Teknologi OpenAI dijelasake

OpenAI didegake minangka organisasi nirlaba ing 2015 kanggo mesthekake manawa kecerdhasan umum tiruan—cekake, AI sing paling ora pinter kaya manungsa—menehi manfaat kanggo kabeh umat manungsa. Kita neliti, ngembangake, lan ngeculake teknologi AI paling anyar uga piranti lan praktik paling apik kanggo safety, alignment, lan tata kelola AI. OpenAI nganti saiki isih dipimpin dening organisasi nirlaba kita: Kita ngutamakake misi tinimbang bathi, kita mbatesi asil finansial kanggo karyawan lan investor, lan bathi ing mangsa ngarep sing ngluwihi wates bakal dibalekake menyang organisasi nirlaba kita. Struktur perusahaan sing unik iki menehi insentif sing beda tinimbang perusahaan teknologi liyane. Tujuan kita dudu adol sing paling akèh saka apa wae, nanging ngupaya donya sing saben wong entuk manfaat saka kesempatan sosial, ekonomi, lan teknologi saka AI.
Minangka bagéan saka misi OpenAI, kita ngembangake model dhasar sing mimpin lan nggawe kapabilitase kasedhiya kanthi cara sing aman lan migunani kanggo wong ing saindenging jagad(mbukak ing jendhela anyar). Ana rong cara utama wong bisa ngakses model kita:
- ChatGPT yaiku aplikasi sing ngidini wong sesambungan karo model kita kanthi cara pacelathon. Pangguna bisa njaluk model basa kita kanggo nganalisis utawa nulis teks utawa kode, utawa njaluk model gambar kita nggambar gambar adhedhasar deskripsi teks. ChatGPT kasedhiya gratis kanggo kabeh pangguna ing chatgpt.com(mbukak ing jendhela anyar). Pangguna bisa ndhaptar langganan premium saben wulan sing marakake fitur lan kapabilitas tambahan kasedhiya, lan kita uga nawakake versi enterprise kanggo dituku bisnis.
- API kita (Application Programming Interface) ngidini pangembang nggabungake kapabilitas lan manfaat model kita menyang aplikasi dhewe. Ewonan organisasi kalebu Duolingo, Spotify, lan Morgan Stanley lagi mbangun fitur, aplikasi, lan bisnis anyar nggunakake API kita. Perusahaan Denmark jenenge Be My Eyes nggunakake API kita kanggo mbantu pangguna wuta lan sing sesanti kurang ngunggah lan takon babagan gambar, mbantu dheweke luwih apik ngarahake lingkungan fisik lan dadi luwih mandiri. API kita kasedhiya ing platform.openai.com(mbukak ing jendhela anyar) lan pangembang mbayar akses API adhedhasar sepira akèh panggunaane.
Kita nyedhiyakake ChatGPT lan API kita bebarengan karo langkah safety sing jembar, kaya diterangake luwih rinci ing ngisor iki. Kita uga nggawe sawatara model, kayata model wicara-menyang-teks Whisper lan model pemahaman gambar kita sing diarani CLIP, kasedhiya kanthi basis open source sawisé ngevaluasi risiko potensial saka rilis kaya mangkono.
Kita arep terus nyedhiyakake ChatGPT kanthi gratis lan bakal entuk penghasilan saka pangguna lan bisnis sing milih mbayar layanan premium. Amarga biaya ngembangake lan nawakake model dhasar skala gedhe dhuwur, organisasi kita durung bathi lan ora ngarepake bakal bathi ing wektu cedhak—tujuan kita tetep supaya manfaat AI kasedhiya kanthi amba lan aman kanggo donya.
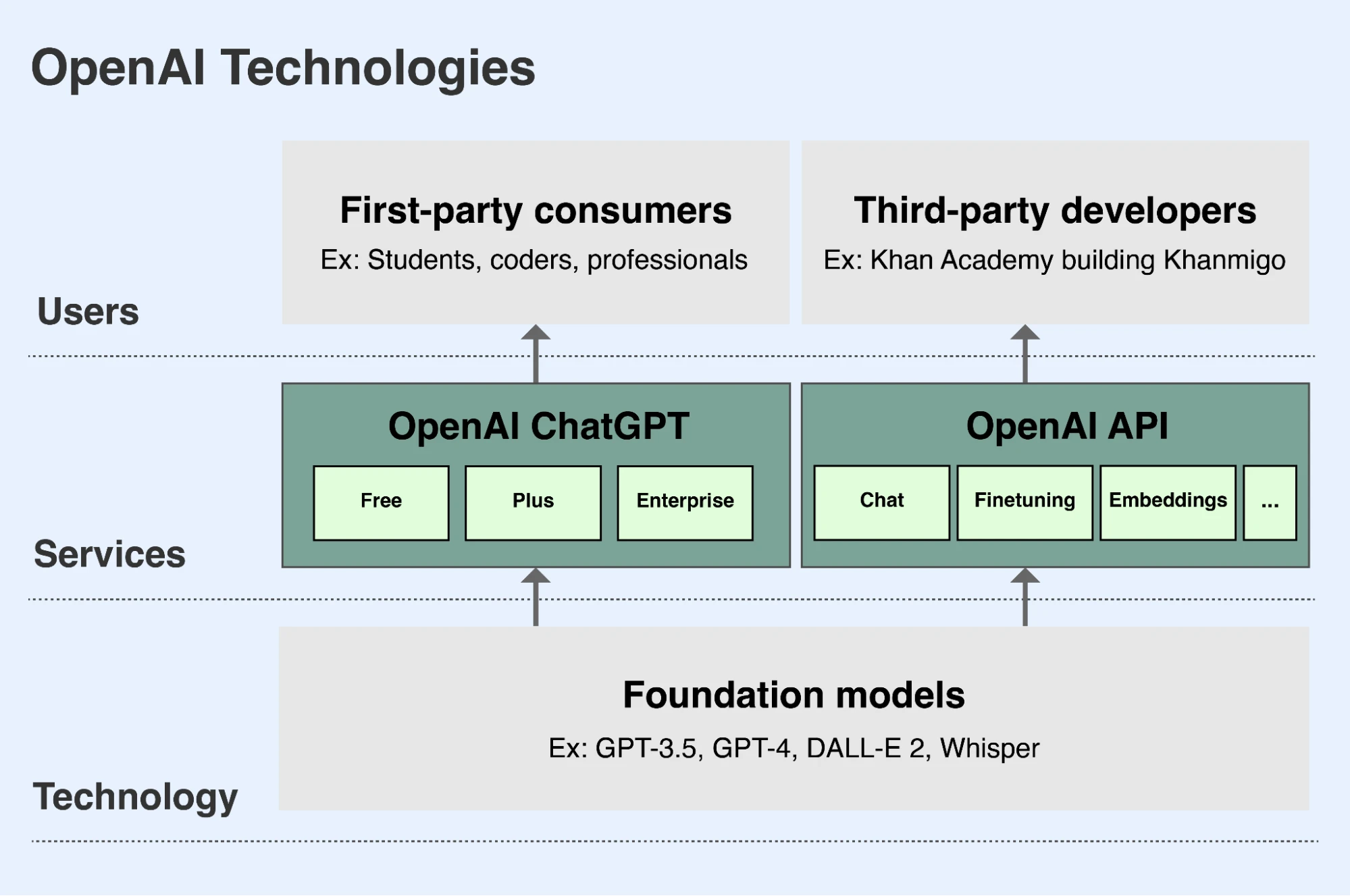
OpenAI nyedhiyakake akses menyang model dhasar unggulan kita utamane liwat ChatGPT lan API kita.
Ngembangake model basa majeng kaya GPT‑4 mbutuhake (1) mulang kecerdhasan marang model, kayata kemampuan kanggo prédhiksi, nalar, lan ngrampungake masalah, uga (2) nyelarasake karo nilai lan preferensi manungsa. Sing kapisan ditindakake ing proses sing diarani “latihan awalan”, yaiku kanthi nuduhake model kawruh manungsa sing gedhe banget sajrone pirang-pirang wulan. Banjur kanggo nggabungake pilihan manungsa menyang model, kita nggunakake langkah kapindho, yaiku “post-training”, ing ngendi kita nggawe model luwih aman lan luwih migunani.
Latihan awalan mulangake basa marang model, kanthi nuduhake model manéka warna teks, lan njaluk model nyoba prédhiksi tembung sabanjure ing saben urutan saka akèh banget urutan. Iki mbutuhake komputasi sing gedhe banget, amarga model mriksa, nganalisis, lan sinau saka triliunan tembung. Kita mbangun superkomputer kanggo nglatih model dhasar, lan nglatih siji model dhasar anyar bisa nggunakke superkomputer nganti pirang-pirang wulan. Liwat proses sing jembar iki, model ora mung sinau carane tembung-tembung cocog bebarengan miturut tata basa, nanging uga carane tembung-tembung bebarengan mbentuk gagasan tingkat luwih dhuwur, lan pungkasane carane urutan tembung mbentuk pikiran sing terstruktur utawa ngandharake masalah sing runtut. Contone, nalika mikir tembung “awan”, kita bisa uga mikir tembung sing gegandhengan kaya “langit” lan “udan”; nalika diwenehi ukara kaya “Rahasia kebahagiaan yaiku”, kita bisa uga mikir macem-macem gagasan filosofis. Nalika saya lancar prédhiksi tembung sabanjure, model kanthi mangkono sinau konsep lan blok panyusun kecerdhasan.
Asil saka proses iki—yaiku model dhasar—duwé kemampuan luar biasa kanggo ngrampungake masalah anyar sing ora katon ing data latihane, malah ing manéka basa. Nanging, model dhasar waé durung siap digunakake. Model dhasar kuwat lan fleksibel. Model iki cerdas lan asring ngagetake, nanging durung mesthi migunani utawa aman.
Model dhasar ora gampang diajak ngobrol: Contone, yen sampeyan njaluk model dhasar GPT‑4 kanggo “nulis crita bab sawijining putri…”, biasane model iki ora bakal nulis crita. Nanging, model bakal nerusake pernyataan sampeyan, kanthi prédhiksi kepiye ukara kuwi diterusake. Bisa waé metu kaya mangkene: “…bab sawijining putri sing seneng jaran.” Model dhasar uga ora nduwèni pengaman kanggo nyegah supaya ora ngasilake konten sing ora dikarepake, kayata materi sengit utawa kasar. Sanadyan kita nyaring dataset latihan awalan kanggo konten sing ora dikarepake, mitigasi iki kurang presisi kanggo nggawe owah-owahan sing ditargetake ing model, lan malah bisa dadi mbalela yen nyegah model ngerti apa sing ora kena diucapake utawa ditindakake. Kanggo nandurake nilai manungsa menyang model, kalebu apa sing migunani lan apa sing pantes diucapake, kita neliti lan ngembangake teknik alignment lan safety kanggo proses sing kita sebut post-training.
Post-training yaiku cara kita nggabungake pilihan manungsa menyang model kita, lan ngowahi dadi piranti sing migunani, efektif, lan luwih aman. Kita mulang model supaya nanggapi kanthi cara sing dirasa wong luwih migunani, lan nolak nanggapi kanthi cara sing miturut kita bisa mbebayani. Post-training mbutuhake investasi gedhe ing riset, personel, pilihan desain, lan nggawe data. Iki minangka wilayah riset lan investasi sing aktif kanggo OpenAI. Kita uga pracaya manawa akeh wong ing njaba perusahaan kita bakal dadi bagéan saka gaweyan nggawe data lan nggawe keputusan desain kanggo nggambarake nilai manungsa.
Post-training ngasilake owah-owahan sing ditargetake marang model, nggunakake dataset sing relatif cilik lan direkayasa kanthi tliti sing makili prilaku ideal. Kita nindakake iki kanthi njaluk wong nulis conto jawaban lan menehi rating marang jawaban sing diwenehake model, banjur menehi conto lan rating kasebut bali menyang model ing proses latihan tindak lanjut. Kita dadi pelopor teknik-teknik iki, kalebu Sinau Penguatan saka Umpan Balik Manungsa (RLHF), sing saiki wis dadi standar industri. Kita nggunakake RLHF kanggo mulang model nuruti instruksi, nyuda kemungkinan model mbalekake konten sing ora akurat, lan nambah fitur safety.
Sadurunge ngeculake GPT‑4 kanggo umum, kita ngentekake 6 wulan kanggo ngiterasi post-training. Sajrone wektu iki, kita ngembangake teknik kanggo mulang model kita supaya nolak nanggapi panjaluk sing miturut kita bisa nyebabake bebaya. Contone, yen dijaluk pandhuan carane nggawe bom, model bakal nolak nanggapi. Adhedhasar evaluasi internal, kita nggawe GPT‑4 82% luwih sithik kamungkinan nanggapi panjaluk kanggo konten sing ora diidinake dibandhingake model generasi sadurunge GPT‑3.5. Kita uga nggunakake wektu iki kanggo nambah kemungkinan supaya model ngasilake tanggapan faktual nganti 40%, mulang supaya nanggapi kanthi cara pacelathon, lan ningkatake kinerjane ing basa sing sumber dayane sithik, contone ing kemitraan karo Islandia.
Kita terus ngembangake teknik post-training(mbukak ing jendhela anyar) supaya luwih nggambarake pilihan manungsa ing model kita. Contone, sawetara pendekatan kita maringi daya marang wong kanggo njlentrehake aturan sing kudu dituruti sistem, tinimbang kudu menehi nilai conto prilaku sing luwih apik utawa luwih ala.
Saliyane post-training sing kita lakoni dhewe, kita uga nawakake marang pelanggan kemampuan kanggo “fine-tune” model kita supaya bisa ngrampungake tujuan khususé, kayata nulis kode piranti lunak nganggo basa proprietary, mulang kawruh khusus industri, utawa nyelarasake nadane karo merek. Pelanggan nindakake iki kanthi nyiapake data sing nduduhake prilaku sing pengin digayuh lan ngirimake kanggo post-training tambahan liwat API kita. Yen data kasebut lolos pamriksan safety kita, kita banjur nyedhiyakake model asil fine-tune kasebut mung kanggo pelanggan kasebut. Kaya lalu lintas API liyane, kita nggunakake sistem pemantauan lan deteksi sing diterangake ing ngisor iki kanggo mbantu ndeteksi yen model fine-tune nglanggar kabijakan panggunaan kita.
Saliyane safety liwat post-training, kita nindakake pengujian sing ketat, melu ahli eksternal kanggo njaluk umpan balik, mbangun lan nguwatake sistem safety lan pemantauan, lan nyedhiyakake sumber daya kanggo mbantu wong nggunakake model kita kanthi tanggung jawab. Pendekatan safety sing holistik iki ndadekake kita bisa nerapake lan ngleksanakake kabijakan panggunaan kita sing nglarang nggunakake model kita kanthi cara sing bisa nyebabake cilaka, kayata kanggo ngasilake konten sengit, ngganggu, utawa kasar, kanggo kampanye politik, utawa kanggo nggawe malware.
Red-teaming lan evaluasi. Kita ngevaluasi saben model utama anyar kanggo risiko safety lan potensi cilaka sosial kaya bias lan diskriminasi. Kita nindakake red-teaming internal lan eksternal, yaiku nalika kita nguji model kanggo risiko sacara internal lan menehi akses awal marang para ahli saka manéka industri kanggo mbantu nguji sistem supaya bisa memetakan lan ngevaluasi risiko. Kita nggunakake evaluasi iki kanggo luwih nuntun pangembangan lan panyempurnaan model lan sistem safety kita, lan nerbitake temuan kita kanggo umum.
Sistem pemantauan safety. Kita mbangun lan nerapake sistem pemantauan sing mbantu ndeteksi konten sing ora dikarepake lan nglengkapi tinjauan manungsa marang insiden tartamtu. Nalika pelanggaran konten dideteksi dening sistem iki, kita bisa njupuk manéka tumindak kalebu nolak nanggapi, nandhai insiden kanggo tinjauan manungsa, utawa ing kasus ekstrem, nundha pangguna. Klasifier konten didhukung dening model basa fine-tune lan kita terus neliti carane nambah cakupan, efisiensi, lan akurasine, sing paling anyar njajaki panggunaan GPT‑4 kanggo ngembangake sistem moderasi.
Piranti kanggo pangguna. Kita ngembangake dokumentasi lan piranti kanggo pangguna kita lan pangembang sing mbangun aplikasi ing ndhuwur model kita supaya bisa nggunakake AI kanthi aman. Sadurunge ngeculake sistem tercanggih anyar, kita nerbitake laporan sing njlentrehake kapabilitas model utawa sistem, keterbatasan, lan domain panggunaan sing cocog lan ora cocog (contone, kertu sistem kanggo GPT‑4(mbukak ing jendhela anyar) lan GPT‑4V). Kita nyedhiyakake Moderations API(mbukak ing jendhela anyar) gratis supaya pangguna bisa ngetrapake kabijakan panggunaan dhewe. Lan kita nerbitake riset(mbukak ing jendhela anyar) babagan sistem safety kita.
Sinau saka umpan balik. Kita pracaya yen sinau saka lan nanggapi umpan balik iku komponen kritis kanggo mbangun sistem AI aman saka wektu ke wektu lan netepi misi kita. Kita terus ningkatake output model, sistem moderasi, lan kabijakan panggunaan adhedhasar masukan lan umpan balik pangguna. Kita uga melu pacelathon terus-terusan karo para pemangku kepentingan babagan cara adopsi lan adaptasi teknologi AI sing paling migunani.
Kecerdhasan buatan yaiku cabang ilmu komputer sing tujuane nggawe sistem komputasi sing bisa tumindak kanthi cara sing biasane digandhengake karo kecerdhasan manungsa. Contone kalebu piranti lunak sing bisa main game kaya catur, mobil sing bisa nyopir dhewe, lan chatbot sing bisa nyimulasi pacelathon kaya manungsa.
Sinau mesin yaiku pendekatan marang kecerdhasan buatan sing ngidini sistem komputer sinau ngrampungake tugas adhedhasar informasi utawa eksperimen, tinimbang diprogram langkah demi langkah. Contone, sistem sinau mesin bisa sinau nggambar kucing kanthi ndeleng macem-macem gambar kucing lan sinau ciri-ciri saka gambar kasebut, tinimbang diwenehi pandhuan baris demi baris babagan rupane kucing. Utawa, sistem bisa sinau main game video kanthi nyoba-nyoba lan nampa ganjaran kanggo upaya sing kasil, tinimbang diwenehi aturan game lan pandhuan carane ngrampungake game kasebut.
Model yaiku program komputer sing dikembangake nganggo teknik kecerdhasan buatan lan sinau mesin. Model sing paling umum yaiku program sing nganalisis data kanggo nggawe predhiksi mangsa ngarep adhedhasar data kasebut. Contone, sawijining model bisa dikembangake kanggo nganalisis tumbas sajarah sing ditindakake para panuku supaya bisa menehi rekomendasi tumbas marang panuku ing mangsa ngarep.
Model dhasar yaiku model AI sing dikembangake nganggo daya komputasi gedhe kanggo sinau saka data sing akèh, supaya bisa nindakake manéka tugas sing gegandhengan karo data kasebut. Contone, model basa sing dikembangake nganggo teks sing akèh banjur bisa digunakake kanggo nganalisis, nulis, lan mangsuli pitakon babagan teks.
Bidang kecerdhasan buatan lan sinau mesin maju kanthi cepet, mula definisi-definisi iki bakal terus owah saka wektu ke wektu.