
Illustration: Ben Barry
We’re releasing highly-optimized GPU kernels for an underexplored class of neural network architectures: networks with block-sparse weights. Depending on the chosen sparsity, these kernels can run orders of magnitude faster than cuBLAS or cuSPARSE. We’ve used them to attain state-of-the-art results in text sentiment analysis and generative modeling of text and images.
The development of model architectures and algorithms in the field of deep learning is largely constrained by the availability of efficient GPU implementations of elementary operations. One issue has been the lack of an efficient GPU implementation for sparse linear operations, which we’re now releasing, together with initial results using them to implement a number of sparsity patterns. These initial results are promising but not definitive, and we invite the community to join us in pushing the limits of the architectures these kernels unlock.
Sparse weight matrices, as opposed to dense weight matrices, have a large number of entries with a value of exactly zero. Sparse weight matrices are attractive as building blocks of models, since the computational cost of matrix multiplication and convolution with sparse blocks is only proportional to the number of non-zero blocks. Sparsity enables, for example, training of neural networks that are much wider and deeper than otherwise possible with a given parameter budget and computational budget, such as LSTMs with tens of thousands of hidden units. (The largest LSTMs trained today are only thousands of hidden units.)

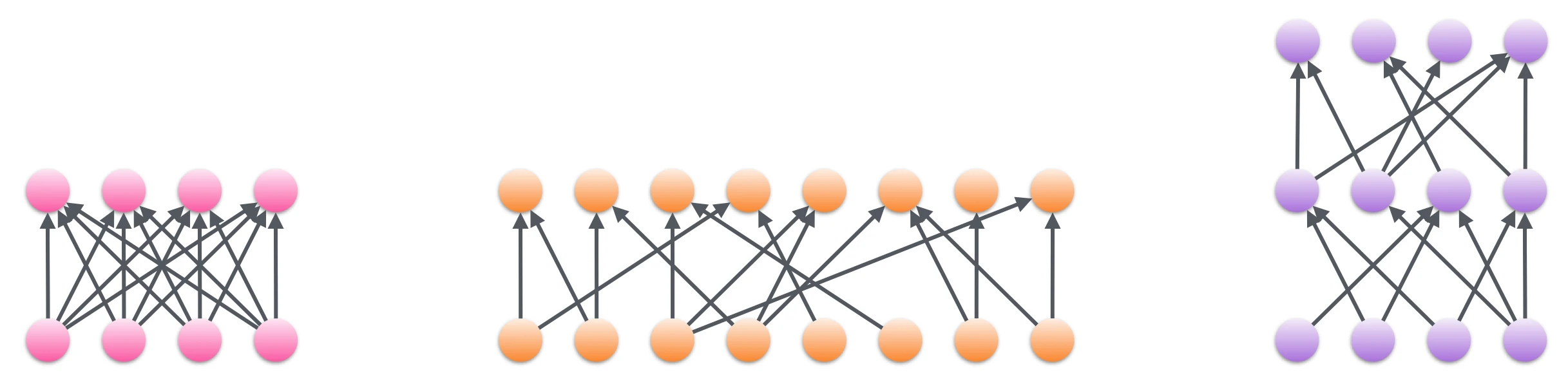
The kernels allow efficient usage of block-sparse weights in fully connected and convolutional layers (shown above). For convolutional layers, the kernels allow for sparsity in input and output feature dimensions; the connectivity is unaffected in the spatial dimensions. The sparsity is defined at the level of blocks (right figure above), and have been optimized for block sizes of 8x8 (such as in this example), 16x16 or 32x32. At the block level, the sparsity pattern is completely configurable. Since the kernels skip computations of blocks that are zero, the computational cost is only proportional to the number of non-zero weights, not the number of input/output features. The cost for storing the parameters is also only proportional to the number of non-zero weights.
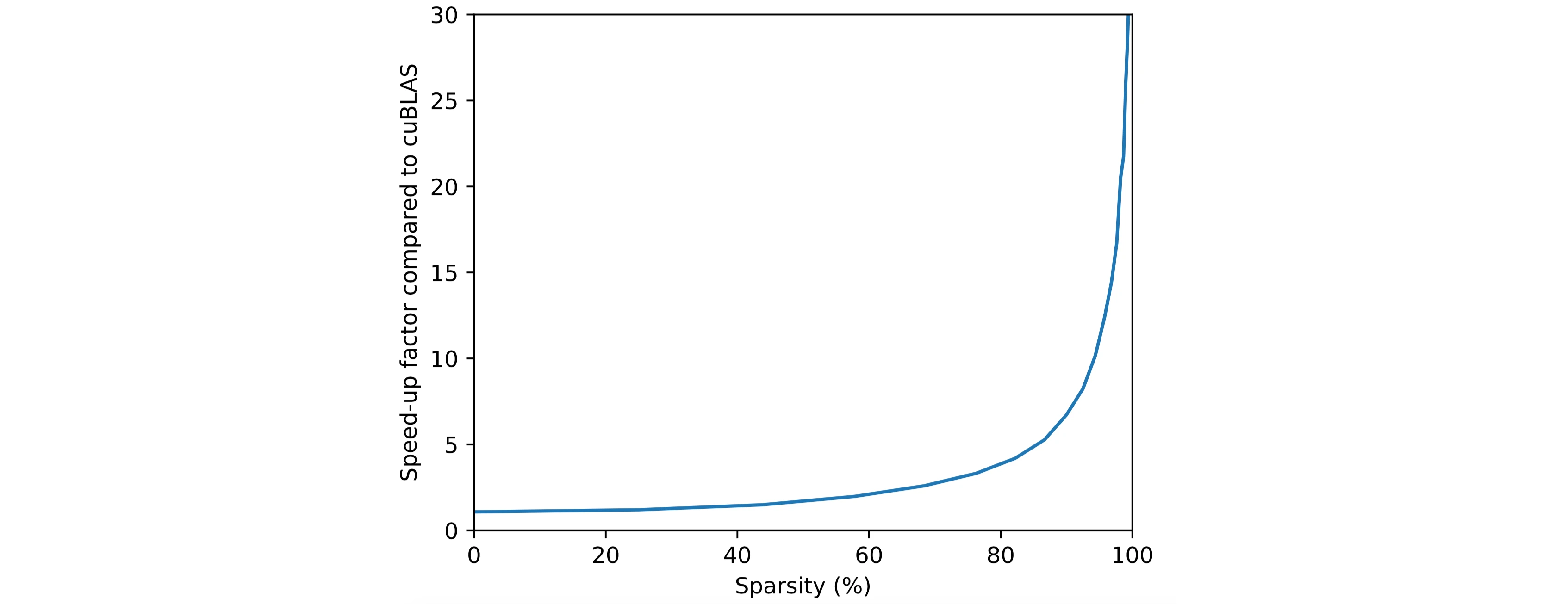
Speed-up factor for various levels of sparsity, compared to cuBLAS, when used with a wide state (12288 hidden units), block size of 32x32 and minibatch size of 32. Comparison was done on a NVIDIA Titan X Pascal GPU with CUDA 8. Speed-ups compared to cuSPARSE were even larger for the tested levels of sparsity.
Below we show some example code for performing sparse matrix multiplication in Tensorflow.
One particularly interesting use of block-sparse kernels is to use them to create small-world neural networks. Small-world graphs(opens in a new window) are connected in such a way that any two nodes in the graph are connected via a small number of steps, even if the graph has billions of nodes. Our motivation for implementing small world connectivity, is despite having a high degree of sparsity, we still want information to propagate quickly through the network. Brains display small-world connectivity patterns(opens in a new window), which prompts the question whether the same property can improve the performance of LSTMs. Using small-world sparse connectivity, we efficiently trained LSTMs with almost twenty thousands hidden units, 5 times wider than a dense network with similar parameter counts, improving results on generative modeling of text, and semi-supervised sentiment classification; see our paper(opens in a new window) for more details.

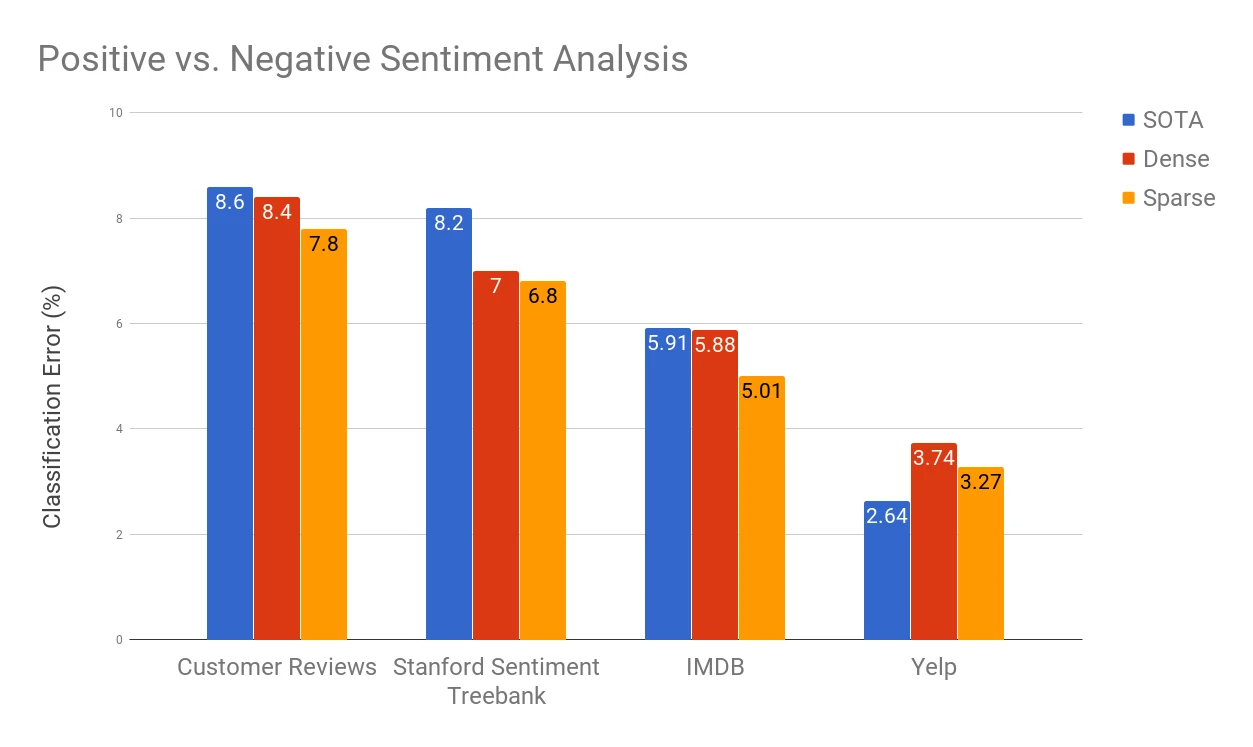
Following the setup we used in our sentiment neuron experiment, we trained LSTMs with approximately equivalent parameter counts and compared models with dense weight matrices against a block-sparse variant. The sparse model outperforms the dense model on all sentiment datasets. Our sparse model improves the state of the art on the document level IMDB dataset from 5.91% error (Miyato et al, 2016(opens in a new window)) to 5.01%. This is a promising improvement over our previous results which performed best only on shorter sentence level datasets.
By using sparse and wide LSTMs, the bits-per-character results in our experiments dropped from 1.059 to 1.048, for equal parameter counts (~ 100 million). Architectures with block-sparse linear layers can also improve upon results obtained with densely connected linear layers. We performed a simple modification of the PixelCNN++(opens in a new window) model of CIFAR-10 natural images. A replacement of regular 2D convolutional kernels with sparse kernels, while deepening the network but keeping the rest of the hyper-parameters fixed, lead to a drop in the bits-per-dimension from 2.92 to 2.90, now state of the art on this dataset.
Here we list some suggestions for future research.
- Most weights in neural networks can be pruned after training has finished(opens in a new window). How much wall-clock time speed-up is possible at inference time when using pruning together with these kernels?
- In biological brains, the sparse structure of the network is partially determined during development(opens in a new window), in addition to connection strengths. Can we do something similar in artificial neural networks, where we use gradients to not only learn the connection weights, but also the optimal sparsity structure? A recent paper proposed a method for learning block-sparse RNNs(opens in a new window), and we recently proposed an algorithm for L0 regularization in neural networks(opens in a new window), which can be used towards this end.
- We trained LSTMs with tens of thousands of hidden units, leading to better models of text. More generally, sparse layers make it possible to train models with huge weight matrices but the same number of parameters and the same computational cost as their smaller dense counterparts. What are application domains where this will make the most difference to performance?
Authors
Acknowledgments
Cover Artwork: Ben Barry


