Learning concepts with energy functions

We’ve developed an energy-based model(opens in a new window) that can quickly learn to identify and generate instances of concepts, such as near, above, between, closest, and furthest, expressed as sets of 2d points. Our model learns these concepts after only five demonstrations. We also show cross-domain transfer: we use concepts learned in a 2d particle environment to solve tasks on a 3-dimensional physics-based robot.
Many hallmarks of human intelligence, such as generalizing from limited experience, abstract reasoning and planning, analogical reasoning, creative problem solving, and capacity for language require the ability to consolidate experience into concepts, which act as basic building blocks of understanding and reasoning. Our technique enables agents to learn and extract concepts from tasks, then use these concepts to solve other tasks in various domains. For example, our model can use concepts learned in a two-dimensional particle environment to let it carry out the same task on a three-dimensional physics-based robotic environment—without retraining in the new environment.
This work uses energy functions to let our agents learn to classify and generate simple concepts, which they can use to solve tasks like navigating between two points in dissimilar environments. Examples of concepts include visual (“red” or “square”), spatial (“inside”, “on top of”), temporal (“slow”, “after”), social (“aggressive”, “helpful”) among others. These concepts, once learned, act as basic building blocks of agent’s understanding and reasoning, as shown in other research from DeepMind(opens in a new window) and Vicarious(opens in a new window).

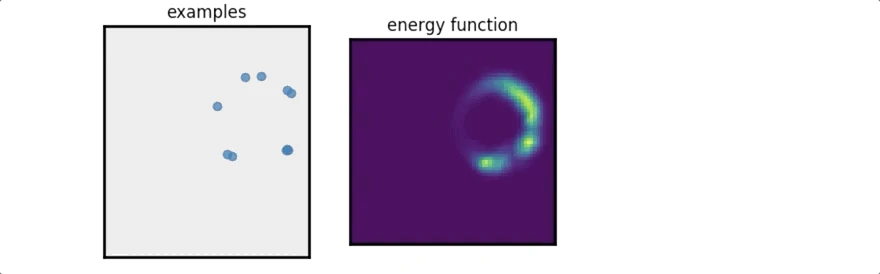
Energy functions let us build systems that can generate (left) and also identify (right) basic concepts, like the notion of a square.
Energy functions work by encoding a preference over states of the world, which allows an agent with different available actions (changing torque vs directly changing position) to learn a policy that works in different contexts—this roughly translates to the development of a conceptual understanding of simple things.
To create the energy function, we mathematically represent concepts as energy models(opens in a new window). The idea of energy models is rooted in physics, with the intuition that observed events and states represent low-energy configurations.
We define an energy function E(x, a, w) for each concept in terms of:
- The state of the world the model observes (x)
- An attention mask(opens in a new window) (a) over entities in that state.
- A continuous-valued vector (w), used as conditioning, that specifies the concept for which energy is being calculated
States of the world are composed of sets of entities and their properties and positions (like the dots below, which have both positional and colored properties). Attention masks, used for “identification”, represent a model’s focus on some set of entities. The energy model outputs a single positive number indicating whether the concept is satisfied (when energy is zero) or not (when energy is high). A concept is satisfied when an attention mask is focused on a set of entities that represent a concept, which requires both that the entities are in the correct positions (modification of x, or generation) and that the right entities are being focused on (modification of a, or identification).
We construct the energy function as a neural network based on the relational network architecture(opens in a new window), which allows it to take an arbitrary number of entities as input. The parameters of this energy function are what is being optimized by our training procedure; other functions are derived implicitly from the energy function.
This approach lets us use energy functions to learn a single network that can perform both generation and recognition. This allows us to cross-employ concepts learned from generation to identification, and vice versa. (Note: This effect is already observed in animals via mirror neurons(opens in a new window).)
Our training data is composed of trajectories of (attention mask, state), which we generate ahead of time for the specific concepts we’d like our model to learn. We train our model by giving it a set of demonstrations (typically 5) for a given concept set, and then give it a new environment (X0) and ask it to predict the next state (X1) and next attention mask (a). We optimize the energy function such that the next state and next attention mask found in the training data are assigned low energy values. Similar to generative models like variational autoencoders(opens in a new window), the model is incentivized to learn values that usefully compress aspects of the task. We trained our model using a variety of concepts involving, visual, spatial, proximal, and temporal relations, and quantification in a two-dimensional particle environment.
We evaluated our approach across a suite of tasks designed to see how well our single system could learn to identify and generate things united by the same concept; our system can learn to classify and generate specific sets of spatial relationships, or can navigate entities through a scene in a specific way, or can develop good judgements for concepts like quantity (one, two, three, or more than three) or proximity.
Models perform better when they can share experience between learning to generate concepts (by moving entities within the state vector x) and identify them (by changing the attention mask over a fixed state vector): when we evaluated models trained on both of these operations, they performed better on each single operation than models trained only on that single operation alone. We also discovered indications of transfer learning(opens in a new window)—an energy function trained only on a recognition context performs well on generation, even without being explicitly trained to do so.
In the future we’re excited to explore a wider variety of concepts learned in richer, three-dimensional environments, integrate concepts with the decision-making policies of our agents (we have so far only looked at concepts as things learned from passive experience), and explore connections between concepts and language understanding. If you are interested in this line of research, consider working at OpenAI!
Author
Acknowledgments
Thanks to those who contributed to this paper and blog post:
Blog post: Prafulla Dhariwal, Alex Nichol, Alec Radford, Yura Burda, Jack Clark, Greg Brockman, Ilya Sutskever, Ashley Pilipiszyn


