Објашњење OpenAI технологије

OpenAI је основан као непрофитна организација 2015. године како би се обезбедило да општа вештачка интелигенција — укратко, AI која је бар подједнако паметна као човек — користи целом човечанству. Истражујемо, развијамо и објављујемо најсавременију AI технологију, као и алате и најбоље праксе за безбедност, усклађивање и управљање AI. OpenAI је и данас под управом наше непрофитне организације: нашу мисију стављамо испред профита, ограничавамо финансијске приносе запосленима и инвеститорима, а будуће профите изнад тог ограничења враћаћемо нашој непрофитној организацији. Ова јединствена корпоративна структура даје нам другачије подстицаје од других технолошких компанија. Наш циљ није да продамо што више било чега, већ да радимо ка свету у ком сви имају користи од друштвених, економских и технолошких могућности AI.
Као део мисије OpenAI, развијамо водеће основне моделе и њихове могућности стављамо на располагање на безбедне и корисне начине људима широм света(отвара се у новом прозору). Постоје два главна начина на која људи могу да приступе нашим моделима:
- ChatGPT је апликација која омогућава људима да комуницирају са нашим моделима на разговорни начин. Корисници могу од наших језичких модела тражити да анализирају или пишу текст или код, или од наших модела за слике тражити да цртају слике на основу текстуалног описа. ChatGPT је бесплатно доступан свим корисницима на chatgpt.com(отвара се у новом прозору). Корисници могу да се пријаве за премијум месечну претплату која омогућава додатне функције и могућности, а нудимо и пословну верзију коју компаније могу да купе.
- Наш API (Application Programming Interface) омогућава програмерима да интегришу могућности и предности наших модела у сопствене апликације. Хиљаде организација, укључујући Duolingo, Spotify и Morgan Stanley, граде нове функције, апликације и послове користећи наш API. Данска компанија Be My Eyes користи наш API да помогне слепим и слабовидим корисницима да отпреме слике и поставе питања о њима, што им помаже да се боље сналазе у физичком окружењу и стекну већу самосталност. Наш API је доступан на platform.openai.com(отвара се у новом прозору), а програмери плаћају приступ API-ју у складу са тим колико га користе.
ChatGPT и наш API стављамо на располагање уз опсежне мере безбедности, како је даље детаљније објашњено у наставку. Такође одређене моделе, као што су наш модел Whisper за претварање говора у текст и наш модел за разумевање слика под називом CLIP, стављамо на располагање као отворени код након процене потенцијалних ризика таквих објава.
Намеравамо да ChatGPT и даље буде бесплатно доступан и приход ћемо остваривати од корисника и компанија које одлуче да плаћају премијум услуге. С обзиром на високе трошкове развоја и пружања основних модела великог обима, наша организација није профитабилна и не очекује да ће бити профитабилна у блиској будућности — наш циљ и даље остаје да користи AI буду широко и безбедно доступне свету.
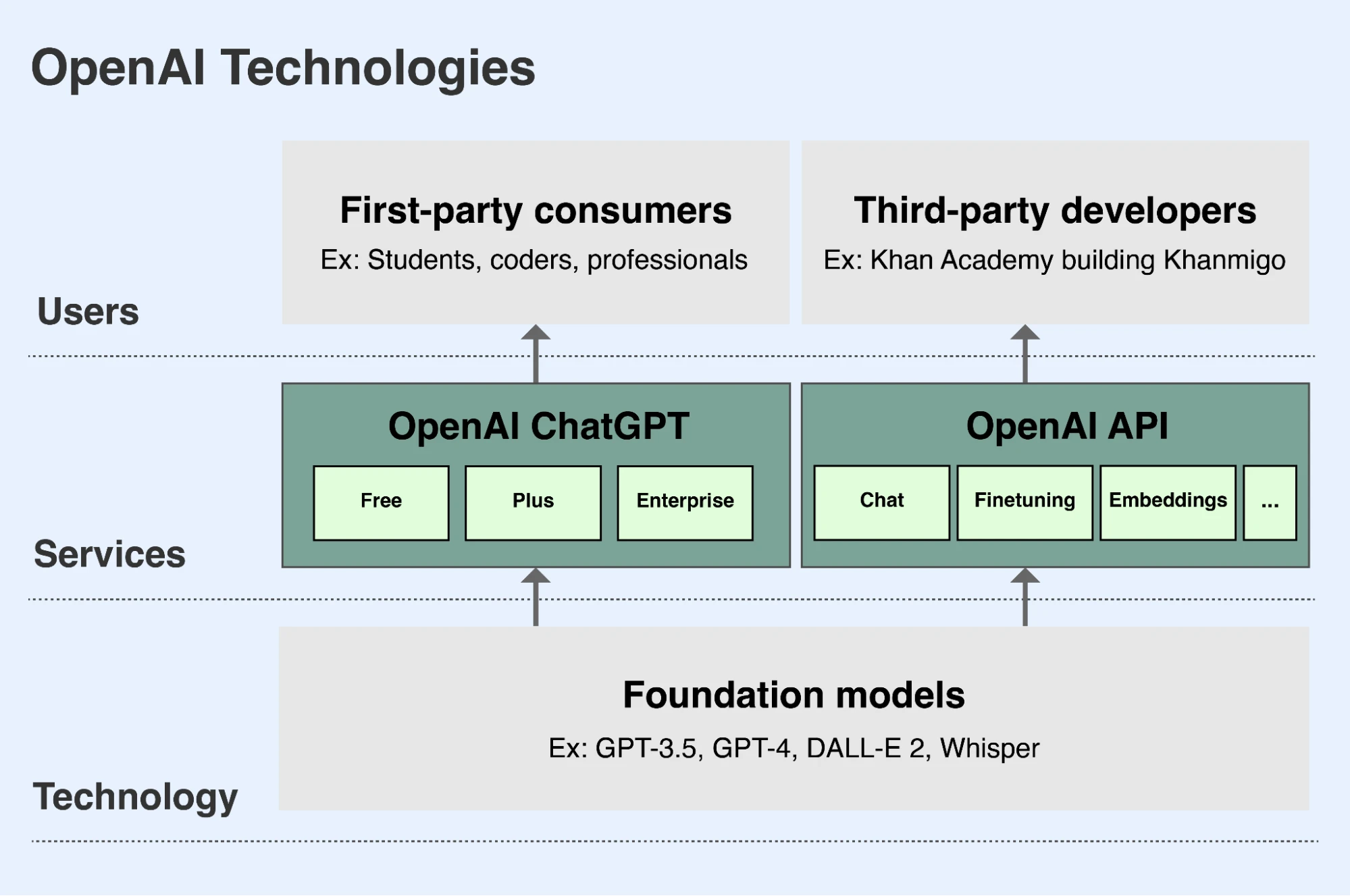
OpenAI приступ нашим водећим основним моделима првенствено омогућава преко ChatGPT‑а и нашег API-ја.
Развијање напредног језичког модела као што је GPT‑4 захтева (1) учење интелигенције, као што су способност предвиђања, расуђивања и решавања проблема, као и (2) усклађивање са људским вредностима и преференцијама. Прво се ради у процесу који се назива „предобука“, а који подразумева да се моделу током више месеци приказује огромна количина људског знања. Да бисмо затим у модел унели људски избор, користимо други корак, назван „постобука“, у ком модел чинимо безбеднијим и употребљивијим.
Предобука учи модел језику тако што му приказује широк спектар текста и наводи га да покуша да предвиди реч која следи у свакој од огромног броја секвенци. То захтева огромну количину рачунарске обраде, јер модели прегледају, анализирају и уче из билиона речи. Градимо суперрачунаре за обуку наших основних модела, а обука једног новог основног модела може да заузме суперрачунар месецима. Кроз овај опсежан процес, модел не учи само како се речи граматички уклапају, већ и како заједно формирају идеје вишег нивоа, и на крају како секвенце речи обликују структурисане мисли или постављају смислене проблеме. На пример, када помислимо на реч „облак“, можемо помислити и на сродне речи као што су „небо“ и „киша“; када добијемо реченицу као што је „Тајна среће је“, можемо помислити на различите филозофске идеје. Стицањем течности у предвиђању следеће речи, модел тако учи концепте и градивне елементе интелигенције.
Резултат овог процеса — основни модел — има изузетну способност да решава нове проблеме који нису виђени у његовим подацима за обуку, чак и на широком спектру језика. Међутим, сам основни модел још није спреман за употребу. Основни модели су моћни и флексибилни. Они су интелигентни и изненађујући, али нису нужно корисни или безбедни.
Са основним моделом није лако разговарати: На пример, ако затражите од основног модела GPT‑4 да „напише причу о принцези…“, он обично неће написати причу. Уместо тога, наставиће вашу изјаву, предвиђајући како се она наставља. Могао би, на пример, да испише: „…о принцези која воли коње.“ Основни модел такође нема заштитне мере које би га спречиле да генерише нежељени садржај, као што је материјал пун мржње или насиља. Иако филтрирамо наш скуп података за предобуку ради уклањања нежељеног садржаја, ова мера је сувише непрецизна да би омогућила циљане измене модела, а може чак и да има супротан ефекат ако спречи модел да разуме шта не треба да каже или уради. Да бисмо у моделе усадили људске вредности, укључујући шта је корисно и шта је примерено рећи, истражујемо и развијамо технике усклађивања и безбедности за процес који називамо постобука.
Постобука је начин на који уносимо људски избор у наше моделе и претварамо их у корисне, ефикасне и безбедније алате. Учимо модел да одговара на начине које људи сматрају кориснијим и да одбије да одговори на начине за које верујемо да би били штетни. Постобука захтева значајна улагања у истраживање, људство, дизајнерске одлуке и креирање података. Ово је активно поље истраживања и улагања за OpenAI. Такође верујемо да ће многи људи ван наше компаније бити део рада на креирању података и доношењу дизајнерских одлука које одражавају људске вредности.
Постобука доводи до циљаних промена у моделу, користећи релативно мале и пажљиво осмишљене скупове података који представљају идеално понашање. То радимо тако што људи пишу примерне одговоре и оцењују одговоре које је дао модел, а затим те примере и оцене враћамо моделу у накнадним процесима обуке. Били смо пионири ових техника, укључујући подстицајно учење из повратних информација од људи (RLHF), које је сада постало индустријски стандард. Користимо RLHF да научимо модел да прати упутства, да смањимо вероватноћу да враћа нетачан садржај и да додамо безбедносне функције.
Пре јавног објављивања GPT‑4, провели смо 6 месеци унапређујући постобуку. Током тог времена развили смо технике да наше моделе научимо да одбију одговор на захтеве за које верујемо да могу довести до потенцијалне штете. На пример, ако се од модела затраже упутства за прављење бомбе, он ће одбити да одговори. Према нашим интерним евалуацијама, учинили смо GPT‑4 за 82% мање склоним да одговара на захтеве за недозвољени садржај у поређењу са моделом претходне генерације GPT‑3.5. Ово време смо искористили и да повећамо вероватноћу да даје чињеничне одговоре за 40%, научимо га да одговара разговорним тоном и побољшамо његове перформансе на језицима са мање ресурса, на пример у партнерству са Исландом.
Настављамо да развијамо технике постобуке(отвара се у новом прозору) како би наши модели боље одражавали људски избор. На пример, неки од наших приступа омогућавају људима да опишу правила која систем треба да прати, уместо да морају да оцењују примере бољег или лошијег понашања.
Поред постобуке коју сами спроводимо, клијентима нудимо и могућност да „фино подесе“ наше моделе како би остварили своје специфичне циљеве, као што су писање софтверског кода на њиховим власничким језицима, подучавање модела знању специфичном за одређену индустрију или усклађивање његовог тона са њиховим брендом. Клијенти то раде тако што припремају податке који показују понашање које желе да постигну и шаљу их за додатну постобуку путем нашег API-ја. Под претпоставком да подаци прођу наше безбедносне провере, резултујући фино подешени модел стављамо на располагање искључиво том клијенту. Слично другом API саобраћају, користимо наше системе надзора и откривања описане у наставку како бисмо помогли у откривању да ли фино подешени модели крше наше политике коришћења.
Поред безбедности која се постиже постобуком, спроводимо ригорозно тестирање, укључујемо спољне стручњаке ради повратних информација, градимо и јачамо системе безбедности и надзора и пружамо ресурсе који помажу људима да наше моделе користе одговорно. Овај холистички приступ безбедности нам омогућава да применимо и спроводимо нашу политику коришћења која забрањује употребу наших модела на начине који могу изазвати штету, као што су генерисање садржаја пуног мржње, узнемиравајућег или насилног садржаја, политичке кампање или генерисање злонамерног софтвера.
Ред тиминг и евалуације. Сваки велики нови модел процењујемо у погледу безбедносних ризика и потенцијалних друштвених штета као што су пристрасност и дискриминација. Спроводимо интерни и екстерни ред тиминг, где модел интерно тестирамо на ризике и стручњацима из различитих индустрија пружамо рани приступ како би помогли у испитивању система ради мапирања и процене ризика. Ове евалуације користимо да бисмо даље усмеравали развој и унапређење наших модела и безбедносних система, а своје налазе објављујемо јавно.
Системи за безбедносни надзор. Градимо и примењујемо системе надзора који помажу у откривању нежељеног садржаја и допуњују људски преглед конкретних инцидената. Када ови системи открију кршење правила о садржају, можемо предузети различите радње, укључујући одбијање одговора, означавање инцидента за људски преглед или, у екстремним случајевима, суспензију корисника. Класификатори садржаја покрећу се фино подешеним језичким моделима, а настављамо да истражујемо како да повећамо њихову покривеност, ефикасност и тачност, недавно истражујући употребу GPT‑4 за развој система модерације.
Алати за кориснике. Развијамо документацију и алате за наше кориснике и програмере који праве апликације на нашим моделима, како бисмо их оснажили да безбедно користе AI. Пре објављивања нових граничних система, објављујемо извештај који описује могућности модела или система, ограничења и домене примерене и непримерене употребе (на пример, системске картице за GPT‑4(отвара се у новом прозору) и GPT‑4V). Стављамо на располагање бесплатан Moderations API(отвара се у новом прозору) како би корисници могли да спроводе сопствене политике коришћења. И објављујемо истраживања(отвара се у новом прозору) о нашим безбедносним системима.
Учење из повратних информација. Верујемо да су учење из повратних информација и реаговање на њих кључна компонента изградње безбедних AI система током времена и остваривања наше мисије. Непрестано унапређујемо излазе наших модела, системе модерације и политике коришћења на основу уноса и повратних информација корисника. Такође водимо сталне разговоре са заинтересованим странама о најкориснијем усвајању и прилагођавању AI технологији.
Вештачка интелигенција је грана рачунарских наука чији је циљ стварање рачунарских система који могу да се понашају на начин који се обично повезује са људском интелигенцијом. Примери укључују софтвер који може да игра игре као што је шах, аутомобиле који могу сами да возе и четботове који могу да симулирају разговор налик људском.
Машинско учење је приступ вештачкој интелигенцији у ком рачунарски системи могу да науче да обављају задатке на основу информација или експериментисања, уместо да буду програмирани корак по корак. На пример, систем машинског учења могао би да научи да нацрта слику мачке тако што би посматрао различите слике мачака и учио карактеристике тих слика, уместо да му се дају упутства ред по ред о томе како мачке изгледају. Или би систем могао да научи да игра видео-игру кроз експериментисање и награђивање за успешне покушаје, уместо да му буду дати правила игре и упутства како да је заврши.
Модели су рачунарски програми који се развијају помоћу техника вештачке интелигенције и машинског учења. Најчешћи модели су програми који анализирају податке како би на основу њих правили будућа предвиђања. На пример, модел може бити развијен да анализира историјске куповине купаца како би препоручио куповине неком будућем купцу.
Основни модели су AI модели који се развијају коришћењем велике количине рачунарске снаге како би учили из велике количине података, да би могли да обављају широк спектар задатака повезаних са тим подацима. На пример, језички модел који је развијен коришћењем велике количине текста може се затим користити за анализу, писање и одговарање на питања о тексту.
Области вештачке интелигенције и машинског учења брзо напредују, тако да ће ове дефиниције наставити да се мењају током времена.