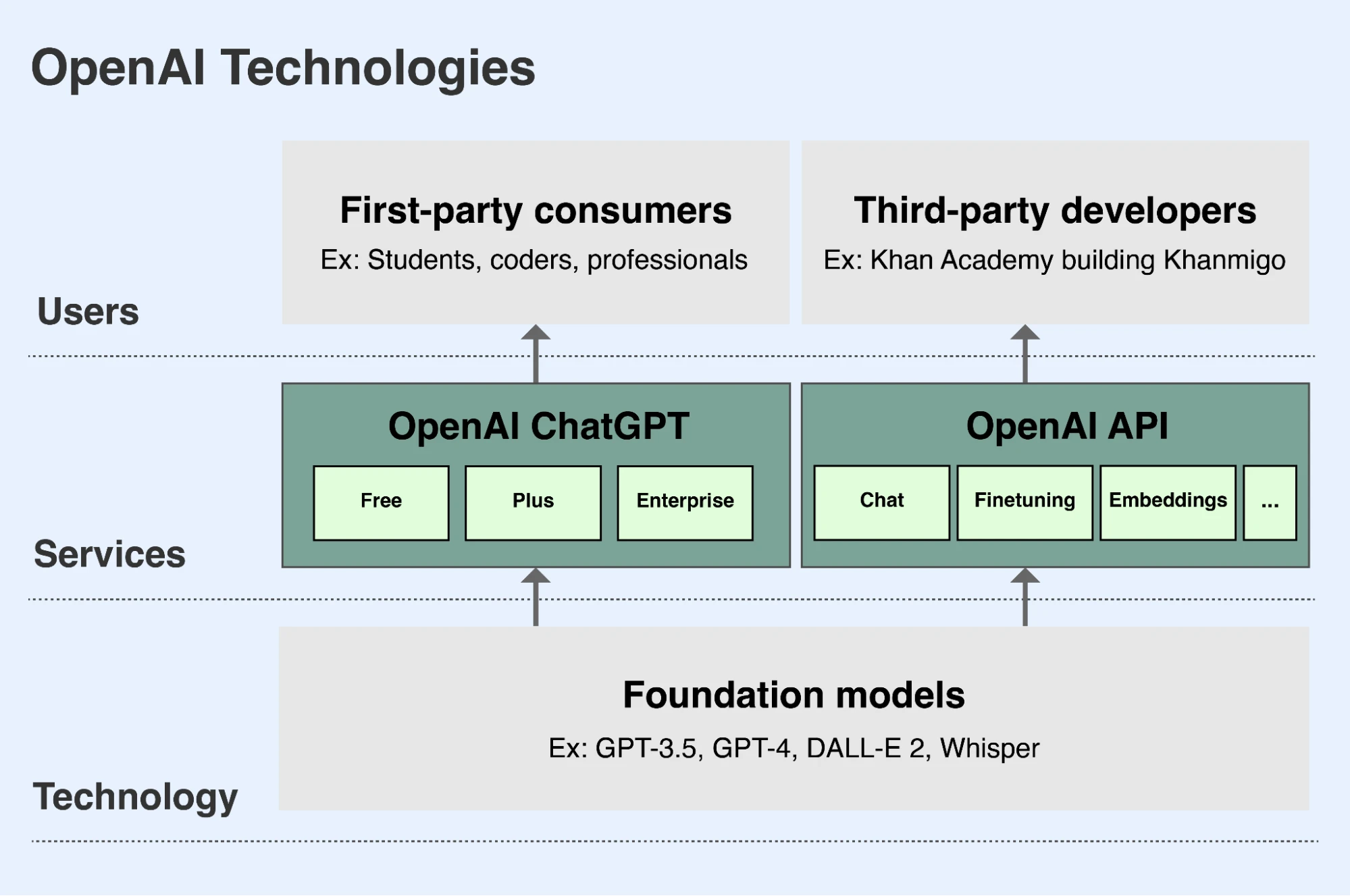
OpenAI facilita l'accés als nostres principals models fundacionals sobretot a través de ChatGPT i la nostra API.
Desenvolupar un model de llenguatge avançat com GPT‑4 requereix (1) ensenyar-li intel·ligència, com ara la capacitat de predir, raonar i resoldre problemes, així com (2) alinear-lo amb els valors i les preferències humanes. El primer es fa en un procés anomenat «preentrenament», que consisteix a mostrar al model una quantitat enorme de coneixement humà durant mesos. Per incorporar després l'elecció humana al model, fem servir un segon pas, anomenat «postentrenament», en què fem el model més segur i més útil.
El preentrenament ensenya llenguatge a un model mostrant-li una àmplia gamma de textos i fent que intenti predir la paraula següent en cadascuna d'una enorme varietat de seqüències. Això requereix una quantitat enorme de càlcul, ja que els models revisen, analitzen i aprenen de bilions de paraules. Construïm superordinadors per entrenar els nostres models de base, i l'entrenament d'un sol model de base nou pot ocupar un superordinador durant mesos. Mitjançant aquest procés extens, el model no només aprèn com encaixen les paraules gramaticalment, sinó també com treballen juntes per formar idees de nivell superior i, en últim terme, com les seqüències de paraules formen pensaments estructurats o plantegen problemes coherents. Per exemple, quan pensem en la paraula «núvol», també podem pensar en paraules relacionades com «cel» i «pluja»; quan se'ns dona una frase com «El secret de la felicitat és», podem pensar en diverses idees filosòfiques. En adquirir fluïdesa per predir la paraula següent, el model aprèn així conceptes i els components bàsics de la intel·ligència.
El resultat d'aquest procés —un model de base— té la capacitat notable de resoldre problemes nous que no ha vist en les seves dades d'entrenament, fins i tot en una àmplia varietat de llengües. Tanmateix, el model de base per si sol no està llest per utilitzar-se. Els models de base són potents i flexibles. Són intel·ligents i sorprenents, però no necessàriament útils o segurs.
No és fàcil parlar amb un model de base: per exemple, si demaneu al model de base GPT‑4 que «escrigui una història sobre una princesa…», normalment no escriurà una història. En lloc d'això, ampliarà la vostra afirmació, predint com continua. Podria produir, per exemple: «…sobre una princesa a qui li encanten els cavalls». Un model de base tampoc no té proteccions per evitar que produeixi contingut no desitjat, com ara material d'odi o violent. Tot i que filtrem el nostre conjunt de dades de preentrenament per eliminar contingut no desitjat, aquesta mitigació és massa imprecisa per fer canvis dirigits al model, i fins i tot pot ser contraproduent si impedeix que el model entengui què no ha de dir o fer. Per tal d'inculcar valors humans als models, incloent-hi què és útil i què és adequat dir, investiguem i desenvolupem tècniques d'alineació i seguretat per a un procés que anomenem postentrenament.
El postentrenament és com incorporem l'elecció humana als nostres models i els transformem en eines útils, eficaces i més segures. Ensenyem al model a respondre de maneres que la gent considera més útils, i a rebutjar respondre de maneres que creiem que serien perjudicials. El postentrenament requereix una inversió important en recerca, personal, decisions de disseny i creació de dades. Aquesta és una àrea activa de recerca i inversió per a OpenAI. També creiem que moltes persones més enllà de la nostra empresa formaran part de la feina de crear dades i prendre decisions de disseny que reflecteixin els valors humans.
El postentrenament dona lloc a canvis dirigits en el model, utilitzant conjunts de dades relativament petits i curosament dissenyats que representen un comportament ideal. Ho fem fent que persones escriguin respostes de mostra i valorin respostes proporcionades pel model, i retornant aquestes mostres i valoracions al model en processos d'entrenament posteriors. Vam ser pioners en aquestes tècniques, inclòs l'aprenentatge per reforç a partir de la retroacció humana (RLHF), que ara s'ha convertit en un estàndard del sector. Utilitzem RLHF per ensenyar al model a seguir instruccions, reduir la probabilitat que retorni contingut inexacte i afegir-hi funcions de seguretat.
Abans de publicar GPT‑4 públicament, vam dedicar 6 mesos a iterar el postentrenament. Durant aquest temps, vam desenvolupar tècniques per ensenyar als nostres models a negar-se a respondre sol·licituds que creiem que poden comportar un dany potencial. Per exemple, si se li demanen instruccions sobre com construir una bomba, el model es negarà a respondre. Segons les nostres avaluacions internes, vam fer que GPT‑4 fos un 82% menys propens a respondre a sol·licituds de contingut no permès en comparació amb el model de la generació anterior GPT‑3.5. També vam aprofitar aquest temps per augmentar en un 40% la probabilitat que produeixi respostes factuals, ensenyar-lo a respondre de manera conversacional i millorar-ne el rendiment en llengües amb pocs recursos, per exemple en col·laboració amb Islàndia.
Continuem desenvolupant tècniques de postentrenament(s'obre en una finestra nova) per reflectir millor l'elecció humana en els nostres models. Per exemple, alguns dels nostres enfocaments permeten que les persones descriguin les regles que un sistema ha de seguir, en lloc d'haver de qualificar exemples de comportament millor o pitjor.
A més del postentrenament que fem nosaltres mateixos, també oferim als clients la possibilitat d'«ajustar finament» els nostres models perquè assoleixin els seus objectius específics, com ara escriure codi de programari en els seus llenguatges propietaris, ensenyar-los coneixement específic del sector o alinear-ne el to amb la seva marca. Els clients ho fan preparant dades que demostren el comportament que busquen aconseguir i enviant-les per a un postentrenament addicional a través de la nostra API. Sempre que les dades superin les nostres comprovacions de seguretat, posem el model ajustat resultant a disposició exclusivament d'aquest client. Igual que amb altre trànsit de l'API, utilitzem els nostres sistemes de supervisió i detecció descrits a continuació per ajudar a detectar si els models ajustats infringeixen les nostres polítiques d'ús.
A més de la seguretat mitjançant el postentrenament, duem a terme proves rigoroses, impliquem experts externs perquè facin aportacions, construïm i reforcem sistemes de seguretat i monitoratge, i proporcionem recursos per ajudar les persones a utilitzar els nostres models de manera responsable. Aquest enfocament holístic de la seguretat és el que ens permet implementar i aplicar la nostra política d'ús, que prohibeix utilitzar els nostres models de maneres que puguin causar dany, com ara per generar contingut d'odi, assetjador o violent, per a campanyes polítiques o per generar programari maliciós.
Equips vermells i avaluacions. Avaluem cada nou model important per detectar riscos de seguretat i possibles danys socials, com ara biaixos i discriminació. Duem a terme red-teaming intern i extern, en què provem internament el model per identificar riscos i oferim accés anticipat a experts de diversos sectors perquè ajudin a examinar els sistemes per cartografiar i avaluar els riscos. Fem servir aquestes avaluacions per orientar encara més el desenvolupament i la millora dels nostres models i sistemes de seguretat, i publiquem públicament les nostres conclusions.
Sistemes de monitoratge de seguretat. Construïm i implementem sistemes de monitoratge que ajuden a detectar contingut no desitjat i complementen la revisió humana d'incidents específics. Quan aquests sistemes detecten una infracció de contingut, podem emprendre diverses accions, com ara negar-nos a respondre, marcar l'incident perquè el revisi una persona o, en casos extrems, suspendre un usuari. Els classificadors de contingut funcionen amb models de llenguatge ajustats finament i continuem investigant com augmentar-ne la cobertura, l'eficiència i la precisió, explorant més recentment l'ús de GPT‑4 per desenvolupar sistemes de moderació.
Eines per als usuaris. Desenvolupem documentació i eines per als nostres usuaris i per als desenvolupadors que creen aplicacions sobre els nostres models per capacitar-los perquè utilitzin la IA de manera segura. Abans de llançar nous sistemes d'avantguarda, publiquem un informe que descriu les capacitats del model o sistema, les limitacions i els àmbits d'ús apropiat i inapropiat (per exemple, les fitxes del model de GPT‑4(s'obre en una finestra nova) i GPT‑4V). Posem a disposició una API de Moderations(s'obre en una finestra nova) gratuïta perquè els usuaris puguin aplicar les seves pròpies polítiques d'ús. I publiquem recerca(s'obre en una finestra nova) sobre els nostres sistemes de seguretat.
Aprendre de la retroacció. Creiem que aprendre de la retroacció i respondre-hi és un component crític per construir sistemes d'IA segurs al llarg del temps i complir la nostra missió. Millorem contínuament els resultats dels nostres models, els sistemes de moderació i les polítiques d'ús a partir de les aportacions i comentaris dels usuaris. També mantenim converses contínues amb les parts interessades sobre l'adopció i l'adaptació més beneficioses de la tecnologia d'IA.
La intel·ligència artificial és una branca de la informàtica que té com a objectiu crear sistemes informàtics que puguin comportar-se d'una manera típicament associada amb la intel·ligència humana. Alguns exemples són el programari que pot jugar a jocs com els escacs, els cotxes que poden conduir-se sols i els xatbots que poden simular converses semblants a les humanes.
L'aprenentatge automàtic és un enfocament de la intel·ligència artificial en què els sistemes informàtics poden aprendre a dur a terme tasques a partir d'informació o experimentació, en lloc de ser programats pas a pas. Per exemple, un sistema d'aprenentatge automàtic podria aprendre a dibuixar una imatge d'un gat veient diferents imatges de gats i aprenent les característiques d'aquestes imatges, en lloc de rebre instruccions línia per línia sobre com són els gats. O bé, un sistema podria aprendre a jugar a un videojoc experimentant i rebent recompenses pels intents reeixits, en lloc de rebre les regles del joc i instruccions sobre com completar-lo.
Els models són programes informàtics que es desenvolupen mitjançant tècniques d'intel·ligència artificial i d'aprenentatge automàtic. Els models més comuns són programes que analitzen dades per fer prediccions futures basades en aquestes dades. Per exemple, es podria desenvolupar un model per analitzar compres històriques fetes per compradors amb la finalitat de recomanar compres a un comprador futur.
Els models fundacionals són models d'IA que es desenvolupen utilitzant grans quantitats de potència computacional per aprendre d'una gran quantitat de dades, amb l'objectiu de dur a terme una àmplia gamma de tasques relacionades amb aquestes dades. Per exemple, un model de llenguatge desenvolupat a partir d'una gran quantitat de text es pot utilitzar després per analitzar, escriure i respondre preguntes sobre text.
Els camps de la intel·ligència artificial i de l'aprenentatge automàtic avancen ràpidament, de manera que aquestes definicions continuaran evolucionant amb el temps.